Hi,
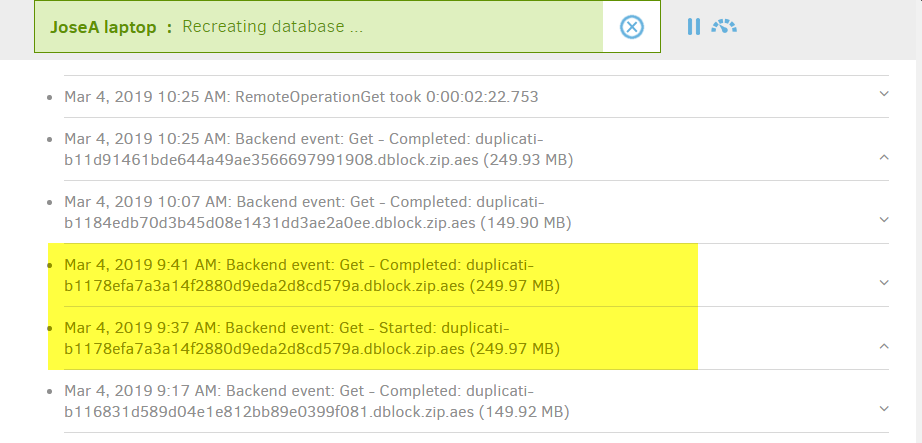
So I am also having issues with the recreate database feature. I triggered the recreate as part of my assessment of the software. It is taking forever (+5 days and I do not think it is close to finish).
From the log it looks like it is downloading all the dblock files. I hope it is not.
Is there a place where the logic this is applying is documented? I couldn’t find it.
I am trying to make sense of the files in the storage folder. I am guessing that the dlist one is created when a backup session completes, and it contains a list of of dblock/dbindex/files or similar.
The dindex/dblock files seem to be in pairs, though, they do not share the same hex hash in the name (I think they are in pairs because of the datetime is the same). Some images to show what I am talking about.
The recreate process is downloading dblock files that seem to have a dindex file. See images.
That’s what is really puzzling me. Per the other entries I have read, the dblock files should only be downloaded if the dindex file is missing. Well… I have 1938 dblock and 1938 bindex files in my storage. I do not think any of my dindex files are missing. Why is this downloading the dblock files?
Please advise. thanks.

Technical details:
I am running Duplicati - 2.0.4.15_canary_2019-02-06 on Windows 10 (x64). My target storage is Minio S3 (hosted in the remotely). I have been heavily testing it for +1 month now.
I went ahead and created a backup selection of about 500Gb and +100k files. For the initial backups I used a block size of 150mb I changed the block size to 256mb.
My storage folder has 3881 files, dbindex, dblock (in pairs), and some dlist ones (I only have 5).
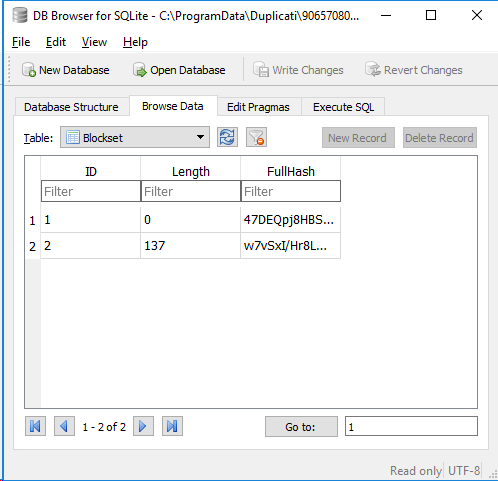
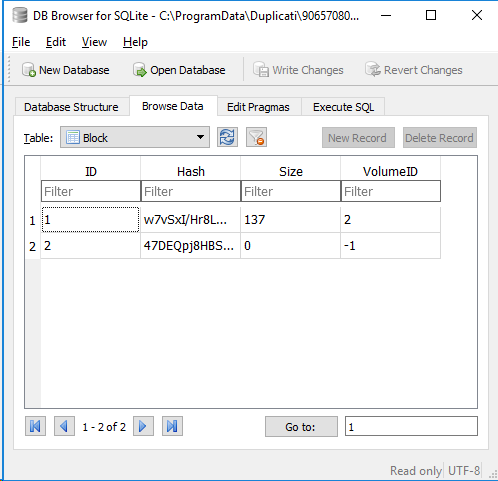
 .
.