I already checked several threads regarding this issue but it seems like none matches mine.
The instance on my home server is slowly filling up my drive. I use Duplicati in Docker.
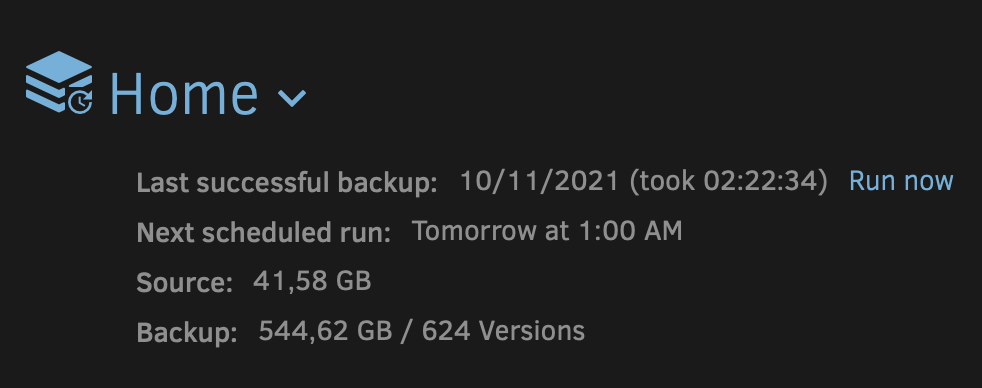
The Duplicati config directory uses 141GB with just 2 Backup Plans and the file dates are even from 2020 and 2019.
The version is 2.0.6.3_beta_2021-06-17.
And I even added auto-cleanup to each plan without any success.
Files ending in <date>.sqlite are probably automatic backups when Duplicati upgrades the DB format.
Old ones go stale very quickly, assuming the backup for them is still running, and they can be deleted.
You can probably also use ls -lurt on the folder to check last read times, to confirm no current use:
Did it make things worse? I wonder if that’s what’s making files ending in backup or backup-<number>?
Do you run backup in GUI? If so, do you get clean runs without popup warnings, errors, or complaints?
You can see About → Show log → Live → Information at start of backup. Maybe you’ll see above lines.
How many backup jobs do you currently run, or care about? You can look up their Local database path.
Be sure to keep those. I see only two seemingly active. Was OXPKYFAMWC job deleted very recently?
88787068678977808683.sqlite would be one created from an older release, maybe 2.0.4.5 or 2.0.4.23.
I’m not sure how it managed to make a .backup version of the same timestamp and far greater size…
thank you and thanks for reply. I haven’t seen that auto-cleanup made it much worse the last days I tested it.
Sadly my Backups have often Errors due to cloud upload limit, 403.
But tbh yesterday I exported the 2 backup plans and deleted the whole Duplicati folder, restarted it and imported the backup plans again. I’ll check soon how the database recreation went and if a backup is possible and how large the folder is now.
Well after several tries of repair and delete-restore I can’t get the backup working again.
Duplicati.Library.Interface.UserInformationException: The database was attempted repaired, but the repair did not complete. This database may be incomplete and the backup process cannot continue. You may delete the local database and attempt to repair it again.
Duplicati.Library.Interface.UserInformationException: Recreated database has missing blocks and 6 broken filelists. Consider using “list-broken-files” and “purge-broken-files” to purge broken data from the remote store and the database.
I started the purge about 12 hours ago and the status in the header is still
Retries of what? Do you mean you get enough file transfer errors to need higher number-of-retries?
Do you mean you ran Recreate multiple times manually, and this is the first one that said anything?
Did you also do list-broken-files to see what purge-broken-files would do. Can you generally describe?
The wrong “Starting” message for what you’re doing seems a standard bug. My guess on that is here to:
PS: It’s a bit confusing that when you start a “repair” it says “Starting backup”…
While there are tempting status outputs from purge, I think this is purge command not purge-broken-files:
One can compare sources and look for the UpdatePhase lines.
Yours does do some Logging.Log lines. Does About → Show log → Live → Information show activity?
How big and active are these, and where are they going? At Google Drive, 403 is at 750 GB daily upload (however it also does 403 at other random times for no reason that anybody has been able to figure out).
Those are typically shown via a popup and regular job logs. The other is in server log. You have to check. Combine logs in GUI #1152 is an enhancement request to resolve the weird where-are-the-logs chasing.
If you’re looking and actually getting varying results and messages (all places) from Recreate, that’s odd.
That’s a lot. I hope you increased your blocksize from default 100 KB, or some things may get quite slow.
You can try Profiling level for more info. Sometimes SQL queries are slow for big backups & small blocks.
Starting a live log earlier might catch something. If you want a real file, use log-file=<path> at some kind of log-file-log-level. I suppose you could watch live log at Information and let Profiling make maybe a large file.
Verbose is in between.
Cloud Storage description at Google. Now is not the time, but it might be a less limited option to consider.
If you’re currently enjoying (except for the daily limit) an education account, note that change is coming…
What you are on also matters because you’re now asking about low-level networking to your destination.
Outages are typically detected as failures and retried, I don’t think it’s proven that they’re always detected.
It’s difficult to look inside a process. Is your system idle enough in general that Duplicati is the main user?
If so, you might be able to see if Task Manager’s Performance tab shows network activity, however if you want to look at activity just for Duplicati, you can try using Details tab, picking the child Duplicati, and using column selections to see if you can see anything. I’m not sure which category (if any) shows networking… Sysinternals Process Explorer has more capabilities, and even has a “Disk and Network” tab for process.
Might as well give up on the current list attempt by (not generally advised, but it’s stuck) process kill.
I kind of wonder how many files you have at destination, but list used to run unless you deconfigured it.
(Also worthwhile I probably have the same issue on another server)
Also I restarted the container now and it picked up the job again, it shows some more activity in monitoring now too. Probably need to wait a day again at least tho.
EDIT it probably picked up another job…
EDIT2 list worked, 6 broken files as it mentioned before. Now the purge is running. Do I need to repair the database afterwards again?
EDIT3 purge worked and backup started without running anything else before.
The filelist mentioned is not a file. It’s a list of files, basically a backup version (of which you have lots).
If you had run list-broken-files the files and their backup versions would be seen. Did purge give detail?
Regardless, there’s some damage when there are missing blocks, but hopefully broken files are gone, courtesy of their deletion. If a file is still around, the next backup will see it as new, and get current view.
Found 6 files that are missing from the remote storage, please run repair
and it probably named the missing files in some log or potential log. If the job log didn’t come out (check), try About → Show log → Stored, however best chance of seeing names is About → Show log → Live → Warning during the try. The lack of progress from Repair suggests they might be dblock (source blocks).
What’s that exactly? Restore what? If you mean recreate the database, you might consider this instead: