I’ve got a half dozen machines backed up on CrashPlan that I’d like to change over to Duplicati. As most of the machines are offsite from the Duplicati store, rather that start the backups from scratch I’m wondering if I can:
do a CrashPlan restore to original paths
back them up with Duplicati
point Duplicati on the “live” computers to the CrashPlan restore initiated backup destination
The only issues I can think of would be metadata related (different user accounts on the various machines) and I’m hoping that after the initial “restore based” backup the next “live computer” backup would re-set the metadata to the correct content. IF this metadata change were necessary, would that cause the equivalent of a full backup or just blocks associated with the meta data?
Assuming all the above actually works, if I wanted to really beat myself up I could (in theory) going from oldest to newest restore a CrashPlan version, do a Duplicati backup, restore the next CrashPlan backup, do a Duplicati backup, etc., etc. until I’d actually migrated my CrashPlan HISTORY to Duplicati in the historical correct order, though with artificial historical dates.
Note that while similar to the Topic below, that doesn’t work due to cross-OS differences (which are not a factor here):
The metadata is stored as a “file” (really a stream) by itself, so changed metadata does not cause the entire file contents to be re-uploaded. It does cause the file data to be re-hashed to check for changes.
Build a fresh VM matching the OS of the remote machine my dad has and restore crashplan to that. Then back it up using Duplicati.
Then I Stan duplicati on my dads machine and set up the necessary configuration, putting the metadata file in place as a seed, copied to my dads machine from my VM.
Might that work? Has to be better than re-synching 360odd gig of data…
I’ll have a go at testing it with a couple dummy VMs and see if I can pull it off. Might take me a few days though.
Oh, and where does duplicati store the metadata please?
Yes, that will work. Though you don’t need VM. If all you want is an initial seed then backing up a CrashPlan restore on any path will get the file blocks into Duplicati.
If the CrashPlan restore has the exact same path that’s better in terms of local database size but should have little effect on the destination size.
As for meta data, I’m not sure. I thought I saw another topic or two that covered that - did they not cover where it’s stored?
Note that if you’re really masochistic you could actually bring you CrashPlan history into Duplicati by repeatedly restoring CrashPlan version then backing it up (oldest to newest, of course).
I can restore the files from crashplan to any machine and back them up using duplicati. Because duplicati uses a consistent hashing algorythm and deduplication algorithm, I can have a single backup set on my target machine (SSH/SFTP target) accessed by two backup source machines which each backup the exact same files to the target. On the first backup, all the content goes in to the target from machine A, then the second machine really only checks that all the required blocks are at the target, sending only the hashes for each block and saving a lot of time and bandwidth.
If yes, then that’s a great help as im looking at an enormous amount of data and the true source PC (B in the above) is 500miles away…
Will this work equally well with GPG encrypted backups ?
Could I equally rsync an existing Duplicati dataset to a second machine ( or usb drive) and minimally change a copy of the backup job config as a mechanism for making the backed up content portable or creating redundant copies ?
If all this is doable, I’d recommend highlighting it as a feature.
Technically that is correct, though you don’t want to have two backup jobs pointing to a single destination. Probably the easiest way to do it would be to:
Do CrashPlan restore on any machine of similar OS (preferably to the exact same path)
Use Duplicati to back up the restored CrashPlan content (do NOT enable automatic runs for this job)
Export the Duplicati backup job to a file
Copy the backup job export AND the .sqlite database file to the “live” machine (you can get the file from the “Local database path” of the job “Database …” menu)
On the “live” machine import the job and make sure it points to the copied .sqlite file (again, in the “Database …” menu)
Run the job on the “live” machine and it should have minimal uploads at which point you can enable scheduled runs
Delete the CrashPlan job from the “CrashPlan restore” machine (just so you don’t accidentally run it from there as well)
You can skip the .sqlite database copy parts if you want as Duplicati is able to rebuild the database, but it can take a while to do so copying the file is generally much faster.
How mush of a problem is it if the origin machine is windows and the server I’ll be doing the ‘conversion’ on is Linux? What do I need to consider, or is it pretty immaterial?
In terms of blocks being stored at the destination, it’s not much of a problem - the file blocks are the same regardless of OS (unless you’re using on-the-fly disk encryption in which case the two machines would have different blocks).
However the paths associated with the blocks will be completely different, so if you did the CrashPlan restore-backup on Linux then switched to a live Windows machine Duplicati would consider all the Linux files to have been “deleted”. But since the actual data blocks still match they’ll just be re-used for the Windows backup.
Depending on your retention (Keep until) rules the Linux based backup should eventually disappear from your restorable history, but because the data blocks are still in use by the Windows machine they’ll not be deleted.
So if your goal is to not have to re-upload data from the Windows source and you don’t really care about being able to restore to the initial Linux backup, then it shouldn’t be a problem for you. But if it’s not too much effort to do the initial CrashPlan restore to a Windows machine then that’s one less thing to have to worry about.
I’m going to ping @kenkendk on this in the off chance I’ve gotten something wrong here as I believe he might have had some experience with this scenario.
I decided that I did need to create a VM for the crashplan restore. The reason being that the remote computer (two of them in fact, they are my Dads up in Scotland) is backed up under his CrashPlan account and in order to restore the data so that I can back it up using Duplicati, I need a computer with Crashplan installed, signed into my Dads CrashPlan account, and Duplicati installed, ready for later.
We will collaborate over the next few days to get the crashplan backup sets fully synchronised and up to date. Then I’ll restore the data (one pc at a time) to the temporary VM I created and then back that data up using Duplicate to the server.
@JonMikelV , I’m putting the data into his own user account in the home folder on an Ubuntu server with a few TB of RAID disks, all data will be GPG encrypted so that access to it will be controllable, nothing stored in the clear etc. and it won’t get mixed up with my own data. Also I can keep an eye on the data volumes.
How are you handling this aspect of things?
Since my remote family data is being stored on my hardware (and I usually trust myself) I’m not doing anything specific to encrypt their data. Just as with CrashPlan, it comes out of Duplicati encrypted (unless you set the job up without encryption) so only somebody who knows the each job’s encryption passphrase would realistically be able to do anything with the data.
In my case, for some strange reason my family also happens to trust me so I control their passphrase, but if a user were to arrive who didn’t want me to POTENTIALLY have access to their backed up data then I’d let them configure their own backup job passphrase.
As or storage usage, each destination is it’s own folder so I just keep an eye on that. I think if I cared to I could setup Minio buckets or NextCloud accounts with space limits, but to be honest it hasn’t yet been worth the energy to figure out how to manage that.
I’m running an unRAID server with 7TB of space (so far - just increase a drive today) so am not in any immediate risk of filling things up.
Ok, so I’ve completed two successful migrations now. Both of my Dads computes are now backing up using Duplicati without having to completely re-transfer all the data over the internet from 500 miles away.
I achieved this by doing the following steps:
Using a spare PC ( in my case a VM) I installed Crashplan and logged into the CrashPlan service using my Dada credentials
I restored all his content to a temporary folder.
I installed Duplicati and configured a backup job to backup all the contenti n that temporary folder to my server over my home LAN. The job was configured to run once only. I dod one PC with GPG and one with AES encryption just for the sheer hell of it.
I then copied the .sqlite database and the exported duplicati backup job to My Dads compter and imported the job and put the sqlite dataabse in the correct folder, making sure to check the path to the .sqlite database and the content being backed up before continuing.
I ran the backup job on the remote computer, which worked, but complained that thousanda of files were not listed in teh database, and requested a database rebuild. - not unexpected, I would say
I rebuilt the dabase and then the backup job quickly re-synchronised without sending all the backup data again.
I did have a few issues with in-use files not backing up correctly, so I just filtered them out. Files such as Temp fiels, Google cache fles and ntuser.dat files.
not the backups on both machiens are divorced from their dependency on CrashPlan.
I’m not doing the reverse so that the my crashplan backed up data on my Dads computer gets migrated to Duplicati. The interesting part here is that I’m using Windows subsystem for Linux on my dats PC as a handy way of delivering SSH access, with certificate driven access controls and data transfer. Settig that up was fun as I had to convert some dynamic DNS scripts I use on Ubuntu to work properly. Windows Subsystem for Linux is not a complete Ubuntu image by any stretch of the imagination, some simple tools are not implemented fully, like netstat or tcpdump. I’m still not quite sure of cron is working properly…
Suffice to say I have a workable setup now, and so long as I can figure out how to configure Duplicati to work purely on certificate exchange for SSH file transfers, then I’ll be finished.
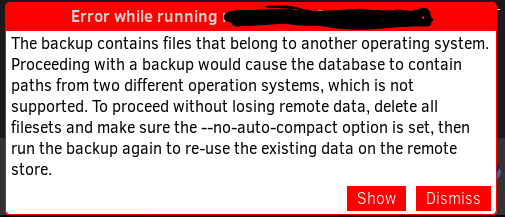
I ran into a problem on my final migration, the largest one at around 360GB. I followed the process above, but must have made a mistake along the way as I got this message:
That message scares me a bit as it’s unclear to a regular user what a “fileset” is.
My guess is it means the dlist files (path & hash references, can be rebuilt) at the destination but absolutely should NOT include dblock files (actual backup data, can NOT be rebuilt).