I discovered this thread after having a problem migrating from CrashPlan using the process I wrote up here : Seed Duplicati from CrashPlan?
I got the following message right at the end of the final migration, but was not able to understand it until I found this thread.
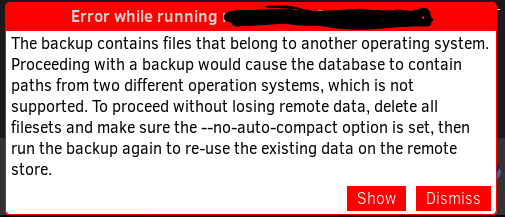
I’m about to try the process described farther up this thread and see what happens.
Wish me luck 