Hi,
I have the backups of some off-site machines available locally on my machine. Backup is currently done with Crashplan and I want to move them over to Duplicati. But since I don’t want those machines to re-upload the whole backup via a slow DSL upload link I was wondering if I can first create a backup from their data on my-machine (using the existing backup I got) and once finished set the offsite machine up so they simply link up with the just created backup and don’t reupload everything.
Does duplicati support something like this?
Yes. Duplicati does not care where you store the files. Simply edit the destination once you have moved the files, and it will continue to run with the new destination.
One caveat if you are using the commandline is that changing the URL will make it unable to find the database. To remedy this, edit the file ~/.config/Duplicati/dbconfig.json and change the url to fit.
Thanks. Actually in my case the destination stays the same but the source will be different. But I guess this would be the same scenario, i.e., updating the source settings.
Yes, that also works.
The first backup after the move will be slower, because Duplicati checks the previous timestamps for the paths before scanning the files. But since the paths change there are no timestamps so all files are re-scanned.
Mmh, I just ran a test:
- Created a backup from a folder on a linux machine. Ran it once and exported the configuration.
- Copied that folder over to a Windows machine. Installed duplicati there and imported the configuration, and edited the source location to match it where the folder is on the windows machine.
- When trying to run the back up now I get an error message:
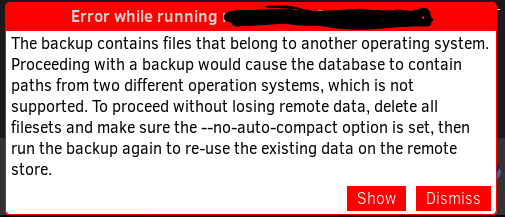
“The backup contains files that belong to another operating system. Proceeding with a backup would cause the database to contain paths from two different operation systems, which is not supported. To proceed without losing remote data, delete all filesets and make sure the --no-auto-compact option is set, then run the backup again to re-use the existing data on the remote store.”
I tried deleting and repairing the database on the windows machine but that did not help. I still get that error message. I’m not sure which “filesets” are meant actually. Can’t be the database, since that was deleted and restored. “Verify files” succeeds.
Any suggestions how to proceed?
Yes, the problem is that the database does not handle mixed / and \.
It means all the dlist files.
The suggestion is to remove all the dlist files (as they contain the paths), then run the repair to get a map of all the remote data. The next backup can then re-use all the stored/uploaded data with the new paths. The --no-auto-compact option is needed to make sure that Duplicati does not discover that some data is “not needed” and deletes it.
Tricky as it turns out:
- removed the dlist file
- deleted the database file
- ran backup command with
--no-auto-compactwhich detects the data files on the server and complains that the database needs to be repaired (this was expected) - running database repair will complain that no file list is present
- running backup command again will complain that database needs to be repaired.
I think we have a problem here since duplicati goes in circles. What now?
Still struggling with this problem. Isn’t there any way to resync the database so that it will work with a moved source?
Doooh! I had not thought about that, but yes, this will prevent you from doing it correctly.
For now you cannot re-sync in a cross-os manner.
If you really want it, you can grab the original dlist file, and remove all the files in there (or change the paths to fit the new OS) and place the that custom dlist file in the remote folder.
OK in that case I will probably have to move the backups stemming from a windows client using a windows machine and linux clients using a linux machine.
Anyway, thanks for the support! 
BTW: A good way of showing your appreciation for a post is to like it: just press the ![]() button under the post. If you asked the original question, you can also mark an answer as the accepted answer which solved your problem using the tick-box button under esch reply. All of this also helps the forum software distinguish interesting from less interesting posts when compiling summary emails.
button under the post. If you asked the original question, you can also mark an answer as the accepted answer which solved your problem using the tick-box button under esch reply. All of this also helps the forum software distinguish interesting from less interesting posts when compiling summary emails.
I discovered this thread after having a problem migrating from CrashPlan using the process I wrote up here : Seed Duplicati from CrashPlan?
I got the following message right at the end of the final migration, but was not able to understand it until I found this thread.
I’m about to try the process described farther up this thread and see what happens.
Wish me luck 
Ok, so this is by no means straightforward.
I had to:
- decrypt the dlist files from the backup destination, (in a safe folder because I’m paranoid) (gpg --decrypt file.name.zip.gpg)
- unzip the dlist file (unzip file.name.zip)
- construct some carefully crafted sed statements to translate the paths to match the source (sed commands below)
- rezip the dlist file (zip file.name.zip filelist.json manifest)
- re-encrypt the dlist file (gpg -c file.name.zip
sed commands I used:
sed -i ‘s/F:\\Data\\Greg-temp//g’ filelist.json
sed -i ‘s#\#/#g’ filelist.json
sed -i ‘s#//#/#g’ filelist.json
(Yes I could probably do this better, but this is a one time gig)
I’ll report back here once I know how well it has worked, if at all.
Just give it some more time. Should be OK I think. Did you delete the db or repair it? You could also run the same changes in the db I think and then no repair was needed.
/ has filled up. Duplicati process did not resume when I created space.
I’m not SQLite literate, so for me the easy route is to recreate it.
I’ve restarted the repair now.
It’s been running since my last post, I selected a delete and repair on the database, I hope that was right, as it’s whats mentioned above
Im monitoring the database files, their ATime is changibg(updating) every few mins, so something is happening. The disks are all healthy, the process (mono) is alive( fluctuations in cup and ram allocated to it. The free space on relevant volumes is consistently non zero by the order of gigabytes, overall cpu and ram are available in acceptable quantities (never hitting the end-stops). I noticed that swap was low so I added another 20Gig to the existing 5. Network traffic to the destination back end is active ( packets are flowing, tcp session is established, send and receive flow rates are at expected levels (non zero to maxing out periodically)
Which all makes me wonder, what is it actually doing? What does a delete and repair actually do? Ian it downloading each and every chunk and processing it before sending it back again? Is there any way to get more detailed statistics from duplicati?
Bearing in mind I’m trying to seed a migrated backup set from crashplan, I’m wondering if I would be best places to wipe the back end and start I’ve ? I’m keen to understand more.
Any advice welcome
Thanks for your interest!
Duplicati stores 3 times of files in the backend:
- dblock (actual file blocks, generally about your "volume sizel big)
- dlist (what files have blocks stored in what dblock files, generally pretty small since it’s mostly compressed text of file paths and hashes)
- dindex (what was backed up in a specific job run, generally pretty small and only one per job run)
A repair usually downloads dlist files to fill in the missing data in the database. A rebuild ends up downloading all the dlist files since all the data is missing.
If dlist files themselves are corrupt or missing then the raw dblock files are downloaded. This can take much longer due to their larger size.
If you go to the main menu Show Log page you can look at the Live tab in Profiling mode to see pretty much everything Duplicati is doing.
Alternatively, if you use the --log-file and --log-level (set to profiling) parameters when the repair is started you’ll get a text file of the same info.
Ok, thanks.
I have nothing for logs, except a droplist saying “Disabled”.
Where would I look to find files that it has downloaded from the backend to see what size they are and how many there are ? ( I see in the job-specific logs that it has downloaded “17517 volumes for blocklists” and is currently processing all of them.
is “blocklist” here the dblock files ? (I have only 2 dlist files on the backend, these are the ones I modified to correct the file paths.
I’m just wondering if I should cancel the database rebuild and start the backup from scratch. I’m worried that if I lose connection on my flaky ADSL broadband, or the SSH tunnel drops or something, that I would have to restart the rebuild from scratch… in which case a fresh backup might be preferable as at least it will pick up where it left off ?
Thanks