Good advice for an export with a schedule, as it may be past scheduled time by time it’s imported.
Don’t really want it going immediately. Downside of unchecking is one must enter Schedule again.
Possibly unchecking the current day of week will work, but I haven’t tested to see if it really works.
I did test start of import (no save) of old export with its schedule, and it came up with old next time.
Probably the thing to do there is to get the schedule looking the way you want it before doing save.
One might think so, but it runs anyway at least in some cases, such as a schedule already missed.
There have been some other posts around seeking to deal with this, and also how to control order.
I set Duplicati for 10 minute pause on startup, set a backup to a time shortly in the future, and Quit.
After missing that scheduled time, I started Duplicati to see what it thought it was going to do when.
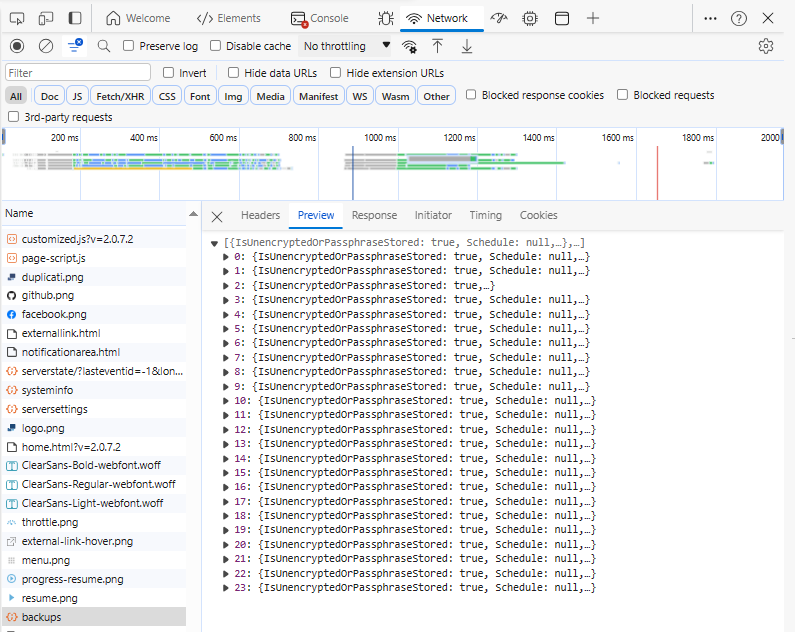
About → System info is a good spot to look, but it’s human-unfriendly, and I’m not an expert reader.
End result is uncheck, save, (and to be extra sure, trip back to Edit to look) saw it run at pause end.
I did also save a server database trail at significant points, if it comes down to looking at DB insides where it tracks things like the schedule, its last run time, and so on. Not sure it tracks next run time, however it seems to set a schedule at startup, and after that, it acts sticky despite a job deschedule.
There is possibly a two-part schedule, as the proposed schedule looks like the one AFTER this one.
before quit
Next scheduled task: Name Today at 8:20 AM
(I forgot to note Server state properties)
(Quit, wait, start after 8:20 with 4 hour schedule in zone UTC-4)
during pause
Next task: Name
proposedSchedule : [{"Item1":"4","Item2":"2023-10-19T16:20:00Z"}]
schedulerQueueIds : [{"Item1":2,"Item2":"4"}]
after deschedule
Next task: Name
schedulerQueueIds : [{"Item1":2,"Item2":"4"}]
during run
Name: Starting backup
proposedSchedule : []
schedulerQueueIds : []
after run
No scheduled tasks
proposedSchedule : []
schedulerQueueIds : []
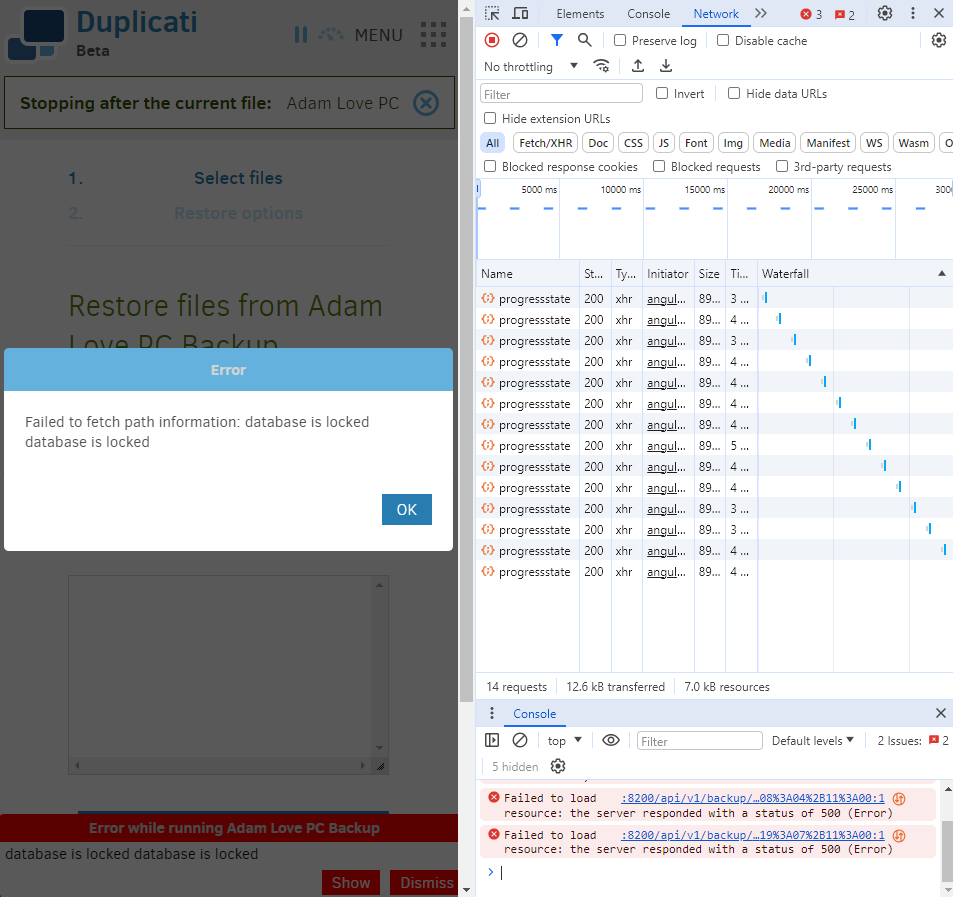
It doesn’t update the server database until after the run. I think an expert once said that’s intentional.
Are you doing something like migration to new computer, and relying on Duplicati for its file restore?
Backing up an empty area would probably error out quickly, with no damage done, unless you have
allow-missing-source
Use this option to continue even if some source entries are missing.
in which case it might make an empty backup that you wouldn’t really want but which you can delete.
Migration to new PC - faq wanted How-To has one plan, although it’d be nice if the manual covered it.