I poked at this some, and can’t reproduce a half hour delay. Mine ranged from really fast to minutes. Concern early on was that perhaps stop was not coded into the early phase when it’s counting files. Because I have some very large file trees (with small files), I tried one. No problem. You can give an additional hint on what you see on the status bar, the home screen job area, etc. (or ultimately a log showing the activity), and maybe someone can figure out why your stop operation is taking that long.
Thanks for your thoughtful responses. I appreciate the effort you put into troubleshooting individual issues. However, I believe focusing on preventing needless and redundant jobs from running before they start would benefit many users, including those with large databases like mine (13GB, 6GB, and 3GB).
For instance, allowing users to cancel a job before it starts* would simplify processes for anyone needing to restore files after a period longer than their backup interval. This is a common scenario, so implementing such a feature would provide a broad solution to a recurring problem.
*such as with a “cancel” button that is effective before duplicati is unpaused (or effective at all), or a “remove from queue” function
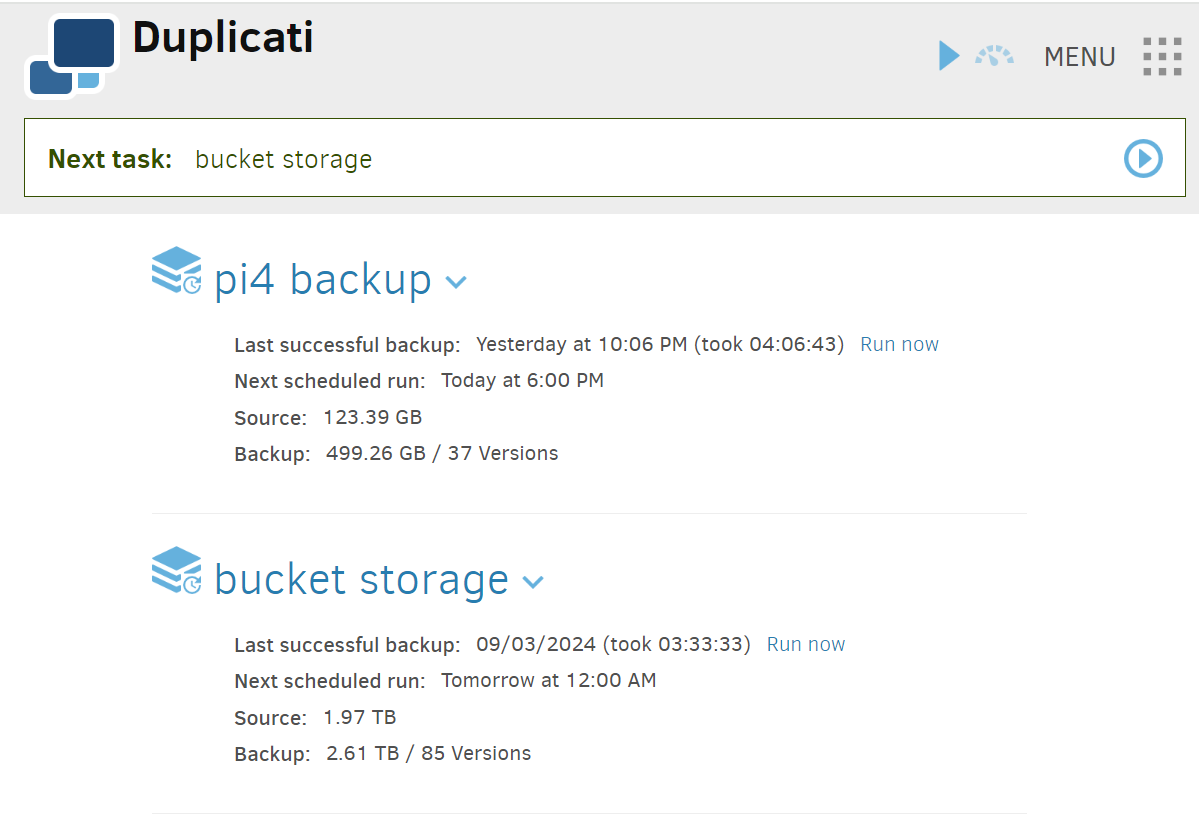
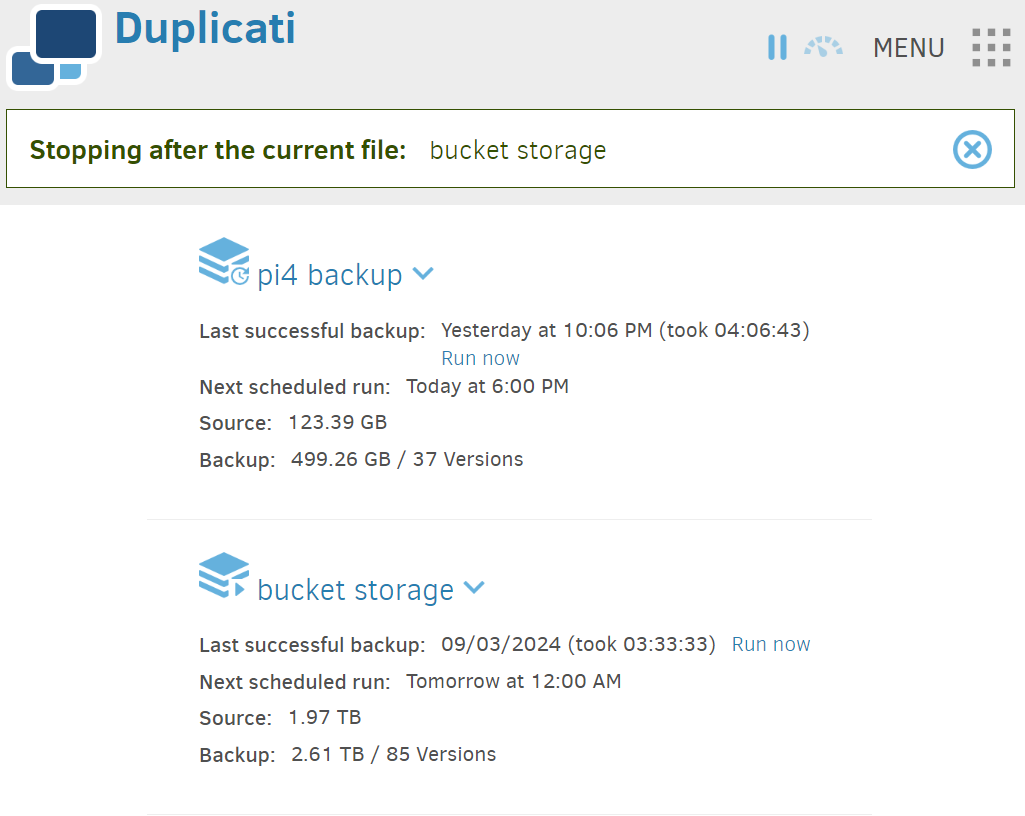
Currently, I am trying to restore a simple config.json file, a few KB, from my “pi4_backup”. My Google Cloud service bucket is switched off from Google’s end, so the pictured ‘bucket storage’ won’t work anyway, yet it insists on taking (what is now, and counting) 79 minutes to “stop after the current file,” which is quite frustrating.
You are welcome to look at my database and logs if you want to, but with nearly infinite variables and unique setups for future users who encounter the issue in future, I’m not sure it’s the best use of time. Implementing this feature could save countless users a lot of time and frustration, making the experience smoother and far more efficient. It’s difficult to see how anyone could justify continuation of this process in its current state.
Features requests, even good ones, sometimes take a back seat to highly urgent development needs.
The amount of work that is possible far outweighs the number of people willing to help with the project.
This topic remains a support request. Want me to make it a feature request to see who else wants it?
EDIT 1:
Features category currently has 402 requests, and is not good at tracking closed ones. GitHub Issues
has 278 enhancement requests, is a better tracker, and is potentially more looked at by the developers.
I’m not sure which has more discussion by end users. I’d guess the forum, but that’s just me guessing.
EDIT 2:
Admittedly the temptation to work on one very-long-requested feature seems to have gotten work going.
EDIT 3:
Making this topic a feature request would not attract attention, because the current title doesn’t describe.
Maybe you can see if this has come up before in either forum or Issues. If so, me-too it. If not open one.
This is a really annoying problem. The cancelling process is so convoluted it takes a full page to describe what does what (just look at this), and it can’t even abort things like a stuck upload.
Right now the best option to do what you want is to edit the backup(s), disable the schedule, then kill duplicati if stop now is stuck after a minute or so (hoping that doesn’t break something, if it does, a repair should fix it). Then, after a restart you can actually restore something without all the queued backups getting in the way. Afterwards you have to enable all the stuff again.
“Stop now” might be better. I don’t know the details, but I think “after current file” will make data to upload, then the stop will wait for the data to be uploaded, then your switched off cloud won’t. But it’s odd that the retry count isn’t running out and causing job end by error. It’s also possible that Google Cloud is different.
Regardless, operational Backblaze B2 here does Stop now in under a minute, if I ask for it right away.
If you have set up a log file, that would be good, and not prone to transaction roll-back like database is.
Looking at live log can also be useful, but a log that’s started before things get stuck has a better view.
Seeing that makes me wonder if the schedule changing approach would be easier – though maybe not easy, and arguably something of a (legitimate) special case compared to making stops work better in all situations.
I don’t know who knows the scheduler well besides the very busy original author, but one request was below:
Add ability to skip missed scheduled backups #3251 although I’m not sure the idea of using an option is best because who wants to, or knows to pass in special options? A GUI interaction might be nice, but would have to present itself in some pause time before missed job starts, as after that, we’re back to the fast stop issue.
If you’re still seeing this, or anyone else please! Thx.
Same problem here, but your solution: “go to the fourth tab, uncheck automatic scheduling,”
Does “fourth tab” mean the fourth step, across the top in screen shot below? I can’t get to it, can’t get past “waiting for task to begin” in the third step. Or does it mean the fourth tab on the left, Settings? I don’t find a “automatic scheduling” checkbox there?
With an exported configuration, you can delete an existing configuration and re-create it by importing the configuration. You can optionally edit the parameters so the re-created backup configuration differs from the original.
So in that context, fourth tab means the same as how any job create or edit would configure its