I’ve been trying to wrap my head around the pipeline that performs a backup. Partially to better understand how it decides what files to process and to look at ways to improve the abstract file IO setup since different parts of the app enumerate files differently. I’ve also noticed a significant number of exceptions related to trying to handle a directory as a file which just gets swept under the rug.
The other thing that bugs me is this duplicate file enumeration in the pipeline to count files while another enumeration is used to backup files.
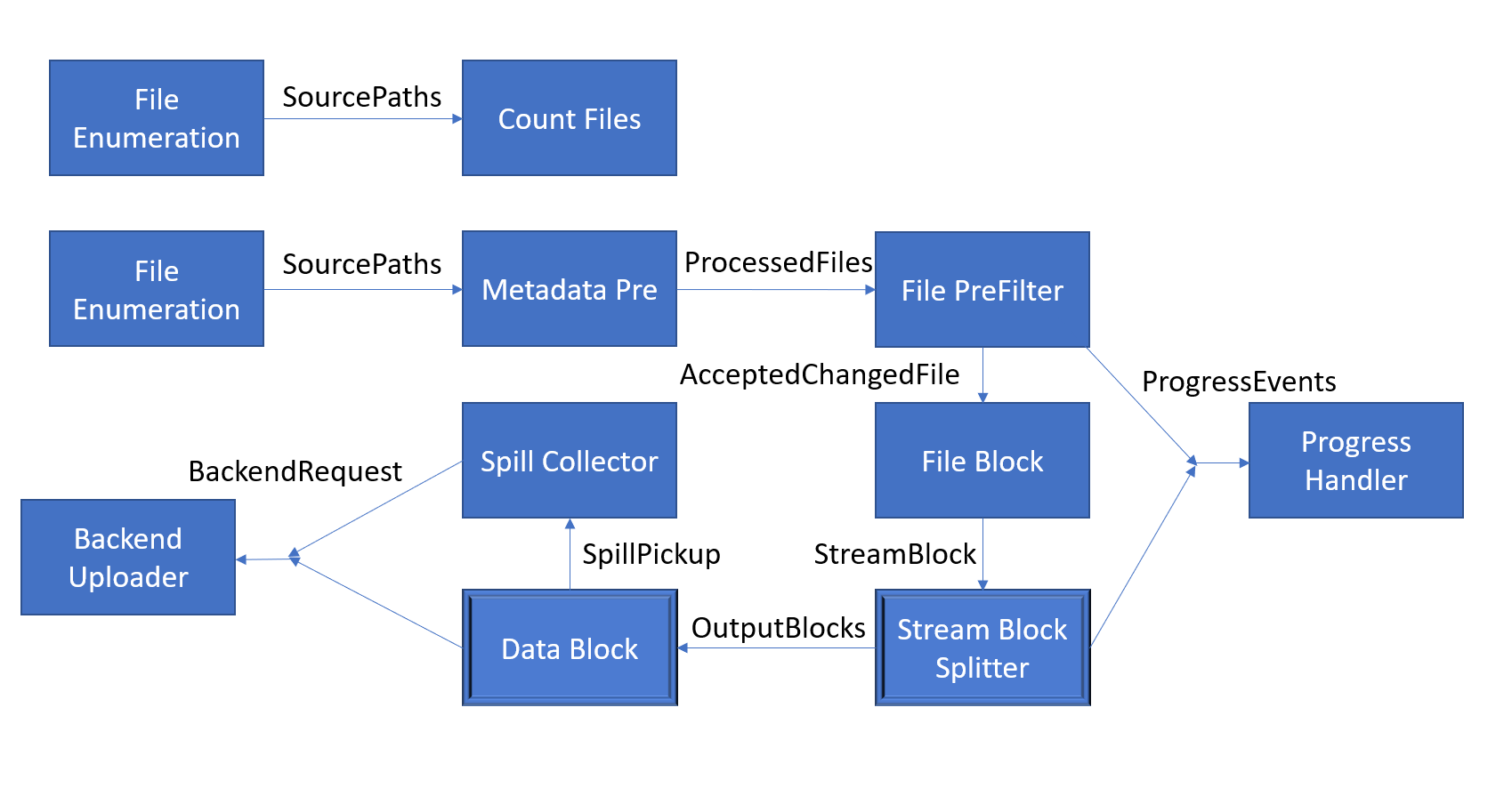
I would appreciate anything people can share about the function of any of the backup handler processors, especially the stream block splitter through the spill collector.
I am considering looking at a refactor away from CoCoL to System.Threading.Channels as well as hooking the count files processor into the normal flow with another channel. The big advantage being able to configure the processors in a more “inversion of control” manner that would lend itself better to dependency injection / unit testing. Not that CoCoL couldn’t do it, but if you take away the magic by name binding it basically IS System.Threading.Channels so you might as well use the name brand.
Duplicati developers have been moving away from “helper” libraries as standard capabilities emerge,
e.g. 2.0.5.1 Beta uses Long Path Support (MAXPATH) done in .NET Framework 4.6.2 and mono 5.0.0.
I guess that there are sometimes fine points that should be considered, but I’m not qualified to do that. CoCoL: Concurrent Communications Library and related papers does some in-depth analysis of this.
Let me post a draft of a note I started about a year that attempts to trace the summary to source code:
https://forum.duplicati.com/t/alternative-ftp-failure/7822/10
In Duplicati, this is used to enabled concurrency for hashing and compressing.
Roughly the following happens:
A process traverses the file system and writes paths to a channel
Maybe FileEnumerationProcess.cs
A process reads paths and checks if the metadata has changed; all changed paths are written to another channel
Maybe MetadataPreProcess.cs
Multiple processes read paths and computes block hashes; new block hashes (and data) are written to a channel
Maybe StreamBlockSplitter.cs
Multiple processes read blocks and compresses blocks; filled volumes are written as upload requests
Maybe DataBlockProcessor.cs
A process caps the number of active uploads
Maybe https://github.com/duplicati/duplicati/blob/63ecd1a49ff66acbd0335044ecb360c73a218468/Duplicati/Library/Main/Operation/Backup/BackendUploader.cs#L196-L199
A process performs the spill pickup (as described above)
Maybe SpillCollectorProcess.cs
A process performs the remote operations (upload, download, list)
Maybe BackendUploader.cs
https://github.com/duplicati/duplicati/blob/master/Duplicati/Library/Main/Operation/BackupHandler.cs
{
Backup.DataBlockProcessor.Run(database, options, taskreader),
Backup.FileBlockProcessor.Run(snapshot, options, database, stats, taskreader, token),
Backup.StreamBlockSplitter.Run(options, database, taskreader),
Backup.FileEnumerationProcess.Run(sources, snapshot, journalService,
options.FileAttributeFilter, sourcefilter, filter, options.SymlinkPolicy,
options.HardlinkPolicy, options.ExcludeEmptyFolders, options.IgnoreFilenames,
options.ChangedFilelist, taskreader, token),
Backup.FilePreFilterProcess.Run(snapshot, options, stats, database),
Backup.MetadataPreProcess.Run(snapshot, options, database, lastfilesetid, token),
Backup.SpillCollectorProcess.Run(options, database, taskreader),
Backup.ProgressHandler.Run(result)
}
// Spawn additional block hashers
.Union(
Enumerable.Range(0, options.ConcurrencyBlockHashers - 1).Select(x =>
Backup.StreamBlockSplitter.Run(options, database, taskreader))
)
// Spawn additional compressors
.Union(
Enumerable.Range(0, options.ConcurrencyCompressors - 1).Select(x =>
Backup.DataBlockProcessor.Run(database, options, taskreader))
)
Duplicati\Library\Main\Operation\Backup\FileEnumerationProcess.cs
Output = Backup.Channels.SourcePaths.ForWrite
Duplicati\Library\Main\Operation\Backup\CountFilesHandler.cs
Input = Backup.Channels.SourcePaths.ForRead
Duplicati\Library\Main\Operation\Backup\MetadataPreProcess.cs
Input = Backup.Channels.SourcePaths.ForRead,
StreamBlockChannel = Channels.StreamBlock.ForWrite,
Output = Backup.Channels.ProcessedFiles.ForWrite,
Duplicati\Library\Main\Operation\Backup\FilePreFilterProcess.cs
Input = Channels.ProcessedFiles.ForRead,
Output = Channels.AcceptedChangedFile.ForWrite
Duplicati\Library\Main\Operation\Backup\FileBlockProcessor.cs
Input = Channels.AcceptedChangedFile.ForRead,
StreamBlockChannel = Channels.StreamBlock.ForWrite,
(multiple)
Duplicati\Library\Main\Operation\Backup\StreamBlockSplitter.cs
Input = Channels.StreamBlock.ForRead,
ProgressChannel = Channels.ProgressEvents.ForWrite,
BlockOutput = Channels.OutputBlocks.ForWrite
(multiple)
Duplicati\Library\Main\Operation\Backup\DataBlockProcessor.cs
Input = Channels.OutputBlocks.ForRead,
Output = Channels.BackendRequest.ForWrite,
SpillPickup = Channels.SpillPickup.ForWrite,
Duplicati\Library\Main\Operation\Backup\SpillCollectorProcess.cs
Input = Channels.SpillPickup.ForRead,
Output = Channels.BackendRequest.ForWrite,
Duplicati\Library\Main\Operation\Backup\RecreateMissingIndexFiles.cs
UploadChannel = Channels.BackendRequest.ForWrite
Duplicati\Library\Main\Operation\Backup\BackendUploader.cs
Input = Channels.BackendRequest.ForRead,
This was done just by tracing Channels references in source. I don’t do pictures well, so there are none.
If a conversion to a new way happens, it would be nice to improve the documentation while sorting it out.
The net5 branch is all that exists for me. Last weekend I couldn’t get the master branch to build without all kinds of errors about framework version incompatibilities and then once I tried to straighten that out it still wouldn’t run.
So I flipped a table and checked out the net5 branch. It at least compiled but didn’t run correctly, a few fixes and a merge with master later and I seem to be able to run a backup (I haven’t let it run to completion because the backup set I configured is huge, I need to change that).
So as far as I’m concerned master is dead to me and long live net5. Realistically I need to fix the continuous integration scripts for that branch that is probably the biggest issue preventing merging that I can see. Followed only by the release publishing scripts.
Your notes are a little more than I had jotted down, I went cross eyed after making my diagram from those channel lists but you put a description with each phase which is what I was trying to figure out.
Till the net5 branch is merged probably all I’ll do for the pipeline is write a readme in the operation folder. No need to convolute the net5 branch.
Visual Studio 2019 Community Edition on Windows 10.
It was mainly bitching that .net 4.6.1 libraries referenced .net 4.6.2 libraries. In my infinite wisdom I took it as a sign that many of them should be .netstandard but when that still didn’t fix it I found the net5 branch. It is possible if I just find replaced “4.6.1” with “4.6.2” it would have been fine. I presumed the mono compiler may not care and is why no one noticed.
All pull requests and merge commits into master are built in AppVeyor (Windows) and Travis (Linux). On Windows there are a few warnings (related to gtk-sharp and Tardigrade librares), but I don’t see any that sound like what you mention. Are your NuGet packages up to date?
I’m pretty sure the nuget was up to date. I had to clean build after installing all the targeting packs for the various framework versions. I suppose the 2019 compiler could be more strict, I think the CI scripts use 2017.
But now that I’m on the net5 branch, I’m inclined to try to get it merged rather than figure out what was wrong with my framework setup.
I use the same and have no issues compiling. If you get warnings about a missing a specific NET version Targeting Pack, you’ll want to make sure to install it instead of altering the source.
I fully support moving to .Net5, but I think we need to get the automatic updating sorted out before we can switch.
I think we could use the current code, but it would be nicer if we could switch to distributing pre-compiled binaries for each platform (i.e. do not require a framework installed on the machine).
Packaging the runtime is just a command line switch so that shouldn’t be an issue. “Publish single file” is the nuanced option and at least initially I wouldn’t bother with it.
I’m fiddling with a GitHub action on my fork to do the basic build, test, package. Hoping to get that squared away today (last day of vacation). Then I’ll look at the existing build scripts and see about getting Travis and appveyer working again. The existing stuff seems to refer to coveralls and some complicated test reporting but I don’t recall seeing those results anywhere. Are the coveralls results public? Do we need to keep it functioning?
Knock on wood this build should succeed on github actions
The unit tests take 40 minutes to run.
It should also publish self-contained artifacts for windows, mac, and linux. I tried to use some more options to reduce the size/be more efficient but those mechanisms DO NOT LIKE that executables link to other executables. So there is a future task there to refactor “library” code out of the command line and etc. executables.
I also made more fixups, including moving the UnixSupport into the main build and just including the mono posix library from nuget.
The biggest fudge I had to do was unit tests failed on macos because the last modification time differs by hundreds of milliseconds after a restore. I tried to debug it but AFAICT the time is correct right after it sets it (optimistic caching?) and then is some value less afterwards. The only other thing I can think of is a race condition in the unit tests somehow that only comes up on mac. I don’t have time (or a mac) to do more in depth investigating.
Ya, github actions just seem convenient and at this point there is nothing that I can see us needing they can’t do.
I got selenium running, simplified the scripts and updated it to Python 3. FYI the firefox container changed so now the selenium build is broken with the existing scripts.
Last thing I think I need to do there for parity is to download the test files. Not sure what’s different about them vs running tests without them.
I also want to see if I can make the actions generate artifacts for the RPMs, debs, etc. I think that would be amazing.
I’ve got a Deb and an rpm built. Next I need to test them because I’m 99% sure they don’t work correctly yet. Things seem generally simpler because the build is configured to put everything it needs in the publish directory vs the current pull files from all over the place approach. Not having to deal with mono is also nice.
Sounds like good progress @tsuckow. Do you know if GitHub actions can run the tests against pull requests created from forks? My earlier investigations seemed to indicate no.
As far as I know they changed it in August to support it. There are some security settings on the project that control some of the risk. I’ve been avoiding third party actions which if used you would want to whitelist. I’m also not using any embedded secrets. I assume if you want to sign anything the release manager would do it on their own machine.
Thanks @tsuckow. We often have issues with Travis (especially right now), so I’m exploring replacing AppVeyor/Travis with GitHub actions. This should hopefully make the transition to .NET 5 a little smoother as well, by using the same CI technologies.
I encountered the same timing issues that you described when testing on macOS. I hope you don’t mind if I cherry-pick some of your commits into my branch?