Be careful how you interpret that. I don’t think it’s what’s left to backup, but what’s not been studied yet.
By definition, a backup starts from scratch in file study. The question is how much it will need to upload.
Only changes are uploaded, meaning data that is already uploaded (maybe from prior run) isn’t (again).
Features in the manual describes this. Look especially at its “Incremental backups” and “Deduplication”.
Channel Pipeline is a deeper explanation of what’s happening, but basically there’s typically finding the relevant source files, checking for need for file opening (e.g. if timestamp changed, see what changed), reading through the suspected changed file to see which blocks in it changed, then uploading changes (provided the block is not already in the backup). This is very storage-efficient, but begs the question of what a given number means when you see it on the screen or in the log page from the backup run, e.g.
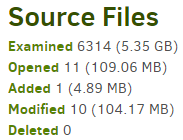
and in Complete log one can find actual upload statistics:
"BackendStatistics": {
"RemoteCalls": 12,
"BytesUploaded": 27330892
The status line for this backup has come and gone, but the way it generally runs is to get very high possibly based on “Examined files”, reach a peak, then go down as the later file processing occurs.
You might notice (especially on incremental backups) that this part isn’t there at the start, because uploading hasn’t begun because enough blocks from changed files haven’t been accumulated yet.
I’m not sure how well that works. It probably works better for initial backups that are upload-limited.
Incremental backups might start uploading then wait for awhile while getting more changed blocks.
Behavior depends on the nature of the backup source. Mine has a lot of files that rarely change, as evidenced by 11 of 6314 being opened for an exam, but I’m pretty sure the status bar went past 11.
Your video files are probably large and relatively few, so folder scans could probably tally 2 TB fast, however that doesn’t mean you have 2 TB left to upload. I don’t think that value is even computed, because (unlike enumerating files, which can turn into numbers as fast as folders can be checked) forecasting how much changed data it will get in future files isn’t really possible. Files need reading however reading creates files to backup, but upload queue is limited by asynchronous-upload-limit.
EDIT:
Start from scratch is a great chance to know what was there. Generally you delete the database and remote files. If you delete the database but leave its remote files, backup complains about extra files.
If you’ve been through that and had to delete files, then you know that some files had been uploaded. What’s supposed to happen is that blocks in uploaded files aren’t uploaded again, but it’s hard to test.
I suppose you could test it there on some test data, comparing uploaded bytes between initial backup versus initial backup interrupted halfway through then allowed to complete in second. “Should” upload similar amount of total bytes either way…