I have a flaky network connection, often dropping. If I try and back up 2TB of data, if I’m lucky it gets to 1.16TB left and then I get a network error.
Is there a feature flag (or can it be implemented?) to resume backups that failed for network errors? Every time I restart, it starts back from 2TB. The only workaround I have so far is to do folder by folder and run the backup in parts, which takes ages and a lot of effort with ~500 folders.
Not everything out there supports resume as much as one would think everything should and resume on one thing might work better on another. You could always try a different means of connection.
Though its certainly possible Duplicati is at fault and needs a fix. I don’t know. Could just be a difficult to reproduce issue that you run into.
Also, 2TB is huge to throw into containers and even 1TB is huge anyway. You should think about what you’re doing and do it differently. You could even do multiple backups in Duplicati so you have 500GB chunks or even 100GB instead (clarification: not literal amounts but multiple backups of approx size as I’m sure someone will take it literally lol). I doubt you have single files that large. If the files were large enough then why even throw them into containers in the first place. It just take a lot of extra time and adds a complication. Choose a different backup means.
One or multiple of these points will solve your problem.
How long is it out when it drops? Have you worked with your ISP, ruled out local Wi-Fi glitches, etc.?
When it doesn’t drop completely, does it perform well on upload test (may vary by test), or is it slow?
--number-of-retries = 5
If an upload or download fails, Duplicati will retry a number of times before failing. Use this to handle unstable network connections better.
--retry-delay = 10s
After a failed transmission, Duplicati will wait a short period before attempting again. This is useful if the network drops out occasionally during transmissions.
You can set those as high as you can stand to wait. Sometimes it may be better to give up and bail out.
Please look at the destination files. By default you should have a bunch of 50 MB dblock files, each with dindex file that indexes it. While some might be truncated (if network died in middle), good ones persist.
Any Duplicati backup needs to look through all the files to see what changed, but uploaded data should not upload again. In this sense, next backup is automatically a resume. It should even upload a Restore entry (please look) for the interrupted backup to get what was done so far. Typically this is the previous backup plus what was backed up before interruption. It possibly differs if initial backup has not finished.
Although poor network performance might be hiding it now, Duplicati performance slows when tracking more than a few million blocks (database operations slow). For 2 TB you’d want blocksize of 1 or 2 MB instead of the default 100 KB. Unfortunately you can’t increase blocksize without taking a fresh backup.
Depending on how fast and stable your network is (or isn’t), is cloud backup/restore even a good idea?
Maybe your download reliability is better? On some network technologies (e.g. cable), that can happen.
The backup is composed of video editing files; there is no real reason to logically separate those into chunks. I could split them by dates, but that would be forcing it just for a limitation in the technology. Ultimately, I want to do an incremental back up of the whole drive and having to run separate jobs for the same purpose seems cumbersome. However, if that’s what it takes to get it to work properly, I can split it.
It’s a bit complicated; my connection is reliable, but 4Mbps, which would take a month to back up 2TB, so I am trying to run it from a friend’s place, so I cannot argue with their ISP for them, it’s 14Mbps, but the reliability is crap. For the same reason, I can’t replace the router or do much else.
Thank you for sharing those options, they seem quite helpful, I set the number of retries to 20, 30 seconds between them to allow the connection to get back and I also found the flag to enable exponential back-off which will be helpful.
Unfortunately this has not been my experience, I am using 2.0.6.102_canary_2022-04-06.
Every time it fails (recently for DNS or network failure: NameResolutionFailure), it just reports back the original time. As I said, the only workaround I found is to change source every time and add one folder at the time. I will have a look at the other issue on the forum, thank you. I had a look and, unfortunately, that is not what is happening to me, it’s not just during the checking phase, but it actually starts over.
If increasing the block size would improve significantly performance or resiliency, I am happy to do so and start again; despite running it several times for days, I’m still stuck at 6GB/2TB as it keeps failing.
Cloud backup (no restore) is mainly for physical security, if someone breaks into the house and steals the hardware, at least I can recover it from the cloud. For critical data I do both a local backup and a cloud one.
This is brand new in 2.0.6.102_canary_2022-04-06 which is the latest Canary. I didn’t mention it because most people prefer the Beta. Canary gets the latest fixes, features, and whatever broke in adding those…
If you like this plan, you’re welcome to it. Canary is “usually” better, but bugs do sometimes get released.
I’m not sure I heard an answer, however there was one answer below multiple paragraphs you quoted.
What does “reports” mean? I’m talking about the Restore GUI dropdown. What were you talking about? Depending on what you’re looking at, it could be many things. There’s almost certainly more than a time.
What is “original”? Start of the failed backup, the previous backup, something else? This all needs more.
Still lacking data on what files (if any) it left from the run that was interrupted. Dying before anything got uploaded, of course, means “starts over” (for the increment) is the right move. Possibly you will have to look at dates on files to find what went up in a given incremental run. Or use logs to watch the uploads.
About → Show log → Live → Retry might be a good one, or use Information if you don’t like retry detail. Either of those will show upload actions. log-file=<path> log-file-log-level are better for higher log levels.
File data is also a little easier to paste here to describe the sequences without you having to detail it all.
Please look at the destination files. By default you should have a bunch of 50 MB dblock files, each with dindex file that indexes it. While some might be truncated (if network died in middle), good ones persist.
Apologies I forgot to check that, I believe now it may be late as I have re-run from scratch several times.
What does “reports” mean?
I refer to the top bar stating 1827 files (59.09 GB) to go at 4.32 MB/s rather than time I should have said “size” left. I got confused as I usually try and translate that into time with a calculator. By “original” I mean that if it gets interrupted at 1TB/2TB, when I restart, it goes back to 2TB/2TB to complete.
I’ll try and have a look at the detailed logs, however, just by roughly looking at the size left, seems to be always starting from scratch.
Be careful how you interpret that. I don’t think it’s what’s left to backup, but what’s not been studied yet.
By definition, a backup starts from scratch in file study. The question is how much it will need to upload.
Only changes are uploaded, meaning data that is already uploaded (maybe from prior run) isn’t (again).
Features in the manual describes this. Look especially at its “Incremental backups” and “Deduplication”.
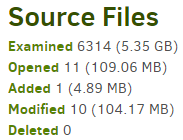
Channel Pipeline is a deeper explanation of what’s happening, but basically there’s typically finding the relevant source files, checking for need for file opening (e.g. if timestamp changed, see what changed), reading through the suspected changed file to see which blocks in it changed, then uploading changes (provided the block is not already in the backup). This is very storage-efficient, but begs the question of what a given number means when you see it on the screen or in the log page from the backup run, e.g.
and in Complete log one can find actual upload statistics:
The status line for this backup has come and gone, but the way it generally runs is to get very high possibly based on “Examined files”, reach a peak, then go down as the later file processing occurs.
You might notice (especially on incremental backups) that this part isn’t there at the start, because uploading hasn’t begun because enough blocks from changed files haven’t been accumulated yet.
I’m not sure how well that works. It probably works better for initial backups that are upload-limited.
Incremental backups might start uploading then wait for awhile while getting more changed blocks.
Behavior depends on the nature of the backup source. Mine has a lot of files that rarely change, as evidenced by 11 of 6314 being opened for an exam, but I’m pretty sure the status bar went past 11.
Your video files are probably large and relatively few, so folder scans could probably tally 2 TB fast, however that doesn’t mean you have 2 TB left to upload. I don’t think that value is even computed, because (unlike enumerating files, which can turn into numbers as fast as folders can be checked) forecasting how much changed data it will get in future files isn’t really possible. Files need reading however reading creates files to backup, but upload queue is limited by asynchronous-upload-limit.
EDIT:
Start from scratch is a great chance to know what was there. Generally you delete the database and remote files. If you delete the database but leave its remote files, backup complains about extra files.
If you’ve been through that and had to delete files, then you know that some files had been uploaded. What’s supposed to happen is that blocks in uploaded files aren’t uploaded again, but it’s hard to test.
I suppose you could test it there on some test data, comparing uploaded bytes between initial backup versus initial backup interrupted halfway through then allowed to complete in second. “Should” upload similar amount of total bytes either way…
Be careful how you interpret that. I don’t think it’s what’s left to backup, but what’s not been studied yet.
I get it, however, so far, running it by the calculator, it has been fairly consistent with the actual time.
By definition, a backup starts from scratch in file study. The question is how much it will need to upload.
Only changes are uploaded, meaning data that is already uploaded (maybe from prior run) isn’t (again).
Given this is an initial backup on static data, data is always unchanged, it’s just appending files (that’s probably also why the time is consistent)
Start from scratch is a great chance to know what was there. Generally you delete the database and remote files. If you delete the database but leave its remote files, backup complains about extra files.
If you’ve been through that and had to delete files, then you know that some files had been uploaded. What’s supposed to happen is that blocks in uploaded files aren’t uploaded again, but it’s hard to test.
I deleted everything so it should be as-new now.
Eventually I came back home with no backup done because of all the network issues and the software not resuming; so I don’t have the larger bandwidth now (back to my 4Mbps), but, at least, my connection is more stable. I increased the retries and time and back-off and kicked off the backup again, but this time on few folders at the time, that seems to be the only way to get this done at the moment. Thanks anyway for the help. Would be still good to know if/how to resume on network errors, but, for now, I’ll just manually add one folder at the time.