I want to enable the best possible compression - that is, make the stored data as small as possible - I don’t care if that makes it slower. I guess this applies to de-duplication settings as well - if there’s any settings I should change regarding that to make the stored data smaller?
I read some forum posts about this already, but they were too old so it was too confusing - some mentioned things that apparently have since changed, etc., so I’m asking again.
What’s the best compression to use, and how do I enable it?
Can I enable it on an existing backup set that’s already backing up somewhere? If so, how?
If I can’t enable it on an existing backup set, is there any workaround to somehow enable it and keep the backed up data, or do I need to start from scratch?
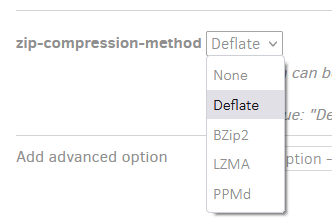
You can adjust the compression method by adding the “zip-compression-method” advanced option to your backup definition.
The default is “Deflate” but you can choose among some others. I believe I’ve heard on the forum that “LZMA” generally offers better compression, but you may want to try running backups yourself to compare.
You can change this setting on an existing backup, but it will only affect new volumes.
Perhaps @ned can say something about the total situation, why compression seems important over all else, size of files and backup, value of historical backup versions (lost on a start from scratch), and so on. Maybe there are some other options that should be changed (depending on needs) if a fresh start is done.
I am trying to implement a versioning and first-stage backup for work files. “Long term” backups are handled by other backup software and stored in the cloud etc., and actual code versioning is handled by each project uniquely (git or whatever usually).
What I’m trying to achieve here is a way to quickly restore all the projects back to the state they were at yesterday should something stupid happen like my laptop dies (so very short term backup I guess you could say), or more likely, a way to restore a specific file or project to how it was at some point in the past, should I realise that all the work I’ve done in the past week was a disaster and I need to revert or whatever (kind of an overarching git-style versioning thing).
I am upgrading from a basic system that used FreeFileSync and copied files to a deduplicated storage on my server, but it couldn’t handle symlinks and was confusing to figure out versioning and stuff, and versioned RAR files for archived projects (which is simple but can’t deduplicate between projects).
All of this is basically just best-effort. It’s stored on my local server, and not backed up offsite. It’s not really critical backups - most code is properly versioned in version control systems already, etc. This is more just so I have the ability to quickly recover should I screw up in some way without having to notify the client or set up things again, and so I can make changes that aren’t version controlled (delete and change images and videos for example) happy in the knowledge that I can revert to a previous state if necessary.
I’m not too clear on this aspect yet, but in addition to the above, I want to be able to archive projects eventually - that is, remove them entirely from this backup and from my computer, and store them elsewhere. One of the reasons I chose Duplicati was it was one of the only backup software I found that had the ability to backup, compress and deduplicate multiple files and directories easily on a schedule (I’m amazed how many backup programs only let you backup a specific directory, rather than a set of files and directories), and then later purge a directory from all snapshots (I’ve never actually done it, but I found documentation saying it’s possible)
In an ideal world I’d probably have per-project backups with individual retention settings - i.e. daily for currently active projects, then for archived ones perhaps just keep a few versions or something like that, and have the whole lot deduplicated and compressed as much as possible, then perhaps properly offsite the backups occasionally - but to my surprise I have not yet found any reliable backup software that can do that. I was liking the look of Kopia and really liked their concept of using special ignore files that use the same syntax as gitignore files - that’d easily let me set up ignore rules for specific projects as I generally have to for git anyway - but so far Kopia has proved to be scarily pre-alpha unstable and doesn’t seem to do backups of sets of files - it just does snapshots of single directories, which is too limiting for what I want.
I’m a web developer who works on multiple projects over time. As a general rule, each project can be considered as a single directory within my Work directory. In addition to that, there’s a handful of other related directories and files which are important to projects but can’t be easily split into individual projects - for example, database files and some software and settings configuration files and things like that.
As a general rule, each project contains a large number of files, and there’s heaps of duplication amongst projects. For example, right now I have three copies of the same codebase in three different “projects”, so there’s going to be something like 99% duplication amongst those projects, hence why I need deduplication. The files within each project would normally be a combination of code (i.e. text) and non-compressible things (like jpegs, movies, etc.) so any compression is most likely going to need to work on large numbers of small text/code files.
Duplicati is not ideally what I want, but of the many things I’ve tried so far, it’s the one that comes closest.
The research paper I cited tested the Silesia Compression Corpus, so tested Samba source code, which might be similar to your situation except you have short files instead of a tar file. Hard to find better reports covering all the compressors Duplicati has (I didn’t try searching subsets) and also testing small test files.
Random questions in what appears to be a data compression forum says:
Yes, bzip2 can be better than lzma for small text files (<=900kb).
In these cases, ppmd would be likely even better.
In the paper I cited, the samba source tar file compressed a tiny bit better on PPMd than LZMA, with Bzip2 quite a bit worse but a bit better than Deflate. There were speed differences, but you say it doesn’t matter.
Regarding deduplication, Duplicati deduplicates on fixed blocks with default 100 KB blocksize which is the compression block too. This means that the compressor gets small files (unless you increase blocksize). One time I think I looked to see if such a short file hurt compression, and didn’t come to a firm conclusion.
Choosing sizes in Duplicati talks about the topic. As a rule of thumb, I try to stay below 1 million blocks in backups (otherwise, the database slows down). Larger blocks seem like they might compress better but deduplicate worse. Larger backups might deduplicate better, but if it breaks it’s a bigger repair job or loss.
Totally identical files will deduplicate perfectly. Ones with appends will do very well. Changes in middle will throw off the fixed blocks and hurt deduplication. Some other backup tools try to vary the block boundaries.
Purge of things from all versions is possible, but takes quite a bit of caution, and the UI seems pretty poor. Will Duplicati Delete Newly-Ignored Directories? has some links and comments to give you a feel for that.
You might care about performance of decompress for the total loss, but for less revert, Duplicati will scan the original source path for blocks it can use, and will scan the target path for blocks already set (which is likely most of them), so there might not be a huge amount of fetching of backup files to extract the blocks.
Current Beta is likely plenty reliable enough for current “not really critical backups”, but I always tell people that archive-then-delete is not a great idea with Duplicati. Here’s where I started down that path yesterday:
however your use sounds like Duplicati would not be the long-term archival store, but you just want to get files out of the Duplicati “best-effort” backup someday, and not rely on it as a permanent store with simple retrieval methods for files that are long-gone (maybe at different times), needing special reliability and UIs.
Back to the original question, you probably need to benchmark a bit (or attempt some further web search).