
The 50 MB default would be reasonable, however the link explains why you might want higher, however I think higher would usually be somewhat higher, but not 6000 (without some reason).
Remote volume size is the relevant section for the above setting, but I think the more relevent overall is The block size because the slow SQL in the log is dealing with blocks not volumes.
DELETE
FROM "Block"
WHERE "ID" NOT IN (
SELECT DISTINCT "BlockID"
FROM "BlocksetEntry"
UNION
SELECT DISTINCT "ID"
FROM "Block"
,"BlocklistHash"
WHERE "Block"."Hash" = "BlocklistHash"."Hash"
)
so at default 100 KB blocksize, that means a couple of 10 million row tables in the SQL above.
As mentioned, this tends to not work well with the default 2 MB memory cache (which we can maybe increase if you can spare memory). Using a 1 MB blocksize cuts DB rows by 10 times, however it can’t be changed on an existing backup. Remote volume size can change, but that probably won’t make any difference to the known slow spot. It might help some others though.
300 GB remote volumes (as mentioned in the article) can make for slow restores, as an entire volume must be downloaded to extract even a single byte needed for some file restore, and it potentially could need multiple remote volumes to collect everything to gather all data needed.
Some of this is usage dependent, and you have some really unusual looking source data stats.
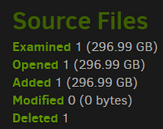
so I guess these are few but big files?
Compacting files at the backend explains the general plan, as some old backups age out.
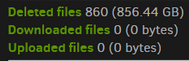
is interesting because this is the version of compact that doesn’t repackage remaining data.
Maybe your files tend to be extremely unique, so block level deduplication isn’t doing much.
If you have roughly 300 GB files with unique data, then compacts might always look like the screenshots above, where one source file goes into a source file then gets deleted later, so damage from being way oversize might not be that much but we don’t know that for certain.
Back to SQL, and don’t worry if the topic is too deep, but this delete area came up in below:
Just looking at the title, you can see that blocks are the concern, and it’s my concern here… Smaller blocksize (like default) save more space, but only if there’s actually duplicated data.
This actually might be a good way to test expanding memory for SQLite cache to gain speed.
I don’t use Docker (or OMV), but isn’t setting environment variables for containers very easy?
That could be a quick test without having to rearrange both of the other settings, or start fresh.