How fast is your internet connection? A remote volume size of 2GB is quite large, so if Duplicati is trying to do a compaction it may have to download/repackage some of those remote volumes.
Normally I wouldn’t change that option from the default of 50MB unless you have a back end that has a limit on the number of files that can be stored.
Regarding the version count, that does seem odd. Normally Duplicati can keep many versions and store them efficiently due to its deduplication feature. Only keeping 1 version seems risky to me. Did you recently deselect a large amount of data for Duplicati to protect? Or delete data it was protecting?
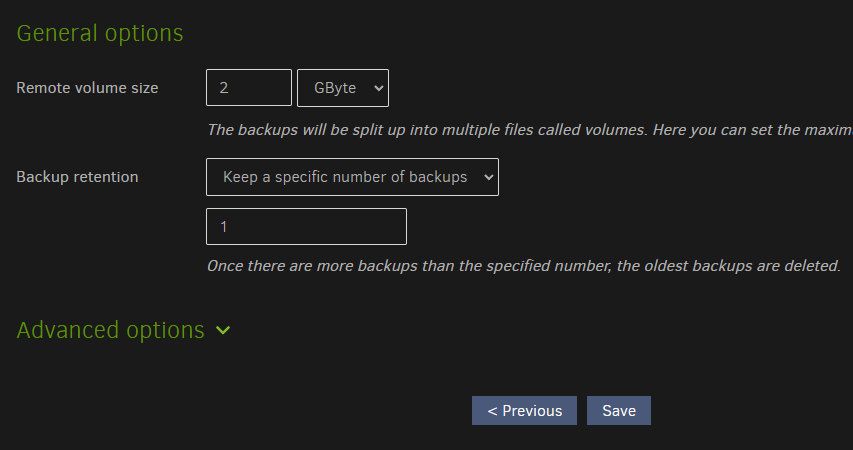
Or recently change the retention setting from its default value of Keep all backups?
You can also look at your log files. Retention setting should be applied after a backup.
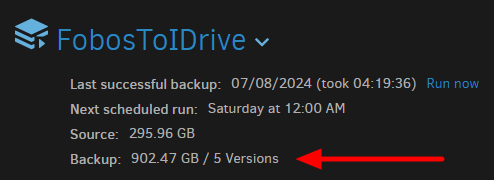
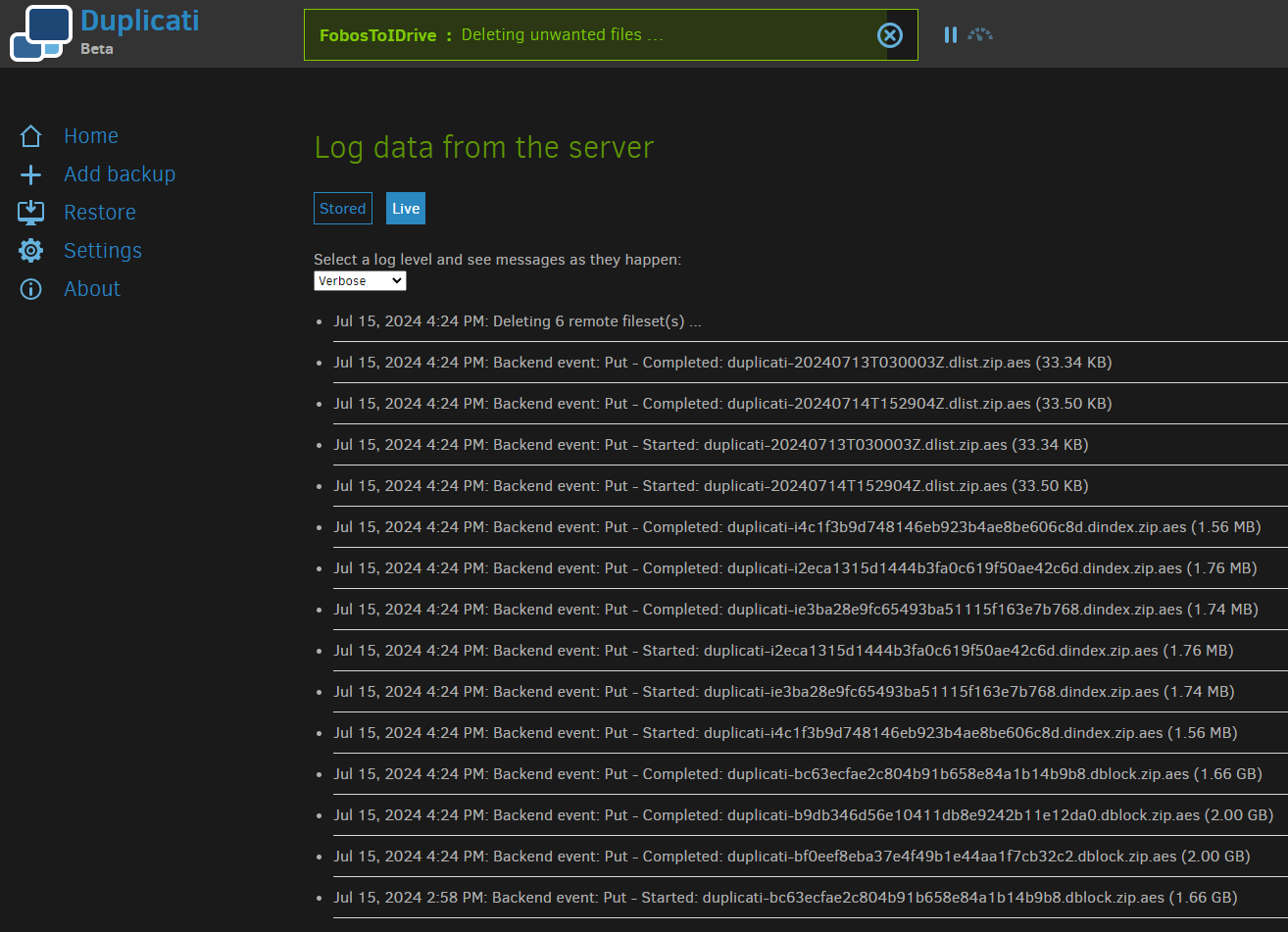
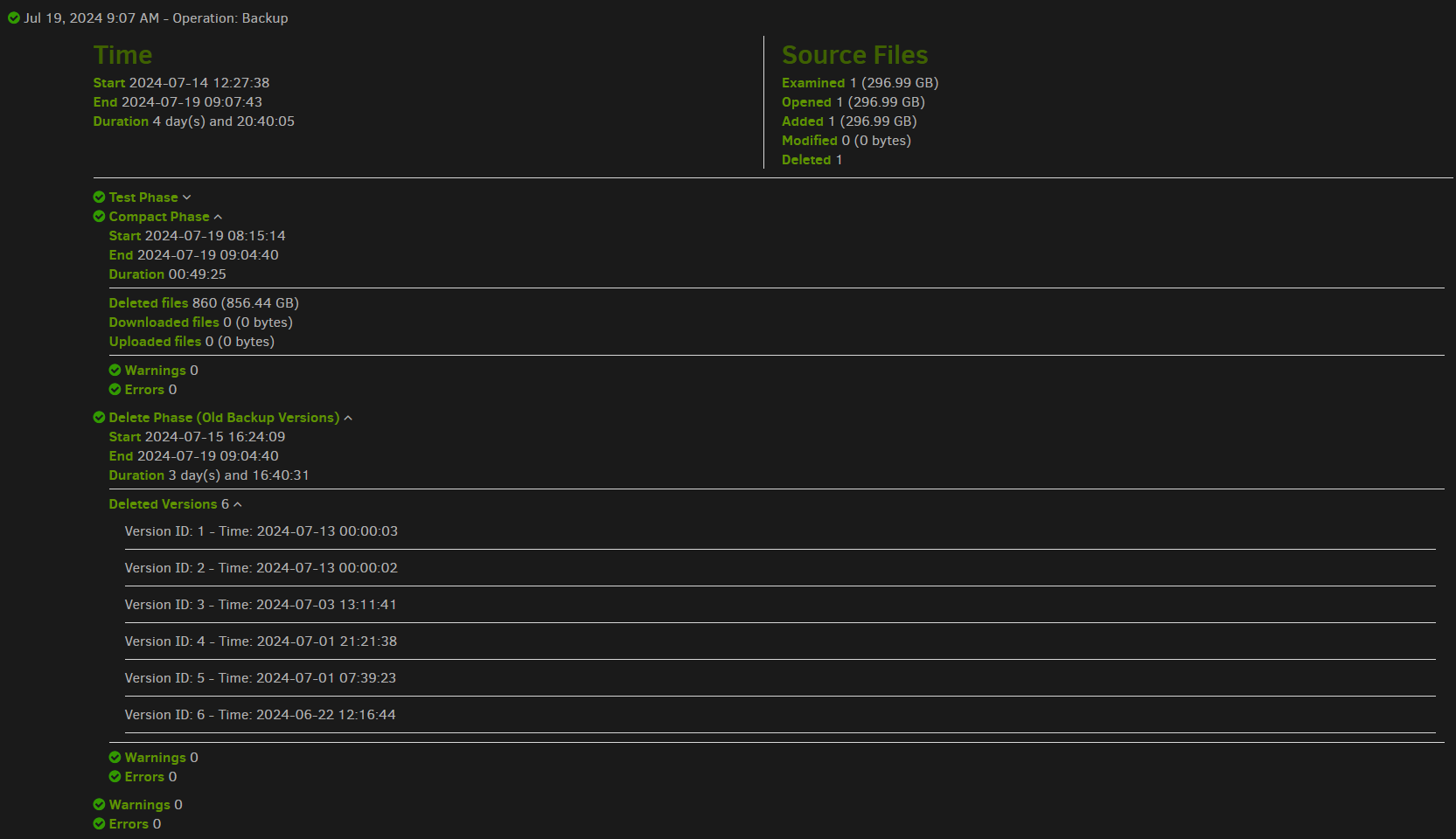
Basically, at the top of the screenshot, seeing it want to do 6 right now seems strange.
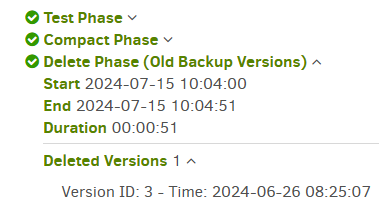
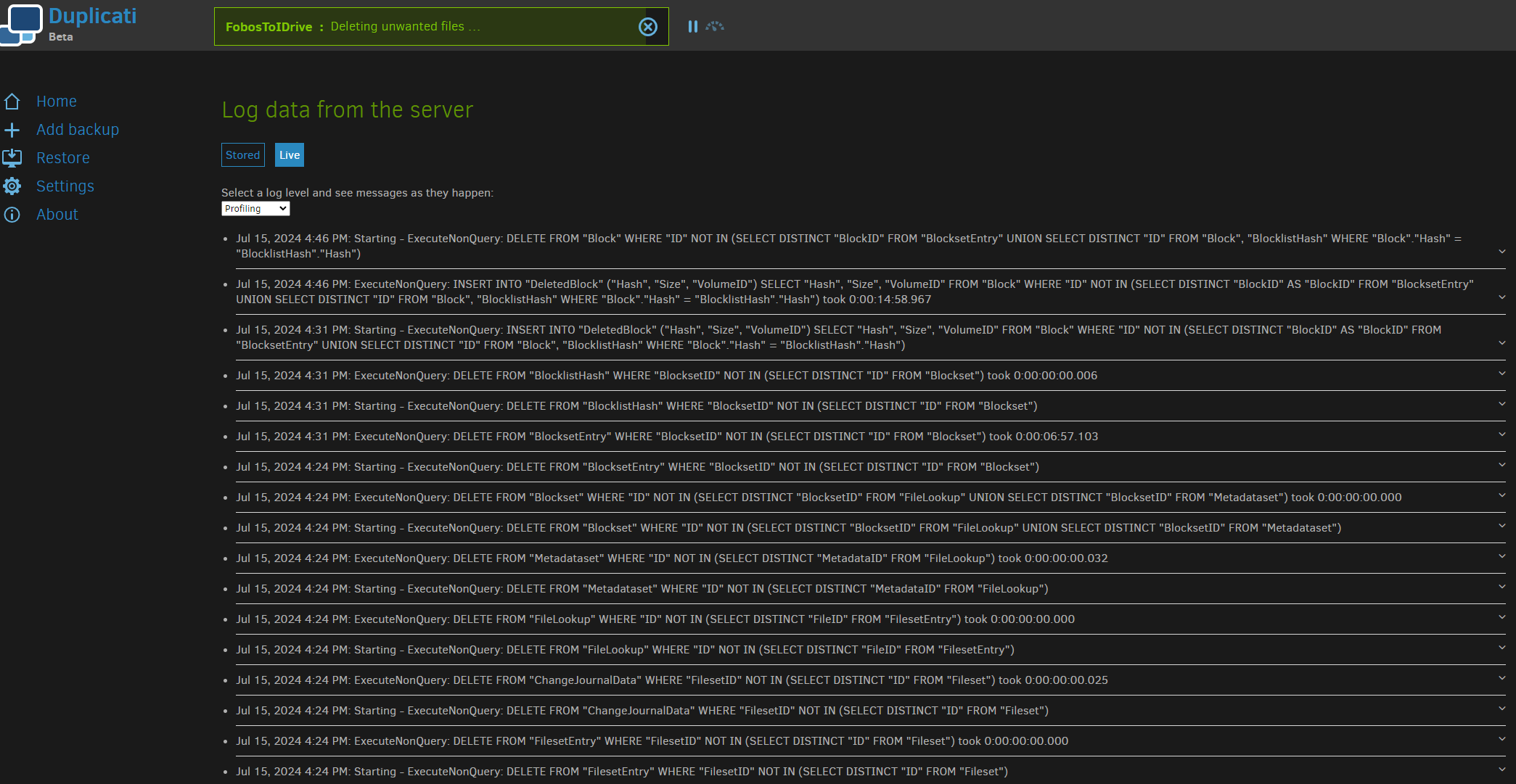
Your job logs show what your backups did, and any deletions that were done. Example:
That sounds like a storage size charge, although they can also charge if egress gets too high. Natural reaction to too much storage would be to lower retention policy. Is that the sequence?
Or are you saying they charged you (but for what?) right in the middle of the current slow run?
What OS is this? You can sometimes distinguish between stuck and slow by resource usages.
Even CPU use would be a clue.
I’m using Duplicati for off-site backup, I also have local backups.
No, but now that I’m thinking, since backup jobs take too long to complete, OMV installs security updates automatically and most likely Docker gets restarted while the backup is still running, leaving “unfinished jobs” behind?
Sorry, I didn’t chose the right words. I’m pretty sure it is not stuck, based on the CPU usage (job started 07/13 at 12:00am and it looks it is still running). Usually the CPU usage is around 10%
Correct, they charged me because I overused my 1TB quota last month. That’s why I have retention set to 1 version.
OK, so it’s no surprise that Duplicati is doing a lot of cleanup on the first job after the change.
Suspicion is that SQLite is having a slow query due to blocksize being left at default 100 KB.
This should be more like 1 MB for a 1 TB backup. The default will be set to that next release.
Can you use ps or top or something that sees per-process stats? Read stats would be best, however CPU at one core’s worth occupied would suggest that SQLite is in some slow query.
I’m not sure if it sees queries retroactively, but there’s About → Show log → Live → Profiling.
EDIT:
iotop, if you have it or can get it (what OS?), might show I/O.
Well, I guess that’s where it’s hard at work… I don’t know why live log sometimes can look back. Somebody who knows the logging code might have an idea. Regardless, nice to see some clue.
I’m not sure what to make of the iotop output. On Windows, Duplicati SQLite can get read rates extremely high at the request-to-OS level, but Windows can answer most from caches not drive.
These were generally SQLite temporary files, with etilqs (sqlite reversed) in the file name, and probably a result of large tables (big backup, small blocksize) and limited SQLite memory cache.
I’m not sure how to see the low level action better, short of running strace on mono. I suppose it might leave some etilqs files visible in /tmp or somewhere, or maybe they’re deleted so invisible.
The lsof command can see files that are deleted but still in use.
Short of waiting it out or giving up and trying to add cache (there’s an environment variable), I’m unsure what the best way is to look deeper, but there are ideas.
The 50 MB default would be reasonable, however the link explains why you might want higher, however I think higher would usually be somewhat higher, but not 6000 (without some reason).
Remote volume size is the relevant section for the above setting, but I think the more relevent overall is The block size because the slow SQL in the log is dealing with blocks not volumes.
DELETE
FROM "Block"
WHERE "ID" NOT IN (
SELECT DISTINCT "BlockID"
FROM "BlocksetEntry"
UNION
SELECT DISTINCT "ID"
FROM "Block"
,"BlocklistHash"
WHERE "Block"."Hash" = "BlocklistHash"."Hash"
)
so at default 100 KB blocksize, that means a couple of 10 million row tables in the SQL above.
As mentioned, this tends to not work well with the default 2 MB memory cache (which we can maybe increase if you can spare memory). Using a 1 MB blocksize cuts DB rows by 10 times, however it can’t be changed on an existing backup. Remote volume size can change, but that probably won’t make any difference to the known slow spot. It might help some others though.
300 GB remote volumes (as mentioned in the article) can make for slow restores, as an entire volume must be downloaded to extract even a single byte needed for some file restore, and it potentially could need multiple remote volumes to collect everything to gather all data needed.
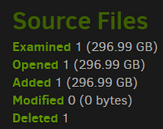
Some of this is usage dependent, and you have some really unusual looking source data stats.
is interesting because this is the version of compact that doesn’t repackage remaining data.
Maybe your files tend to be extremely unique, so block level deduplication isn’t doing much.
If you have roughly 300 GB files with unique data, then compacts might always look like the screenshots above, where one source file goes into a source file then gets deleted later, so damage from being way oversize might not be that much but we don’t know that for certain.
Back to SQL, and don’t worry if the topic is too deep, but this delete area came up in below:
Just looking at the title, you can see that blocks are the concern, and it’s my concern here… Smaller blocksize (like default) save more space, but only if there’s actually duplicated data.
This actually might be a good way to test expanding memory for SQLite cache to gain speed.
I don’t use Docker (or OMV), but isn’t setting environment variables for containers very easy?
That could be a quick test without having to rearrange both of the other settings, or start fresh.
Assuming that the environment variable passes as far as Duplicati, you could set
CUSTOMSQLITEOPTIONS_DUPLICATI to cache_size=-200000 to get 200 MB.
SQLite documentation explains the number as the negative of the kibibytes cache.
Default is -2000, so 2 MB. Expanding by less than 100 times might also speed up.
You can tell if the value gets in by watching About → Show log → Live → Verbose
The message on the bottom line should come out at database opening at backup start.
Actually, there’s only one file of about 300GB generated by a Windows backup app (Easus) I need to backup offsite.
But, now that I’m thinking, probably that’s not the propper use of Duplicati (one single file that most likely will differ in size to what was previously backed up everytime the scheduled job runs).
Being a different size is no problem for deduplication, but if it also looks changed inside from a fixed length block point of view, then deduplication is defeated, so any little change might cause a lot to upload. This works, but is just far more wasteful of bandwidth and limited storage space.
Then we might also need some tool to update it once the files are uploaded (which documentation now says it’s impossible). Because even small backups can grow over time and those TBs are already uploaded at the remote site (and not always feasible to delete and reupload). Or perhaps something, that can dynamically update that.
But it would explain why my database folder has 16GB for my backup sets, the biggest one having half of that
It’s extremely awkward to do, as blocks are identified by their mathematical hash, and these don’t combine mathematically if you combine blocks. You need to have all the data around to read, but it’s on the destination.
If you want an extremely experimental tool with limitations based on above limit, you can test this:
I noticed a huge difference in backup times running them from my laptop directly (Duplicati Windows client) compared to having a different app (was Easus) creating the backup to my NAS (OMV), then having Duplicati do it’s job from the NAS to the cloud storage.
What would be the best approach for large file uploads?