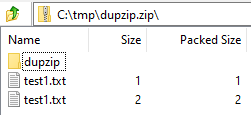
Agree. I don’t know historically whether design of using hash along with size was due to collision worry. Looking at the Block table index set, there’s no index on just hash, although there’s one on hash + size.
CREATE UNIQUE INDEX “BlockHashSize” ON “Block” (“Hash”, “Size”)
UNIQUE INDEX gives me the best confidence of uniqueness, and changes less than the C# code, etc.
Also bear in mind that the one new maintainer is kind of swamped, and good focus on what to fix (and also good preparation such as this) may help get a PR in. I’d note that Duplicati still has integrity bugs, which I’m trying to get handled. You helped on one recently. Thanks. In general though, I’d prioritize as
Writing Quality Code: Practicing “Make It Work, Make It Right, Make It Fast” when picking what to work.
Rules Of Optimization has other thoughts, but at least we got the profiling data for two slow statements:
2023-06-14 13:16:37 -07 - [Profiling-Timer.Finished-Duplicati.Library.Main.Database.ExtensionMethods-ExecuteNonQuery]: ExecuteNonQuery: INSERT INTO “DeletedBlock” (“Hash”, “Size”, “VolumeID”) SELECT “Hash”, “Size”, “VolumeID” FROM “Block” WHERE “ID” NOT IN (SELECT DISTINCT “BlockID” AS “BlockID” FROM “BlocksetEntry” UNION SELECT DISTINCT “ID” FROM “Block”, “BlocklistHash” WHERE “Block”.“Hash” = “BlocklistHash”.“Hash”) took 0:00:41:31.935
2023-06-14 13:58:37 -07 - [Profiling-Timer.Finished-Duplicati.Library.Main.Database.ExtensionMethods-ExecuteNonQuery]: ExecuteNonQuery: DELETE FROM “Block” WHERE “ID” NOT IN (SELECT DISTINCT “BlockID” FROM “BlocksetEntry” UNION SELECT DISTINCT “ID” FROM “Block”, “BlocklistHash” WHERE “Block”.“Hash” = “BlocklistHash”.“Hash”) took 0:00:42:00.328
both of which are awful, but required a very oversized backup plus FUSE. What are the usual delays?
The counter-argument is we’re sort of in this one already, so maybe it’s a good time to just knock it off, however the recipe for getting a pull request accepted is still quite a mystery to me, and I don’t decide.
If we want to press on regardless, I’d say someone needs to test, preferably in Duplicati, and do a PR. Because @tkohhh has the affected backup, the Duplicati to test probably has to get onto that system.
In the above profiling log, a guess would be that the bulk of the time is in the common part of SELECT.
Block table is almost the biggest table, but BlocksetEntry might be bigger, depending on versions kept.
Avoiding doing basically the same probably-slow query is likely going to be a win in this particular case.
Experimenting with code might be possible if one is able to build a change, or it might be possible to do things in an SQL browser to try to simulate steps Duplicati would take. Beware of the OS cache effects.
I’d previously started to chase the “candidate list” idea I proposed vaguely, then better as time passed. Some of that is just my trying to get better with SQL because there’s so much SQL in the code already.
Here are some line-by-line timings from the posted database bug report where FileLookup is FixedFile.
This is using a 2012 vintage Core i5 and a hard drive, so don’t compare times with Unraid’s too closely.
DELETE FROM "Fileset" WHERE "ID" = 807
Result: query executed successfully. Took 2ms, 1 rows affected
DELETE FROM "FilesetEntry" WHERE "FilesetID" NOT IN (SELECT DISTINCT "ID" FROM "Fileset")
Result: query executed successfully. Took 890ms, 32303 rows affected
DELETE FROM "ChangeJournalData" WHERE "FilesetID" NOT IN (SELECT DISTINCT "ID" FROM "Fileset")
Result: query executed successfully. Took 0ms, 0 rows affected
DELETE FROM "FixedFile" WHERE "ID" NOT IN (SELECT DISTINCT "FileID" FROM "FilesetEntry")
Result: query executed successfully. Took 122ms, 8 rows affected
DELETE FROM "Metadataset" WHERE "ID" NOT IN (SELECT DISTINCT "MetadataID" FROM "FixedFile")
Result: query executed successfully. Took 251ms, 8 rows affected
DELETE FROM "Blockset" WHERE "ID" NOT IN (SELECT DISTINCT "BlocksetID" FROM "FixedFile" UNION SELECT DISTINCT "BlocksetID" FROM "Metadataset")
Result: query executed successfully. Took 7274ms, 13 rows affected
DELETE FROM "BlocksetEntry" WHERE "BlocksetID" NOT IN (SELECT DISTINCT "ID" FROM "Blockset")
Result: query executed successfully. Took 6386ms, 26 rows affected
DELETE FROM "BlocklistHash" WHERE "BlocksetID" NOT IN (SELECT DISTINCT "ID" FROM "Blockset")
Result: query executed successfully. Took 4687ms, 4 rows affected
(DELETE FROM "DeletedBlock" so I can see new inserts, write changes so I can test from here)
INSERT INTO "DeletedBlock" ("Hash", "Size", "VolumeID") SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "BlockID" FROM "BlocksetEntry" UNION SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash")
Result: query executed successfully. Took 600802ms, 30 rows affected (early run)
Result: query executed successfully. Took 655989ms, 30 rows affected (later run)
DELETE FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" FROM "BlocksetEntry" UNION SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash")
Result: query executed successfully. Took 120597ms, 30 rows affected (early run)
Result: query executed successfully. Took 100858ms, 30 rows affected (later run)
On those last two statements, one can see the speedup of what I’ve been thinking is OS file caching.
What’s strange is that if I run the SELECT by itself, the best time I can get seems to be 175 seconds.
Still, avoiding doing the SELECT on those huge tables twice will probably save quite a bit of time, but doing it not at all is even faster. Here’s a proof-of-concept of one way. This takes 1 second on my PC,
and it finds the same 30 blocks that can be found by working with huge tables. These are far smaller:
WITH
"TheseFileIDs" AS (
SELECT DISTINCT "FileID" FROM "FilesetEntry" WHERE "FilesetID" = 807
),
"OtherFileIDs" AS (
SELECT DISTINCT "FileID" FROM "FilesetEntry" WHERE "FilesetID" <> 807
),
"MinusFileIDs" AS (
SELECT * FROM "TheseFileIDs" EXCEPT SELECT * FROM "OtherFileIDs"
),
"MinusMetadataIDs" AS (
SELECT "MetadataID" FROM "FixedFile" WHERE "ID" IN "MinusFileIDs"
),
"MinusBlocksetIDs" AS (
SELECT "BlocksetID" FROM "FixedFile" WHERE "ID" IN "MinusFileIDs" AND "BlocksetID" > 0
UNION
SELECT "BlocksetID" FROM "Metadataset" WHERE "ID" IN "MinusMetadataIDs"
),
"MinusBlocksetBlocks" AS (
SELECT "ID" FROM "Block" JOIN "BlocksetEntry"
ON "ID" = "BlockID"
WHERE "BlocksetID" IN "MinusBlocksetIDs"
),
"MinusBlocklistHashBlocks" AS (
SELECT "ID" FROM "Block" JOIN "BlocklistHash"
ON "Block"."Hash" = "BlocklistHash"."Hash"
WHERE "BlocklistHash"."BlocksetID" IN "MinusBlocksetIDs"
)
SELECT "Hash", "Size", "VolumeID" FROM "Block"
WHERE "ID" IN "MinusBlocksetBlocks" OR "ID" IN "MinusBlocklistHashBlocks"