Frustration level approaching critical. Would love to hear an explanation of why it’s worthwhile to continue.
“re-run” presumably means subsequent backup run from where the first was killed. Delete and re-run is also possible, and might be necessary although it might also end the same way if same setting is used. Below are some notes from GitHub issues which make me think this is one of those size overload cliffs.
If it won’t work at these settings, are there any others that you would want to try in the performance runs?
This is probably the pre-backup verification doing the same long operation (SQL looks exactly the same) previously done in the post-backup verification before the kill. I’d still like outputs from performance tools.
There’s no other way to distinguish between hung-while-idle and hung-while-moving-as-fast-as-possible.
Stuck for days on Query with Large Backup set? #2815 looks like it’s a good technical discussion where one core out of 32 was pegged. Some people reached success through newer SQLite (what is yours?), but there was also an attempt to rewrite the SQL. It looks like the fork still exists, but won’t help you now.
Duplicati stuck on verifying backend data #3205 is currently open (unlike above). Reports on CPUs vary.
For do-it-yourself timing of SQL without any of the rest of Duplicati, one can probably use sqlitebrowser. on a copy (for safety) of the database and paste the SQL from the log into the Execute SQL box for its timing.
There are also forum reports that show the same SQL as your two posts, but I haven’t reviewed them…
There is typically very little SQL expertise in the forum these days. Any SQL experts, consider assisting.
If you feel you have enough performance data to understand blocksize issue problem prevention by tuning blocksize, then that might be enough. Or you could try a smaller change from the last one that completed.
sqlite version is 3.34.1
I am fairly certain from the testing done that there’s a performance cliff that larger backups can fall off between 500KB and 1MB block size.
Getting my existing backups off 100K will be a chore.
Duplicati’s default should be changed to 1MB, IMHO. I will open a github issue for this.
I think I will take down my test site now unless anyone has other parameters they need to test. I’ll give this a week.
Thanks for testing. I’m not sure what to preserve. Full profiling logs have pathnames (might be sensitive), however knowing which other queries started to slow might be useful. We seem to know the main culprit.
Database bug report of one of the big-but-finished ones (or maybe even the one that hung) might be good actual test material if anybody actually decides to try to look at the SQL execution time pieces, or fix them.
SQLite seems to lack performance analysis tools that some DBs have, but EXPLAIN QUERY PLAN says
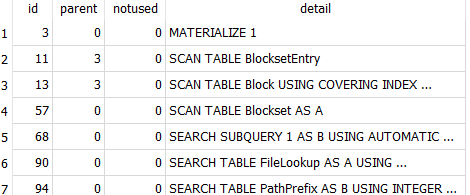
and from my limited SQL knowledge (any experts out there?), SCAN TABLE might be a rather slow thing.
BlocksetEntry will have a row for every block of every file, but some blocks might be in multiple blocksets.
It looks like the backup managed to get past 5 million blocks, so maybe the 1 million block guess was low.
Yeah my last finished successful backup will have gotten to ~7M blocks.
Still, my plan for the future is to guesstimate the size at which my source data will top out and choose a block size that won’t get it over 2.5M blocks.
I might be able to help with this SQL issue if someone can send me a copy of a database where this “hanging” at the mentioned SQL happens.
This offer is hugely appreciated, but I need to work on getting that database, ideally one of the hung ones.
I have nothing, but am hoping that @Kahomono still has something like these to post (or PM if needed):
I tried to make a many-block database out of about 5 GB of data by setting a 1 KB blocksize, but the SQL that was hugely slow in the test here ran quickly, typically under 10 seconds. I did find another slow query:
2021-11-10 13:34:38 -05 - [Profiling-Timer.Finished-Duplicati.Library.Main.Database.ExtensionMethods-ExecuteNonQuery]: ExecuteNonQuery: INSERT INTO "BlocksetEntry" ("BlocksetID", "Index", "BlockID") SELECT DISTINCT "H"."BlocksetID", "H"."Index", "H"."BlockID" FROM (SELECT "E"."BlocksetID" AS "BlocksetID", "D"."FullIndex" AS "Index", "F"."ID" AS "BlockID" FROM (
SELECT
"E"."BlocksetID",
"F"."Index" + ("E"."BlocklistIndex" * 32) AS "FullIndex",
"F"."BlockHash",
MIN(1024, "E"."Length" - (("F"."Index" + ("E"."BlocklistIndex" * 32)) * 1024)) AS "BlockSize",
"E"."Hash",
"E"."BlocklistSize",
"E"."BlocklistHash"
FROM
(
SELECT * FROM
(
SELECT
"A"."BlocksetID",
"A"."Index" AS "BlocklistIndex",
MIN(32 * 32, ((("B"."Length" + 1024 - 1) / 1024) - ("A"."Index" * (32))) * 32) AS "BlocklistSize",
"A"."Hash" AS "BlocklistHash",
"B"."Length"
FROM
"BlocklistHash" A,
"Blockset" B
WHERE
"B"."ID" = "A"."BlocksetID"
) C,
"Block" D
WHERE
"C"."BlocklistHash" = "D"."Hash"
AND
"C"."BlocklistSize" = "D"."Size"
) E,
"TempBlocklist-5B8DA29CA958C54C908C51C566A62CD9" F
WHERE
"F"."BlocklistHash" = "E"."Hash"
ORDER BY
"E"."BlocksetID",
"FullIndex"
) D, "BlocklistHash" E, "Block" F, "Block" G WHERE "D"."BlocksetID" = "E"."BlocksetID" AND "D"."BlocklistHash" = "E"."Hash" AND "D"."BlocklistSize" = "G"."Size" AND "D"."BlocklistHash" = "G"."Hash" AND "D"."Blockhash" = "F"."Hash" AND "D"."BlockSize" = "F"."Size" UNION SELECT "Blockset"."ID" AS "BlocksetID", 0 AS "Index", "Block"."ID" AS "BlockID" FROM "Blockset", "Block", "TempSmalllist-EC4FB09A30DBC943B8DAAF0BB25461DE" S WHERE "Blockset"."Fullhash" = "S"."FileHash" AND "S"."BlockHash" = "Block"."Hash" AND "S"."BlockSize" = "Block"."Size" AND "Blockset"."Length" = "S"."BlockSize" AND "Blockset"."Length" <= 1024 ) H WHERE ("H"."BlocksetID" || ':' || "H"."Index") NOT IN (SELECT ("ExistingBlocksetEntries"."BlocksetID" || ':' || "ExistingBlocksetEntries"."Index") FROM "BlocksetEntry" "ExistingBlocksetEntries" ) took 0:00:36:12.999
Except for me it wasn’t the main culprit, and I don’t know if the query above was slow in the big test here.
Well, this other query is way more complex, not only in shear size but also for the fact that it depends on temporary tables being properly filled with data but I can try to look at it also.
Again, I need a database where the slowness happens.
Backup with a 500K block size - the DB after it hung.
bugreport_backup_500K_blksize.zip
Be patient downloading - it’s >2G
The hangs are probably what I already tore through Duplicati code to find. Its a code issue or would rather require quite a lot of work to truly fix. Based on one above I would say it most certainly is.
Its likely that if you find the files involved in the hang that you can get the hanging to stop by filtering out those files from the backup. The Duplicati DB file for the backup tends to be one as sqlite is a bit funny to code as various issues have to be taken into consideration that it deals with by throwing errors. There should be another way past that (edit - or at least improve it a lot). Performance and backup size on the files where this happens are about the only two biggest differences I didn’t fully test.
But, yeah, the DB is involved and the train gets derailed because it wasn’t coded to handle it. Then another issue with the main code loop (edit - there) in Duplicati doesn’t exit so it hangs.
Your only choice is to workaround it probably by restricting it in some way or using a different backup application. If you are a programmer then you can most definitely tackle the code issues.
(edit - so, I had hangs always on one computer at least 1 per week, sometimes multiple per day, and after eliminating the Window’s AppData folder there are zero issues with all backups running successfully for maybe two months now. If its happening on Linux then you would have to narrow down to what files Duplicati can’t handle there with that computer that you’re trying to backup.)
Absolutely not.
The duplicati DB was not possibly in the source for this backup. The source was entirely on a different filesystem.
The same source was backed up four times without incident, the only change between attempts being a lowering of the blocksize. Started at 50M, then 10M, then 5M, 1M, and when we got to 500K it gagged.
Please change default blocksize to at least 1MB #4629 links to results table showing progressive slowing (somewhat), and then a wall where some SQL just doesn’t finish (for some reason) in a reasonable time.
I can tell you that during the time the SQL was hung, one vCPU was pegged.
My different slow query this morning showed (in Process Monitor) a huge amount of reads on database, which may or may not be normal, with specific reads (recognizable by offset and length) being repeated.
This reminded me of how SQL operations sometimes must scan (not search) the table as listed earlier, however it’s definitely not a definitive analysis. Maybe searching tables also generates same reads a lot.
I looked at it with Process Explorer, saw the SQLite thread (identified by its stack) using lots of CPU time, which wasn’t at all surprising because I was also looking at my profiling log showing a query in progress.
Note that I’m talking about a different slow query here, during an attempt to make my own slow test case.
Backups suddenly taking much longer to complete is me musing on SQLite tunings for larger databases, however I’m way out of my league with SQL in general and SQLite in particular, so thanks for @rsevero.
I am sorry for the late reply. I didn’t see your post before. I’m just getting a 38 MM download in this link. Can you please check if the big backup file is actually there?
Sorry! Older bugreport.
Try this:
I just gave a run of the simplier “hanging” query on DB Browser for SQLite which I reformatted for clarity:
SELECT
"CalcLen",
"Length",
"A"."BlocksetID",
"File"."Path"
FROM
(
SELECT
"A"."ID" AS "BlocksetID",
IFNULL("B"."CalcLen", 0) AS "CalcLen",
"A"."Length"
FROM
"Blockset" A
LEFT OUTER JOIN
(
SELECT
"BlocksetEntry"."BlocksetID",
SUM("Block"."Size") AS "CalcLen"
FROM
"BlocksetEntry"
LEFT OUTER JOIN
"Block"
ON
"Block"."ID" = "BlocksetEntry"."BlockID"
GROUP BY
"BlocksetEntry"."BlocksetID"
) B
ON
"A"."ID" = "B"."BlocksetID"
) A,
"File"
WHERE
"A"."BlocksetID" = "File"."BlocksetID"
AND "A"."CalcLen" != "A"."Length"
First of all I needed to manually run the commands below taken from the Duplicati/Library/Main/Database/Database schema/Schema.sql file as the database @Kahomono sent didn’t have these tables and view:
/*
The PathPrefix contains a set
of path prefixes, used to minimize
the space required to store paths
*/
CREATE TABLE "PathPrefix" (
"ID" INTEGER PRIMARY KEY,
"Prefix" TEXT NOT NULL
);
CREATE UNIQUE INDEX "PathPrefixPrefix" ON "PathPrefix" ("Prefix");
/*
The FileLookup table contains an ID
for each path and each version
of the data and metadata
*/
CREATE TABLE "FileLookup" (
"ID" INTEGER PRIMARY KEY,
"PrefixID" INTEGER NOT NULL,
"Path" TEXT NOT NULL,
"BlocksetID" INTEGER NOT NULL,
"MetadataID" INTEGER NOT NULL
);
/* Fast path based lookup, single properties are auto-indexed */
CREATE UNIQUE INDEX "FileLookupPath" ON "FileLookup" ("PrefixID", "Path", "BlocksetID", "MetadataID");
/*
The File view contains an ID
for each path and each version
of the data and metadata
*/
CREATE VIEW "File" AS SELECT "A"."ID" AS "ID", "B"."Prefix" || "A"."Path" AS "Path", "A"."BlocksetID" AS "BlocksetID", "A"."MetadataID" AS "MetadataID" FROM "FileLookup" "A", "PathPrefix" "B" WHERE "A"."PrefixID" = "B"."ID";
Any ideias why the sent database didn’t contain these tables and view?
I tried the “hanging” query anyway.
As I suspected, the inner most query, with it’s OUTER JOIN/GROUP BY/SUM on a table with more than 14 million lines (BlocksetEntry) against another with more than 14 million lines too (Block) takes too long and, AFAICT, produces tons of unnecessary results as later in the query only the BlocksetIDs present in the “File” view are actually filtered.
To make it faster I just filtered against “File”.“BlocksetID” earlier in this inner most query including an early “INNER JOIN” between the “BlocksetEntry” table and the “File” view.
To be fair, the instant results I’m getting are a direct result of the change I made AND the fact that my “File” view has no lines at all making the entire query return zero lines but as I expect (hope?) that the “File” view will always have considerably less lines than the “BlocksetEntry” table, this early INNER JOIN will always be a powerfull shortcut. Here is the complete query with the new “INNER JOIN”:
SELECT
"CalcLen",
"Length",
"A"."BlocksetID",
"File"."Path"
FROM
(
SELECT
"A"."ID" AS "BlocksetID",
IFNULL("B"."CalcLen", 0) AS "CalcLen",
"A"."Length"
FROM
"Blockset" A
LEFT OUTER JOIN
(
SELECT
"BlocksetEntry"."BlocksetID",
SUM("Block"."Size") AS "CalcLen"
FROM
"BlocksetEntry"
INNER JOIN
"File"
ON
"BlocksetEntry"."BlocksetID" = "File"."BlocksetID"
LEFT OUTER JOIN
"Block"
ON
"Block"."ID" = "BlocksetEntry"."BlockID"
GROUP BY
"BlocksetEntry"."BlocksetID"
) B
ON
"A"."ID" = "B"."BlocksetID"
) A,
"File"
WHERE
"A"."BlocksetID" = "File"."BlocksetID"
AND "A"."CalcLen" != "A"."Length"
Here is the patch the implements the above change in the code: blocksetentry_file_inner_join.patch
blocksetentry_file_inner_join.patch.zip (444 Bytes)
Can someone actually test the code? I just tested the SQL straight in DB Browser for SQLite.
Another thing: are there tests for Duplicati code? I couldn’t find them.
Humm… I just found out that the CreateBugReportHandler drops the missing tables and view, probably to create a smaller database.
If these tables are big enough to warrant being deleted for the bug reports, my “fix” might not actually save time after all.
It would be great to have a complete database so I would be able to test with the complete real data. Does anybody have a complete database big enough to be causing the above query to be too slow?
Probably from the sanitization and maybe some cleanup of thought-unneeded tables. Are they needed?
FWIW just running the slow query on my home-grown multi-block DB bug report only needed FixedFile.
Took 31 seconds, and 6 on second run, presumably due to the relevant data being cached somewhere.
Probably need to consult @warwickmm about the unit tests. There are a lot that run on PR submission.
There might be one more forum regular who builds from source. I’m not set up here to do any such thing.
P.S. you found the table mods already. The issue with an unmodified DB is it’s not particularly sanitized…
I’ll leave it to @Kahomono whether he’s willing to PM one that shows filenames. Log data (especially on clean runs) is pretty harmless (I think). If need be, whole table could probably be discarded for SQL tests.
There should never be any true source file data in the SQL-level representation of the DB as far as I know.
An alternative path might be to try to figure out why my not-particularly-private backup does a query faster.
I’m at about 5 million blocks (although 1 KB blocks) over 22445 files (I just backed up Program Files (x86).
Sorry - the file names themselves are rather descriptive; I need to keep them to myself.
My tests didn’t hit the wall until around 13.6 million blocks. 6.8 million ran just fine, it was only a hair slower than 1.36 million.