Thanks for testing. I’m not sure what to preserve. Full profiling logs have pathnames (might be sensitive), however knowing which other queries started to slow might be useful. We seem to know the main culprit.
Database bug report of one of the big-but-finished ones (or maybe even the one that hung) might be good actual test material if anybody actually decides to try to look at the SQL execution time pieces, or fix them.
SQLite seems to lack performance analysis tools that some DBs have, but EXPLAIN QUERY PLAN says
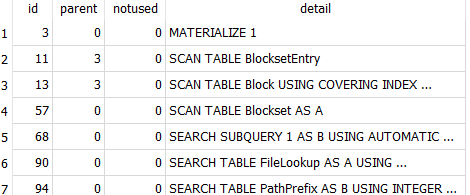
and from my limited SQL knowledge (any experts out there?), SCAN TABLE might be a rather slow thing.
BlocksetEntry will have a row for every block of every file, but some blocks might be in multiple blocksets.
It looks like the backup managed to get past 5 million blocks, so maybe the 1 million block guess was low.