I am currently trying to make a backup with 30GB of Remote volume size, and I have a VM for making this backups with 60GB free hdd space, but it seems like duplicati is fulling it up to the maximum and erroring because of no free hdd space. Also I can not see the duplicati has uploaded anything, so just wondering why the hdd is filing and duplicati is not uploading the data.
Did you also get some big ones? ls -lhS | head might find them. Did you really mean to have the remote files that hold data blocks be 30G? That’s almost a thousand times the default, and by default you queue up 4, per –asynchronous-upload-limit. That 120GB could fill your 60GB of free space. How large is the source?
Choosing sizes in Duplicati talks about the remote volume size, whose option is known as –dblock-size after the name of the files produced. Each dblock file has a smaller dindex file for it. If you see nothing so far, you might be working on the first dblock. 30GB will take awhile. Does your network monitoring show any upload?
What sort of storage type is the destination? Some might show partial files, and others might not show them. Viewing the Duplicati Server Logs at Information level should show you when file uploads start or completes.
I’m not sure what all those small files are. As you can see, the names aren’t very informative. Temporary files get used for various purposes. In some cases, they are also (unfortunately) left around instead of deleted…
Ok now I got it, I didn’t know why my tmp folder was hitting all my disk, I didn’t know that duplicati was waiting by default for a queue of 4 before uploading everything, that is the problem. If I config the queue to 1 element, that would be also fine, right?
My source is more than 6TB that is why I wanted to config it at least of 50GB each file, because if I leave it with 50mb which is the default if I am not wrong, the final destination will end up with thousands of files. BTW my destination is google drive. Also wanted to know if it is normal to only be uploading at 180mbps or less to google drive when I have a connection of 600mbps of upload?
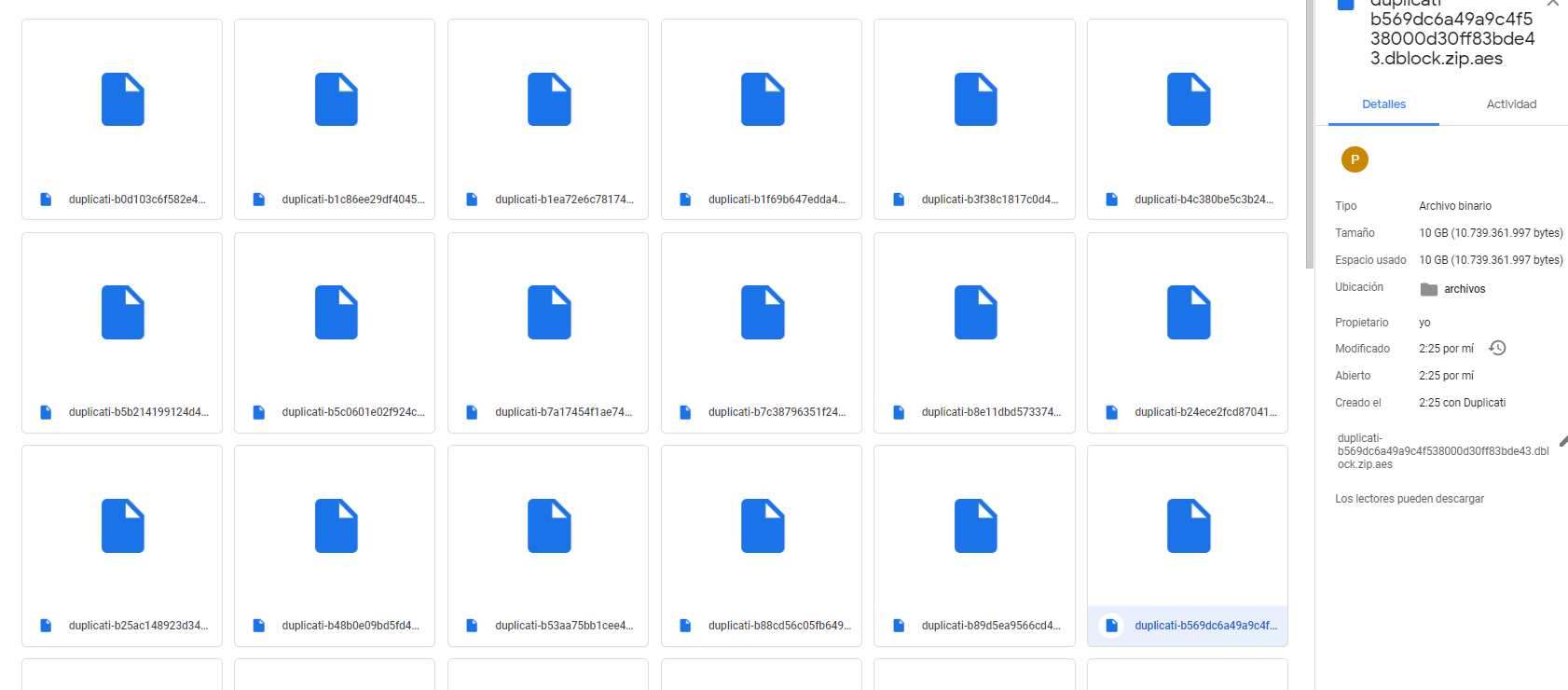
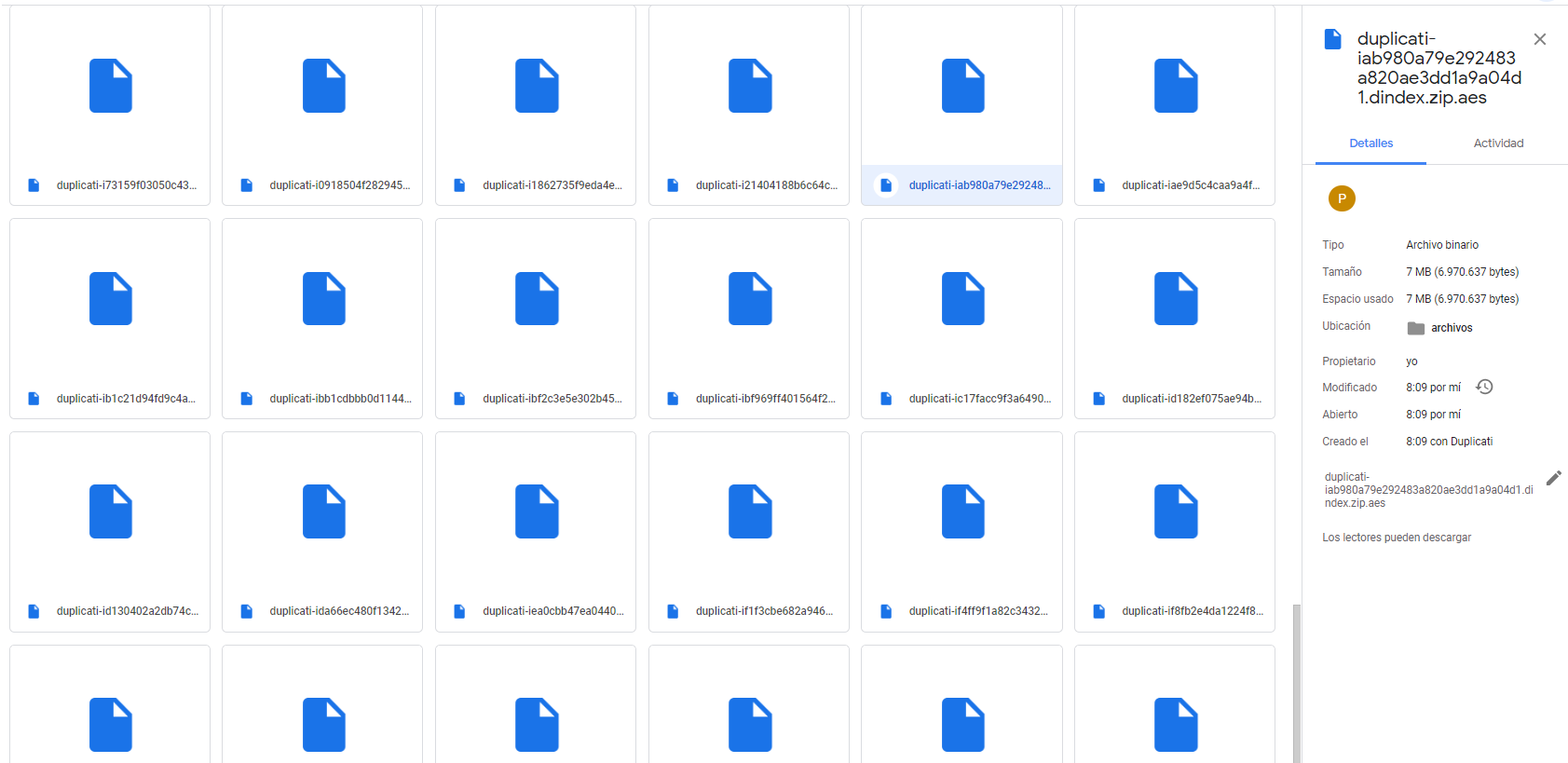
I have been searching and on google drive, it seems I have lots of 10G files, but also a lot of 7MB files, any idea for that?
Should be fine, as far as I know. If somehow you get into a slow spot of generating tmp files, you might miss some upload opportunity by reducing the amount of buffering, but that would merely delay finish of backup.
Yes, it can happen. With some storage types there are limits that one can hit. The 5000 limit that OneDrive either had or still has causes trouble. I haven’t heard much of people finding a Google Drive limit, however enormous numbers of files (or for that matter, hash blocks --. deduplication chunks of files) cause tracking done with SQL operations on the local job database to grow slow. Scaling for large sources isn’t very good. Sometimes people raise their –blocksize, because the default 100kb means tracking 6TB/100kb=about 64 million hash blocks, and if the database ever needs to be recreated, doing those inserts will be very slow…
Using huge dblock-size can backfire at restore time because file updates are put in whatever dblock file is being produced at the time, so a restore might have to download many of those big files to gather chunks.
Probably reasonable. A single TCP connection can only push so much data out, and Duplicati doesn’t yet have the ability to start parallel upload threads, like some programs do when they try to fill up the network. What sort of single-threaded upload speeds can you get from something else to a far-remote destination?
Names would help. The ones Duplicati makes usually begin with duplicati- and include dblock, dindex, or dlist in the name. The only ones that use --dblock-size are the dblock files. Other files can be large or small.
So you are suggesting me to increase -blocksize as a good practise for big storages, right? How much should I increase it in case my storage continues increasing to 10TB or more?
Well, if I understood correctly this is the con of having big storages, because as you have told me I can not leave the dblock-size as default in 50mb because that will make problems with SQL operations. So this is just something to know, but that it is unfixable. BTW, those files that needs to be downloaded to extract the information are going to be downloaded in the /tmp folder or in the location I want my data to be restored? As I was currently explaining the VM that runs duplicati has only 70GB of hdd, and if a lot of data needs to be downloaded to restore it in a future, it won’t be possible to be done in /tmp.
The only thing I have tried is uploading with google chrome, which hits like 400mbps or more of my actual bandwith, but I assume that is because google chrome can start parallel upload threads, right?
I would refer you to the forum discussion as a good place for ideas, or to continue the discussion. There is a comment from @mikaelmello that sounds like there was some testing done. I don’t know of any official trial.
I think these are decrypted into semi-randomly-named tmp files on their way to regenerating the restored file. –tempdir and other means exist to specify where temporary files are created, if that helps any. I suggest test.
I can’t comment on what your Chrome is doing, and it might possibly depend on JavaScript code from the site. Watching with netstat should show whether you have parallel TCP. Regardless I know of no go-faster controls.
Can’t get lan speeds explains some of the other tasks besides just transfer that Duplicati must juggle, though it’s apparently able to crank out tmp files faster than they can be uploaded. It’s still doing much multitasking…
10GB was seemingly a previous maximum file size for Google Drive, so perhaps Duplicati added a silent cap which hasn’t been changed, as Syncdocs did. This might be a moving target. Google Drive now permits 5TB. With the background knowledge you now have, you could experiment. If it’s capped, you can file an issue for someone to see if they can find the code and raise it, but you might get pushback about its reasonableness.
You can change --dblock-size whenever you like (but it only affect new files). --blocksize can’t easily change.
I strongly recommend against this. Restoring even a single small file will require downloading an entire dblock of 30GB, and potentially multiple ones.
The biggest I’ve gone was 2GB for remote volume size, when doing a backup to a local USB backup drive. A little larger than that would probably be ok. But the biggest I’d recommend for a remote/online destination is maybe 500MB, and usually I’d go smaller (i override the 50MB default to around 200MB for my B2 backups).
The problem on this is if I use 500mb for dblock and I want to backup like 10TB I will be uploading like 20.000 of files to google drive. And we could get to the point of this:
Yes, thats the thing I am currently testing, but testing uploading and restoring more than 6 TB is not that easy
This is not going to be done all the days, but at least I want to ensure that my data is able to be recovered in a future even though if I need to wait 2 days to recover it. At least was searching for sometime of good practices when configuring dblocks and all stuff inside duplicati.
That might work for a single file, but reports have been made of database recreation taking months. You’re fine until you lose the database, then life gets much slower. A direct restore is a faster way to get something back…
Ok, I see, so as far as I am seeing, for such a big backup I shouldn’t lose the duplicati installation or I could deal with months of restore process because of the recreation of the database.
So, as fatal things could happen and I could lose the duplicati installation, do you know where are the important files of duplicati located or how to make a backup of the backup system (duplicati) xDDD
In case I need to restore my backup of 10TB with the original duplicati, what time do you think it will need?
Lets say with my actual config, dblocks of 10GB and blocksizes of 1mb
No estimate. Too many variables including number of versions, system performance, network performance, etc. Also depends on whether it can rebuild your database with just the dlist and dindex files, or it needs all dblocks.
What data is it? Consider splitting the backup depending on the source. Eg. I have a set for recent pictures that runs daily, and one for all pictures that runs monthly. There you can change dblock size, smaller for the first set, larger for the second set.
well at the very end the amount of data is the same, I have already splitted 2 types of backups for my data, but I do not want to start splitting 10Tb or more into 100 backups.
The amount of time for many computer algorithms increases more than linearly, for example square of size, however there’s no orchestrated performance analysis that I know of, so one must rely on anecdotes which admittedly sometimes only show up in the forum when a problem occurs. Ultimately the goal is for you to be satisfied. I would always suggest doing sample restores, so perhaps you can try a large sample, and also a direct restore to get used to the slower situation (due to a partial database build) and to see if speed is OK. Full recreate is by default slower (because it does all versions). Backup retention settings can limit versions. What I do for my own backup is a bit much to ask, but I do a recreate occasionally to see how fast it goes…
Best wishes for successful testing. Feel free to ask questions, but as you can see it’s not a precise science.