I was hoping to get more clarification on the following: I have a large number of dindex and dblock files from an interrupted backup. The backup was close to being completed so they should contain a good amount of data. Unfortunately I have lost access to the original data and these dindex and dblock files are all that remains. There were no dlist files created. I have attempted using the cli recovery tool but get the following error when using the restore command:
Program crashed:
System.InvalidOperationException: Sequence contains no elements
at System.Linq.Enumerable.First[TSource](IEnumerable1 source) at Duplicati.CommandLine.RecoveryTool.Restore.Run(List1 args, Dictionary`2 options, IFilter filter)
at Duplicati.CommandLine.RecoveryTool.Program.RealMain(String[] _args)
Would there be any way to get around this and restore part of my data? I have tried the python script and it seems to not do anything when pointed to my data. Any help would be greatly appreciated!
what do you mean by that ? I hope that you understand that to use this script, you need to download the files from your remote backend and get it on a local drive.
EDIT: I missed the part where you said that you don’t have any dlist files. You can’t hope to recover from a Duplicati backup where there are no dlist files. No list of files backed up == what you have is a bunch of binary data without any pointer to file names. That said, your backup data was the result of a first time backup, otherwise it would have already some dlist files.
If that includes the entire drive with your user profile, then you probably lost the database as well.
Your data is available in default 100 KB blocks if tiny pieces will help without any reassembly map,
which would be from either dlist files or the database. There’s actually a bit of help in the dindex by
having blocklist information which can help form files you could rummage in, but names are in dlist.
Restore Backup with only dblock and dindex files was a similar dilemma, and I remembered a tool
had been made, but I had forgotten that a database was found and it used that, not the raw dindex.
It might be possible (if somebody has the time and skill) to bend an existing tool into just assigning
placeholder names to files, if it can put the files together from blocks (which would be a large help).
Do you do Python? If so, you could be the one who makes the tool you need, with some guidance.
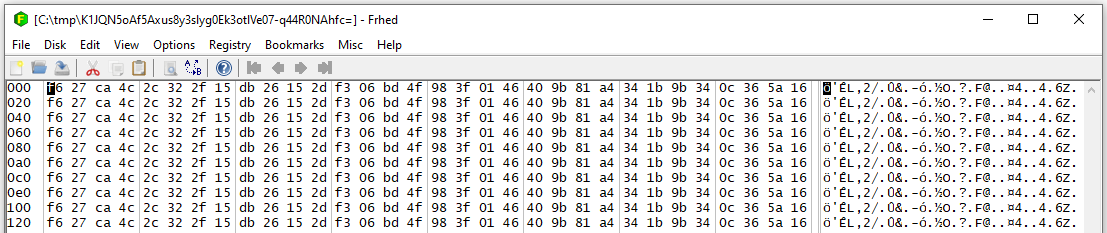
To illustrate, I backed up a ten-block file whose blocks are identified by 32 byte hashes in a dindex.
The blocks are NUL because they’re from a past test, but basically after Base64 it’s a file in dblock. https://cryptii.com/pipes/hex-to-base64 of the SHA-256 f627ca4c2c322f15db26152df306bd4f983f0146409b81a4341b9b340c365a16
is (I’m using their RFC 4648 version which might be the right one – need something filename-safe)
9ifKTCwyLxXbJhUt8wa9T5g_AUZAm4GkNBubNAw2WhY
and here it is in the dblock .zip file:
and grep can also help if you know what strings could help take you to whatever data you’re after.
If you have the space, you could unzip all the dblock files to a folder and go see what you can get.
That would be OK for single-block (default 100 KB) files. Large ones would benefit from assembly however this could be done by concatenating the blocks that you obtained from unzips of dblocks.
Duplicati Database recreate performance has more hints and a Python script if there’s a volunteer
wishing to extend it into a super-emergency recovery tool or maybe someday a blocksize changer.
Changing blocksize might start with what you need, which is extracting your existing files, however
blocksize change (which you don’t need here) would also require repackaging them into new ones.
Is this still of interest? One bit of somewhat good news is I found a program TrID - File Identifier that can guess-add a file extension for formats it knows.
You’d still be on your own with inventing file names and sorting out versions.
You’d get every version of every file (basically the entire backup) to sort out.
This also assumes that the unfinished backup has no other problems with it.
My understanding of what’s maybe “normal” is also evolving as I look at this.
Part of my hope here is to be able to find “not-normal” quickly to quickly look.
User seems to have lost interest, so recovery tool will not be pushed further until someone cares.
Below is what there is so far, and it might have other uses, e.g. if other restore methods disagree.
This one is very straightforward partly because it has to NOT read dlist. It reads dindex blocklists,
basically taking care of the problem of how to put blocks in right sequence to make the large files.
It also has the user do some manual decrypt and unzip. Some duplicates might occur, but ideally
the content of the same file name is the same. If any difference is seen, that would be concerning.
It grew up on Windows (which surprisingly does have a tar command), but is probably portable…
Hey I’m interested in this. For some reason, my entire backup folder on google drive has everything BUT the dlist files, no idea why this flaky backup software never included those. I tried using the Python script but is seems to do nothing even after following the instructions included in the comments of the file… Do I have to unencrypt all the files first, if so how would I go about that?
“# If your files need decrypting, decrypt with AES Crypt or SharpAESCrypt.exe.”
AES Crypt GUI is probably easier if you can run it, else look in Duplicati’s install.
AES Crypt can multi-select in Windows File Explorer, and is on right-click menu.
C:\Users\conta\Desktop\SLS-GoogleDrive>py reassemble6.py
Reassembling large multi-block files
Cleaning up blocks for large files
Cleaning up blocklist file blocks
Cleaning up file metadata blocks
Folder shows GoogleDrive, but all these files are downloaded and copied.
One of the where loops had incorrect syntax according to the interpreter, used just a = so I replaced with a :=. it appears to have worked, but I never really analyzed the code so I’m not sure.
Also I want to apologize if I was rude in my previous responses. I foolishly lost my company logo’s illustrator file so I’m kinda stressed out about that haha, didn’t mean to push that on you.
Okay so I decrypted my files to .zips and re-ran the script. It has the same output as before, but nothing in the file folder. Looking in task manager, it seems it’s only really using 5mb of ram and up to 20% cpu, hardly any disk usage.
Maybe I’m misunderstanding the purpose of this script.
I have a folder with what’s left of my backup (dindex.zip.aes, dblock.zip.aes) I’m missing my dlist files.
In that same folder I have list, block, and file folders and the python script.
The list folder has my decrypted dindex files, the block folder has my decrypted dblock files.
I run the script in-place next to the three folders. It takes time, and seems to be working, about 5 minutes later the script finishes. I check the file folder and there are no files in there, the other two folders has as many files as it did before…
Am I missing something, or would it not do anything if my backup is beyond saving?
Did you prepare the right way, as per example in the script, looking like the example layout above?
You can’t just decrypt and leave .zip files there. There’s content extraction. Did you do all of that?
EDIT 1:
After you prepare folder, it reassembles files per dindex file directions, from blocks in the dblocks.
You have manually extracted the directions into the list folder, and blocks into the block folder.
Files do not have original names, as they were in the dlist files you don’t have, but you have files.
Figuring out what sort of files you have can be attempted using a file identifier program, e.g. TriD.
This sounds like you didn’t set things up. Do you see any of the same names in list and block?
One way to test is to copy all block somewhere, then try to copy in all list. Should be a lot of dups.
There’s certainly a small chance that things are so bad there are no dups, but it seems unlikely…
EDIT 2:
Here was my setup before a run. You can check some of the files in list to see they’re in block:
Quoting the instructions in the script. I literally copied and pasted (excluding the comment at end):
# Example:
# for %i in (*.dindex.zip) do tar -xf %i list/* (ignore list not found error)
# mkdir block
# cd block
# for %i in (..\*.dblock.zip) do tar -xf %i (delete manifest, if you wish to)
# cd ..
# mkdir file
# Run the script by typing its name. It runs quietly, but inspect for errors.
I’m really displaying my poor reading comprehension right now, sorry.
Extracting the files from the zip now, it’ll take a bit, but just to make sure… The dblock archives are pretty self explanatory. As for the dindex files, I’m guessing what I really need from those are the files in the list folder of each archive?
So it would be resulting in the block and list folder having only files with a base64 looking unique id as the filename and no file extension? That’s what I gather from your directory tree example, but I just want to make sure.
Got it to work, recovered over 7000 files out of 10000. (the other 3000 still have an unknown filetype)
Unfortunately, the specific file I was looking for wasn’t among the 7k.
Besides that, your python tool is really good, would be cool to see it worked into Duplicati as a potential recovery method.
Correct. There are other ways to do that, but the easy one is to just ask for the list folder as tar -xf %i list/*. Since you used a few technical terms already, I’ll describe it further…
What I referred to non-technically as “directions” identifies blocks by their SHA-256 hash, in
the required order. That’s why the script reads 32 bytes (256 bits) at a time, then gets block.
Very close. Blocks are kept as files in a .zip, but because a file name can’t be raw SHA-256,
Base64 is done first. Duplicates sometimes occur due to reuses, but “unique id” is very close.
I guess that means TriD couldn’t figure it out. There are other possible ways to look based on format.
is maybe not recognized by TriD. Can you make a new test one to see if TriD can identify it properly?
In a brief web search, I tried to find Illustrator’s format, got general info, but the format seems to vary. Pdf vs Ai gets deep, however the possibility remains that your file got identified as another extension.
Possibly true, but how do you know for sure? I guess it depends on how hard you want to try to find it.
Regardless, thanks for giving this emergency-use tool a try (and finding a typo – maybe I’ll fix upload).
EDIT: Searching for strings, e.g. with findstr, might be an option, if you know what Illustrator might use.
I should say that small files (100 KiB or less) don’t need reassembly, so look in blocks too.
I don’t know if there’s any chance that an Illustrator file would be so small. I don’t use that.
.Ai files are embedded in Pdf, so are identified by a tool such as ‘file’ (Linux) as pdf files. So they are essentially text files, and contains the string ‘illustrator’. Quite easy to search indeed.