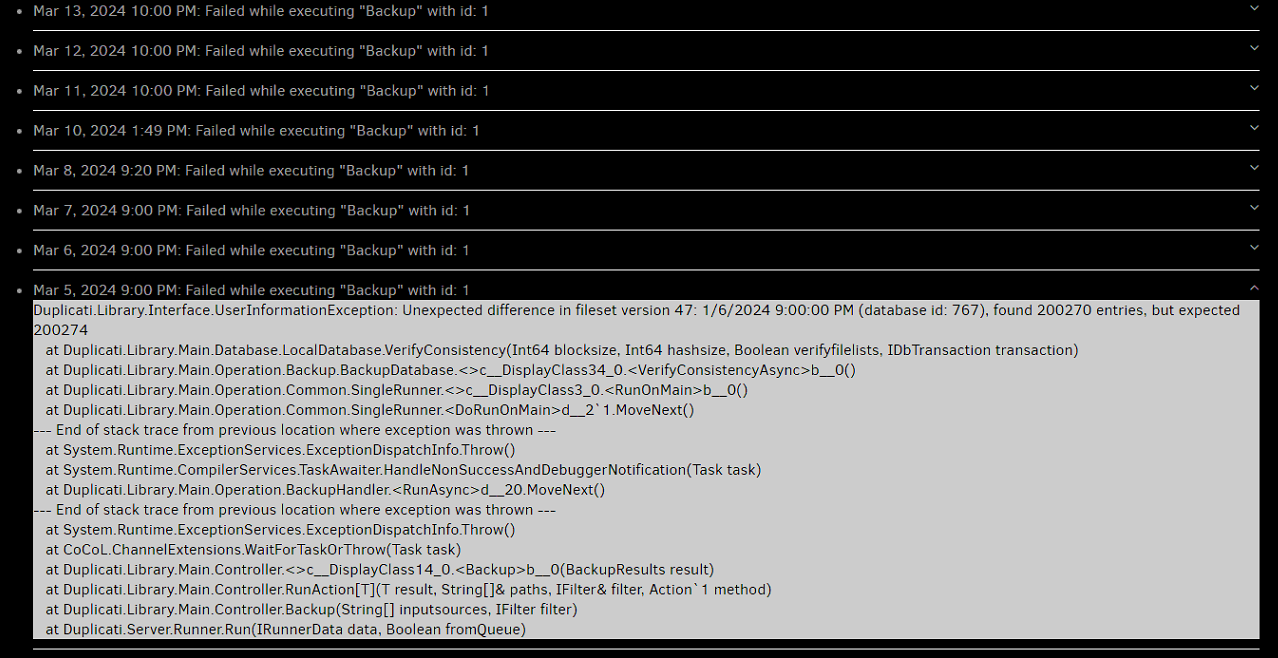
Since my last update (2.0.7.1_beta), to which I was very late installing, I have had an issue with “Unexpected difference in fileset”. Whenever I get this my usual process is to just delete the offending version. This does not work anymore. When I delete a version it just jumps to the next one in line and says that one has the problem and continues no matter how many versions I delete… So far my only solution has been to completely delete the backup and start over. Now it has happened. I have a backup that is a little over 700gb is size and is far away through sftp. Rebuilding the database is not an option as that will take weeks to months to complete (based on previous experience). I tried all the tricks I know (not very many). list broken files and purge broken files does not have any results. Finally I got desperate and installed “duplicati-2.0.7.101_canary”. When I run the backup it errors out with this…
2024-03-31 22:31:58 -07 - [Error-Duplicati.Library.Main.Operation.BackupHandler-FatalError]: Fatal error
UserInformationException: Unexpected difference in fileset version 43: 1/9/2024 11:07:40 AM (database id: 768), found 201032 entries, but expected 201036
Unexpected difference in fileset version 42: 1/10/2024 10:03:11 AM (database id: 769), found 200397 entries, but expected 200401
Unexpected difference in fileset version 41: 1/11/2024 10:30:02 AM (database id: 770), found 200634 entries, but expected 200638
Unexpected difference in fileset version 40: 1/12/2024 10:06:13 AM (database id: 771), found 200674 entries, but expected 200678
Unexpected difference in fileset version 39: 1/13/2024 7:35:32 AM (database id: 772), found 200545 entries, but expected 200549
Unexpected difference in fileset version 37: 1/15/2024 9:00:00 PM (database id: 774), found 200993 entries, but expected 200997
Unexpected difference in fileset version 36: 1/16/2024 9:00:00 PM (database id: 775), found 201062 entries, but expected 201066
Unexpected difference in fileset version 35: 1/18/2024 9:40:22 AM (database id: 776), found 200714 entries, but expected 200718
Unexpected difference in fileset version 34: 1/19/2024 7:56:36 AM (database id: 777), found 201975 entries, but expected 201979
Unexpected difference in fileset version 33: 1/20/2024 9:00:00 PM (database id: 778), found 201421 entries, but expected 201425
Unexpected difference in fileset version 32: 1/22/2024 9:00:00 PM (database id: 779), found 201883 entries, but expected 201887
Unexpected difference in fileset version 31: 1/23/2024 9:00:00 PM (database id: 780), found 201569 entries, but expected 201573
Unexpected difference in fileset version 30: 1/24/2024 9:00:00 PM (database id: 781), found 201623 entries, but expected 201627
Unexpected difference in fileset version 29: 1/25/2024 9:00:00 PM (database id: 782), found 202436 entries, but expected 202440
Unexpected difference in fileset version 28: 1/26/2024 9:18:16 PM (database id: 783), found 202099 entries, but expected 202103
Unexpected difference in fileset version 27: 1/27/2024 9:00:00 PM (database id: 784), found 202149 entries, but expected 202153
Unexpected difference in fileset version 26: 1/29/2024 9:00:01 PM (database id: 785), found 202061 entries, but expected 202065
Unexpected difference in fileset version 25: 1/30/2024 9:00:00 PM (database id: 786), found 202572 entries, but expected 202576
Unexpected difference in fileset version 24: 1/31/2024 9:00:00 PM (database id: 787), found 202279 entries, but expected 202283
Unexpected difference in fileset version 23: 2/2/2024 7:48:22 AM (database id: 788), found 202312 entries, but expected 202316
Unexpected difference in fileset version 22: 2/5/2024 10:13:03 AM (database id: 789), found 202402 entries, but expected 202406
Unexpected difference in fileset version 21: 2/5/2024 9:00:00 PM (database id: 790), found 201479 entries, but expected 201483
Unexpected difference in fileset version 20: 2/6/2024 9:00:00 PM (database id: 791), found 201627 entries, but expected 201631
Unexpected difference in fileset version 19: 2/7/2024 9:00:00 PM (database id: 792), found 201605 entries, but expected 201609
Unexpected difference in fileset version 18: 2/9/2024 7:36:34 AM (database id: 793), found 201683 entries, but expected 201687
Unexpected difference in fileset version 17: 2/9/2024 9:11:17 PM (database id: 794), found 201649 entries, but expected 201653
Unexpected difference in fileset version 16: 2/10/2024 9:00:00 PM (database id: 795), found 201726 entries, but expected 201730
Unexpected difference in fileset version 15: 2/12/2024 9:00:01 PM (database id: 796), found 201898 entries, but expected 201902
Unexpected difference in fileset version 14: 2/14/2024 7:54:14 AM (database id: 797), found 201946 entries, but expected 201950
Unexpected difference in fileset version 13: 2/15/2024 8:01:40 AM (database id: 798), found 232464 entries, but expected 232468
Unexpected difference in fileset version 12: 2/15/2024 9:00:00 PM (database id: 799), found 234106 entries, but expected 234110
Unexpected difference in fileset version 11: 2/16/2024 9:00:00 PM (database id: 800), found 235199 entries, but expected 235203
Unexpected difference in fileset version 10: 2/17/2024 9:00:00 PM (database id: 801), found 235254 entries, but expected 235258
Unexpected difference in fileset version 9: 2/20/2024 12:21:36 PM (database id: 802), found 235265 entries, but expected 235269
Unexpected difference in fileset version 8: 2/20/2024 9:00:00 PM (database id: 803), found 236450 entries, but expected 236454
Unexpected difference in fileset version 7: 2/22/2024 8:51:39 AM (database id: 804), found 236543 entries, but expected 236547
Unexpected difference in fileset version 6: 2/22/2024 9:00:00 PM (database id: 805), found 236879 entries, but expected 236883
Unexpected difference in fileset version 5: 2/23/2024 9:00:49 PM (database id: 806), found 236891 entries, but expected 236895
Unexpected difference in fileset version 4: 2/26/2024 10:53:15 AM (database id: 807), found 236896 entries, but expected 236900
Unexpected difference in fileset version 3: 2/26/2024 9:00:00 PM (database id: 808), found 231873 entries, but expected 231877
Unexpected difference in fileset version 2: 2/28/2024 8:54:13 AM (database id: 809), found 232111 entries, but expected 232115
Unexpected difference in fileset version 1: 2/28/2024 9:00:00 PM (database id: 810), found 236205 entries, but expected 236209
Unexpected difference in fileset version 0: 3/1/2024 9:28:29 AM (database id: 811), found 237161 entries, but expected 237165
I went back in the logs to the first day this happened and found this…
System.AggregateException: One or more errors occurred. ---> System.AggregateException: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond ---> System.Net.Sockets.SocketException: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
at CoCoL.AutomationExtensions.<RunTask>d__10`1.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<FlushBackend>d__19.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()
--- End of inner exception stack trace ---
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()
--- End of inner exception stack trace ---
at CoCoL.ChannelExtensions.WaitForTaskOrThrow(Task task)
at Duplicati.Library.Main.Controller.<>c__DisplayClass14_0.<Backup>b__0(BackupResults result)
at Duplicati.Library.Main.Controller.RunAction[T](T result, String[]& paths, IFilter& filter, Action`1 method)
at Duplicati.Library.Main.Controller.Backup(String[] inputsources, IFilter filter)
at Duplicati.Server.Runner.Run(IRunnerData data, Boolean fromQueue)
---> (Inner Exception #0) System.AggregateException: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond ---> System.Net.Sockets.SocketException: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
at CoCoL.AutomationExtensions.<RunTask>d__10`1.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<FlushBackend>d__19.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()
--- End of inner exception stack trace ---
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()
---> (Inner Exception #0) System.Net.Sockets.SocketException (0x80004005): A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
at CoCoL.AutomationExtensions.<RunTask>d__10`1.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<FlushBackend>d__19.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()<---
---> (Inner Exception #1) System.AggregateException: One or more errors occurred. ---> System.Net.Sockets.SocketException: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
at CoCoL.AutomationExtensions.<RunTask>d__10`1.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<FlushBackend>d__19.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()
--- End of inner exception stack trace ---
---> (Inner Exception #0) System.Net.Sockets.SocketException (0x80004005): A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
at CoCoL.AutomationExtensions.<RunTask>d__10`1.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<FlushBackend>d__19.MoveNext()
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task)
at Duplicati.Library.Main.Operation.BackupHandler.<RunAsync>d__20.MoveNext()<---
<---
<---
What steps can I take to repair this? I am a tech but not experienced with Duplicati beyond doing basic commands through the GUI.
→ Merlin