OK, drawing inferences about the operations. I was looking at the Timestamp fields, and am concerned by
Isn’t that a jump from Mar 1 to Mar 27 in logs? This version skips job logs when things go wrong. That was the motivation for trying the server log. The Operation table seems consistently there, but lacks the details.
Maybe it’s time to dip a toe in the external log waters to get at least summary info without rollback etc. loss. That could be something hardcoded into Duplicati eventually, but here it’s user and Advanced options, e.g. log-file=<path> log-file-log-level=retry (for starters in case network issues such as were seen are involved).
EDIT 1:
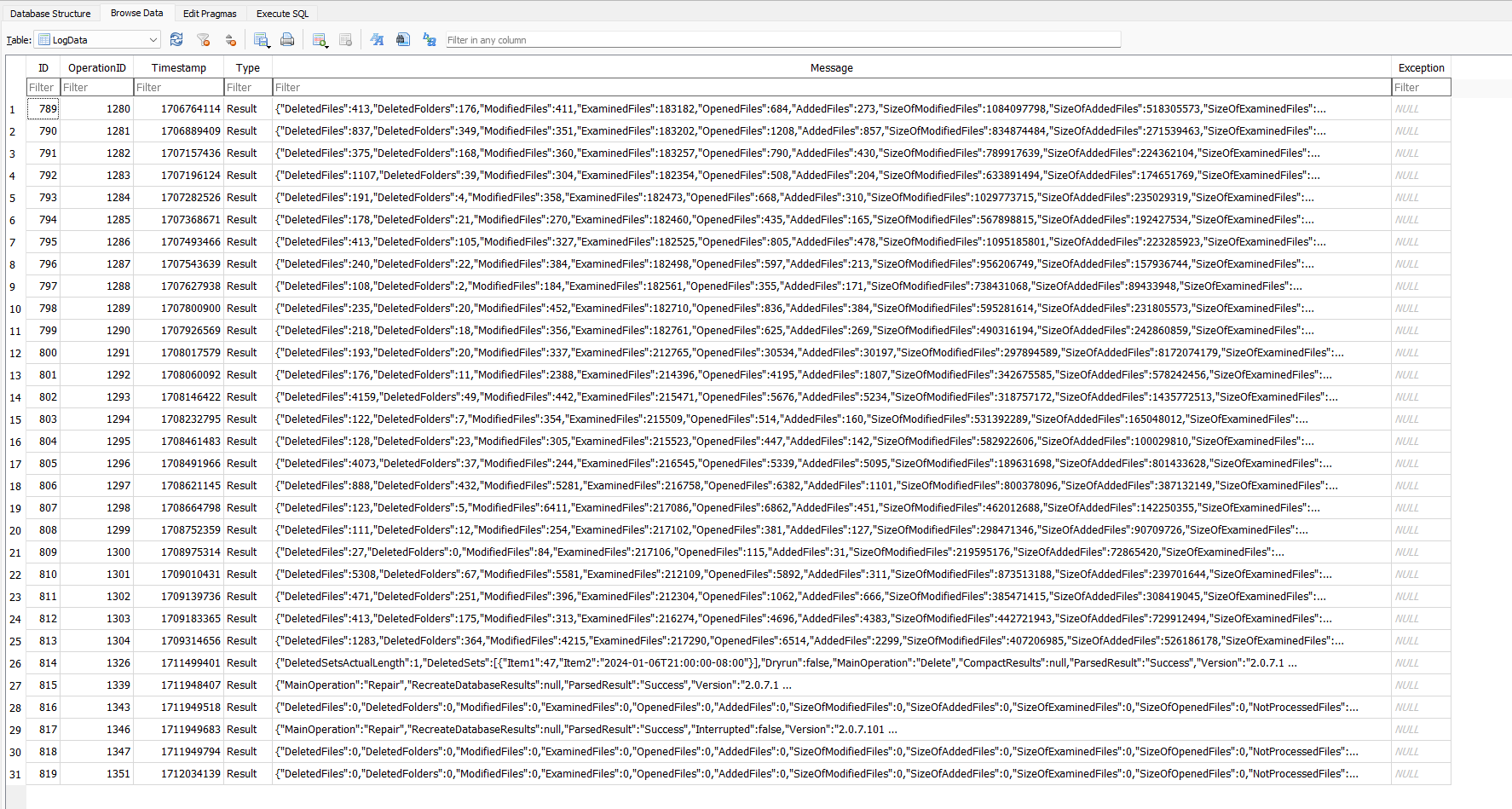
March 27 looks like a Delete, based on DeletedSetsActualLength code (plus the rest of the visible log line).
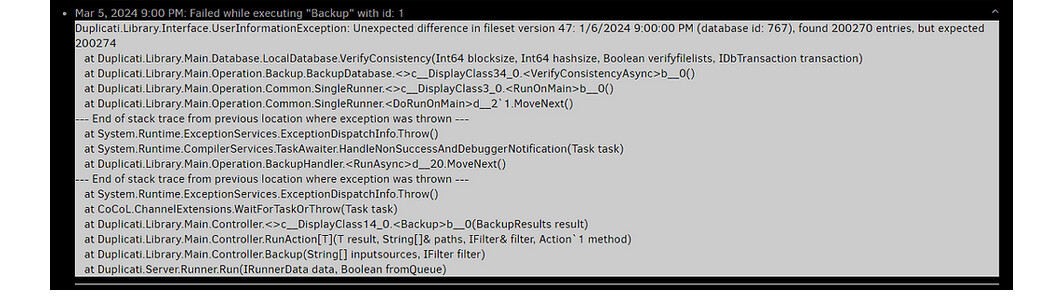
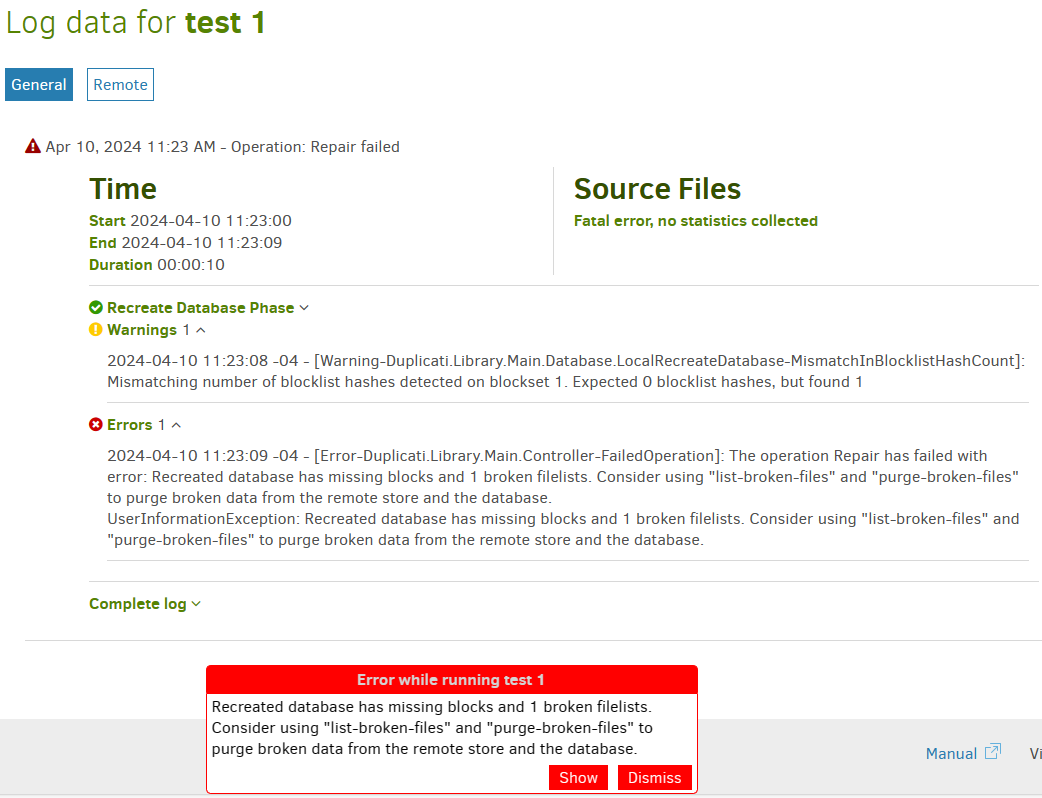
Server log image was posted above and shows several of the failed backups during the gap in the job logs.
I’m not sure that the job logs we want exist, but it hasn’t been 100% proven. There are also the other logs I mentioned, and the files on the destination itself, though that info gets stale as files there change with time.
EDIT 2:
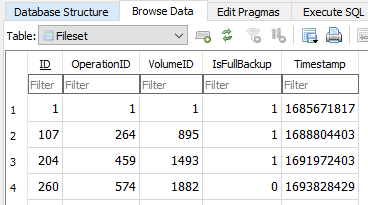
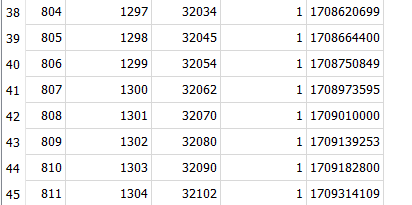
There might be part of that, as OperationID 1304 might be the last valid backup. My prior thought from the server log that March 5 was the first error might be wrong, as default log-retention is 30 days, and no prior server log entries were found. The explanation for why there is a January 31 job log around in the image is (roughly anyway) explainable by its PurgeLogData only running after good backup occurs. Those stopped.
So first failure might have made no job log, because it didn’t in this Beta, and maybe server log aged away. PurgeLogData for the job log also cleans up Remoteoperation table, so we might have that back to Jan 31, assuming we can get anything sent to us somehow, e.g. by Export, or database bug report (possibly slow).
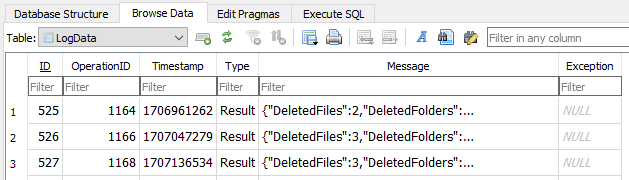
Meanwhile, a copy-and-paste of the Message JSON for OperationID 1304 in LogData would be a nice start.
EDIT 3:
Although it will probably erase some of the job logs for privacy, the database bug report might be runnable in a reasonable amount of time. I tried a 700 GB backup (but with 1 MB blocksize) of roughly 1 million files, and creating the report takes about 50 minutes, with 25 being a VACUUM at the end – added in Canary for better sanitization. Backup is on a portable USB drive, and system itself has a 7200 RPM hard drive that gets busy.
On system with SSD and likely faster processor, their speeds might offset the presumably bigger database (mine is about 3 GB). Compressed bugreport is about 1 GB, but now I’m also worrying about .zip size limit.