Now I try to rebuild our “missing” dialogue…
You wrote:
There are numerous long-term ways to speed it up or avoid the need. Some were specifically stated.
Short-term (as in right in the middle of a run), options are limited, however your OS has some knobs. Knowing what to tweak usually involves looking at performance tools to see how resources are used. Duplicati actually also has various exotic options, but you can’t change options in the middle of a run.
I wrote:
I’ve learned that the backups aren’t prepared well for such a „mountain“ of data and a faulty server
You ask:
Is that suspect for current issue? Is it ruled out? Care to describe? System can of course affect speed. Throwing hardware at rebuild can also be long-term improvement, e.g. SSD is faster than mechanical.
I wrote:
The restore is running on Windows 10 (as VM) on a VMware Host. Unfortunately, the host is a single CPU one with 64GB of RAM and has mechanical HDDs inside. The VM itself is configured with 2 vCPUs and 8GB of RAM.
The task manager shows a CPU load of 5-14%, <40MB of RAM and a speed range from 2 to 40 MB/s. It looks like a living application. : )
You wrote:
I don’t know your current time. This is reverse-chronological, so how long has top one been at the top?
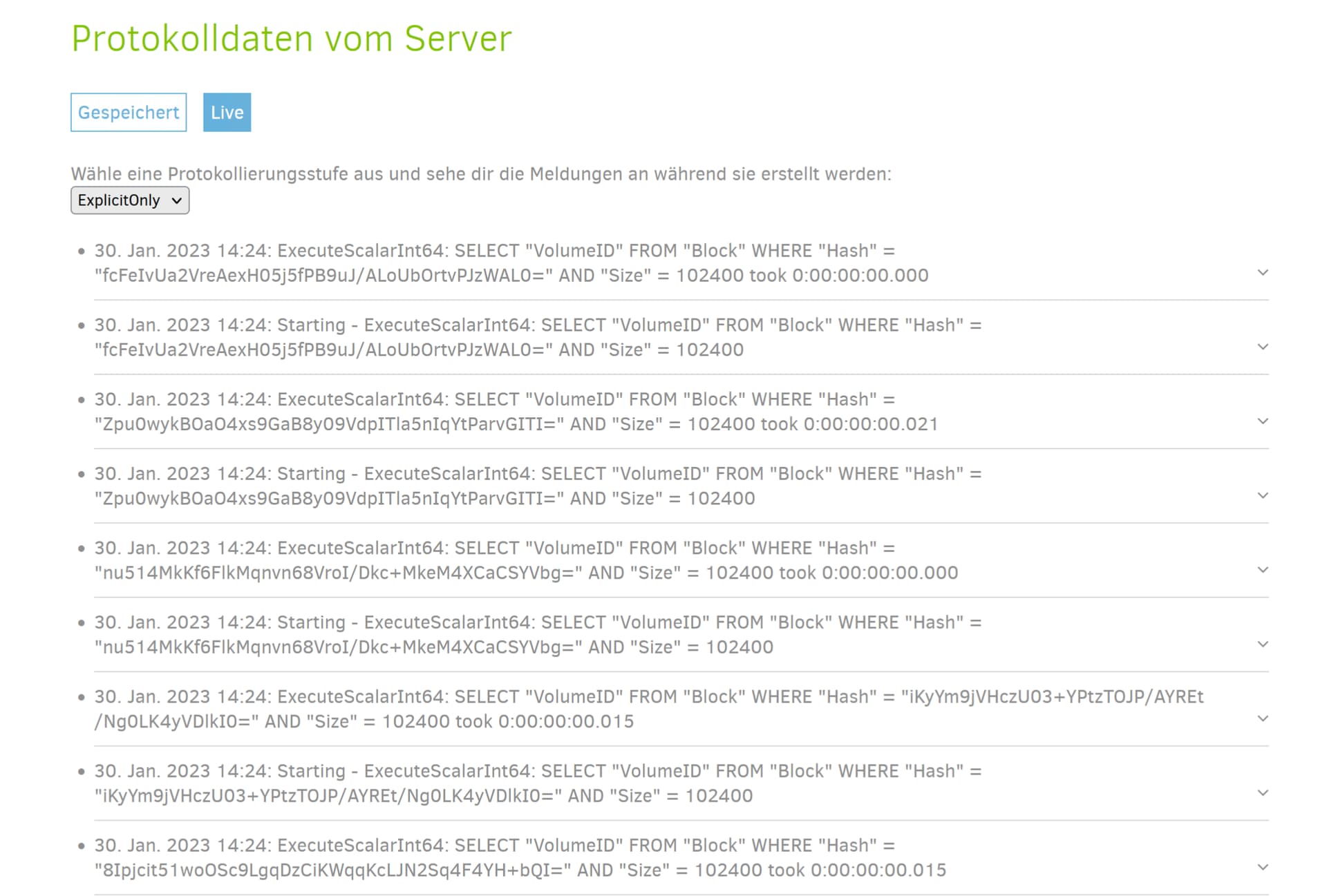
Using ExplicitOnly was not explicitly suggested, but might be doing enough to detect new activity…
I’d have to do some research to see if I can recognize your top message, but if start was around 7, and messages stopped at 14, and restore has run 16 hours, then your current time is 7 + 14 = 21 right now, sitting still for 21 - 14 = 7 hours? Do OS tools show any activity in CPU or disk activity in Duplicati now?
You possibly have an odd hang situation rather than performance issues, but there’s not much data yet.
What OS is this, and are you familiar with performance tools to check for either an overload or no uses?
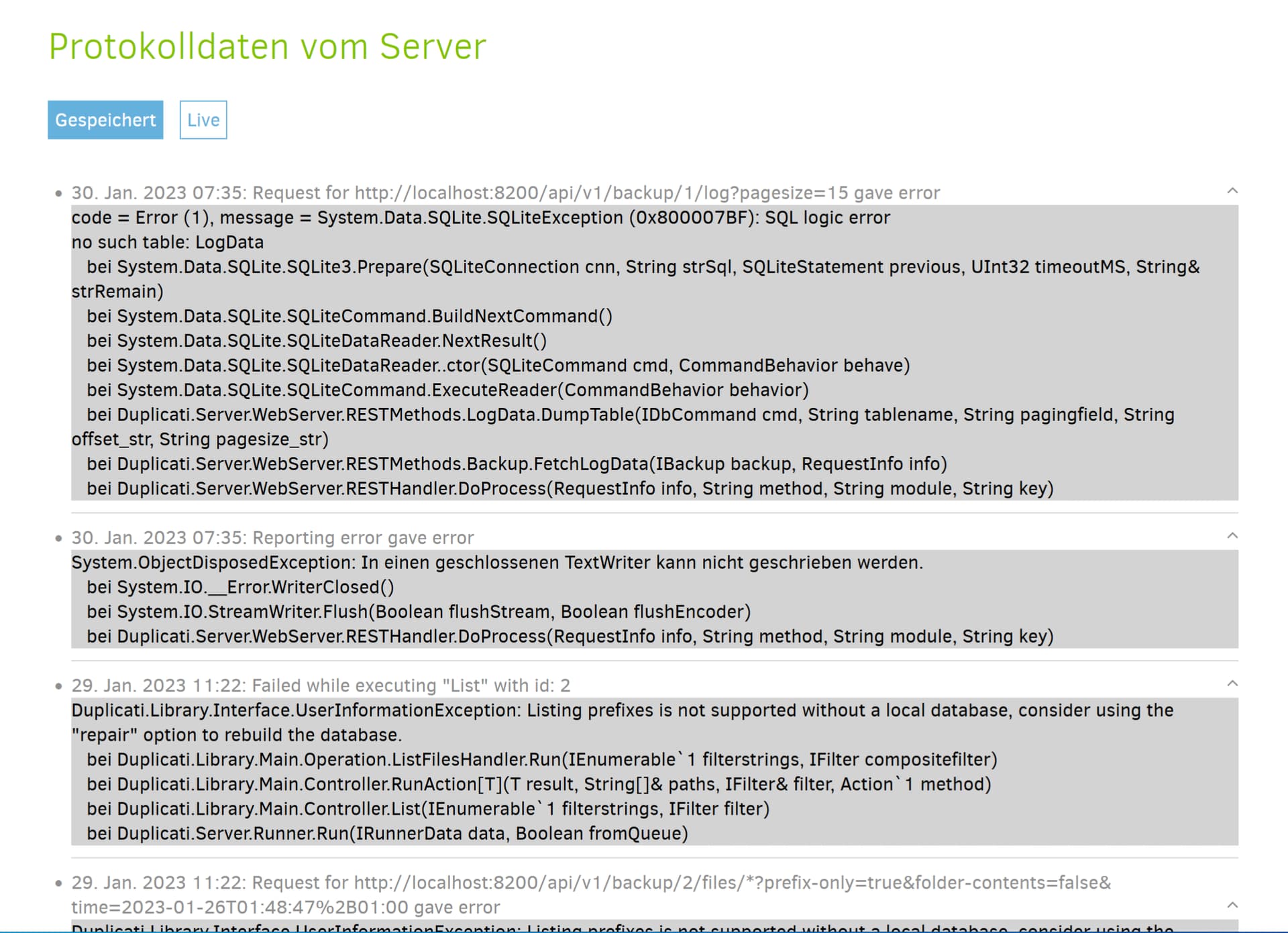
As described above it’s a simple Windows 10 Pro and there is no overload - duplicati is already working. Please have a look on the benchmarks above. Duplicati is the only application running on the VM - and it is - maybe you are right - a hanging situation. Although the log writes some different block information and messages which looks like an application that works through a fog of blocks.
I wrote:
look for another way to recover the files?
You wrote:
I’ve been asking about the old system. No response yet. What’s left of it? What other way do you have?
I wrote:
The old system is/was a Proxmox VM with Debian Linux 10, included as a Samba Domain Member with a 4TB data-partition. After we had some restores to do the server crashed if the load was more than 150GB in a single restore.
The only way we have is to buy a new hardware, let the old system alive in a separated network, scratch all the folders and files which are verified and proof copied on the new server and a NAS.
You wrote:
You should search back in the Live messages
Are you familiar enough with this log to have a good handle on when one can switch levels to get some summarized information, so as to see the forest rather than the trees, but I don’t want to risk trees loss?
Verbose might have given a good compromise-level view. I wonder if any other levels were tried before.
I wrote:
It tried „Verbose“, „ExplicitOnly“ and „Profiling“. The last two options displays some items. The other ones are blank and left blank.