I’m new to Duplicati but I believe this is an amazing tool. I’m trying to do a backup of the files of my persona computer in case of a disaster. So I don’t need to access those files on a daily basis and also I’m running this backup once in a week.
I have configure an S3 bucket GLACIER.
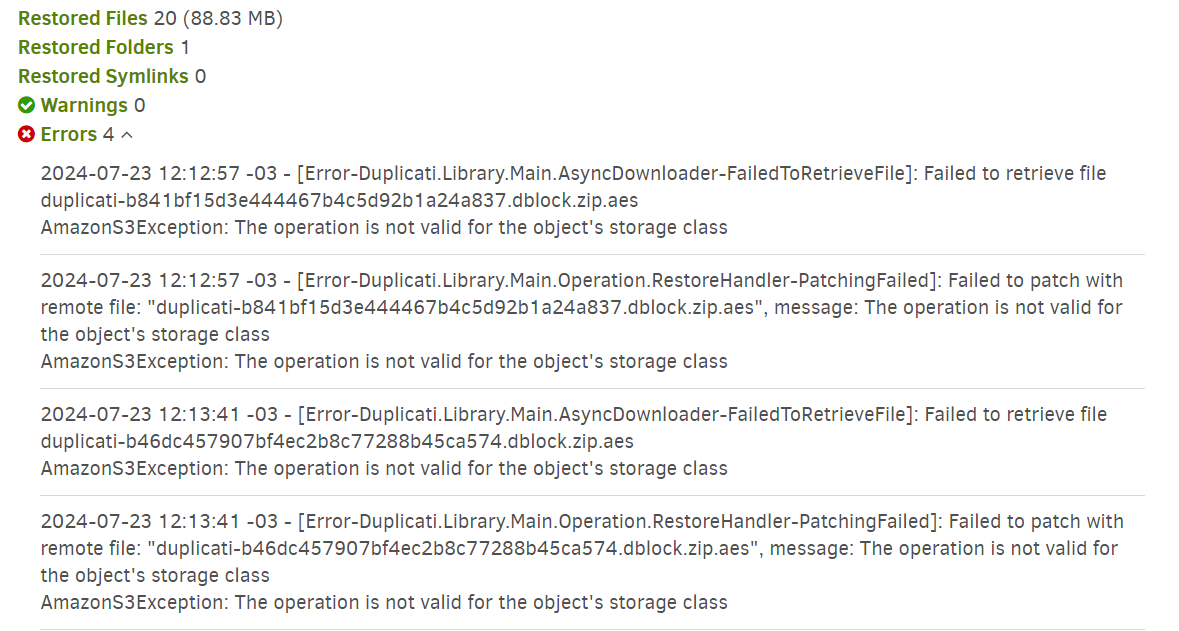
I can do the backup but once I have to do the restoration I have some errors, this is expected because as I understand the GLACIER won’t let instant retrieval. I have 2 questions here:
If the log show errors due to storage type why does it restore all the files anyway?
what’s the correct way of do the S3 setup to have a “hot-backup” and “cold-backup” I was reading this post https://forum.duplicati.com/t/duplicati-and-s3-glacier/13323 but since it is from 2021 I want to know if it’s a more up-to-date way of doing this.
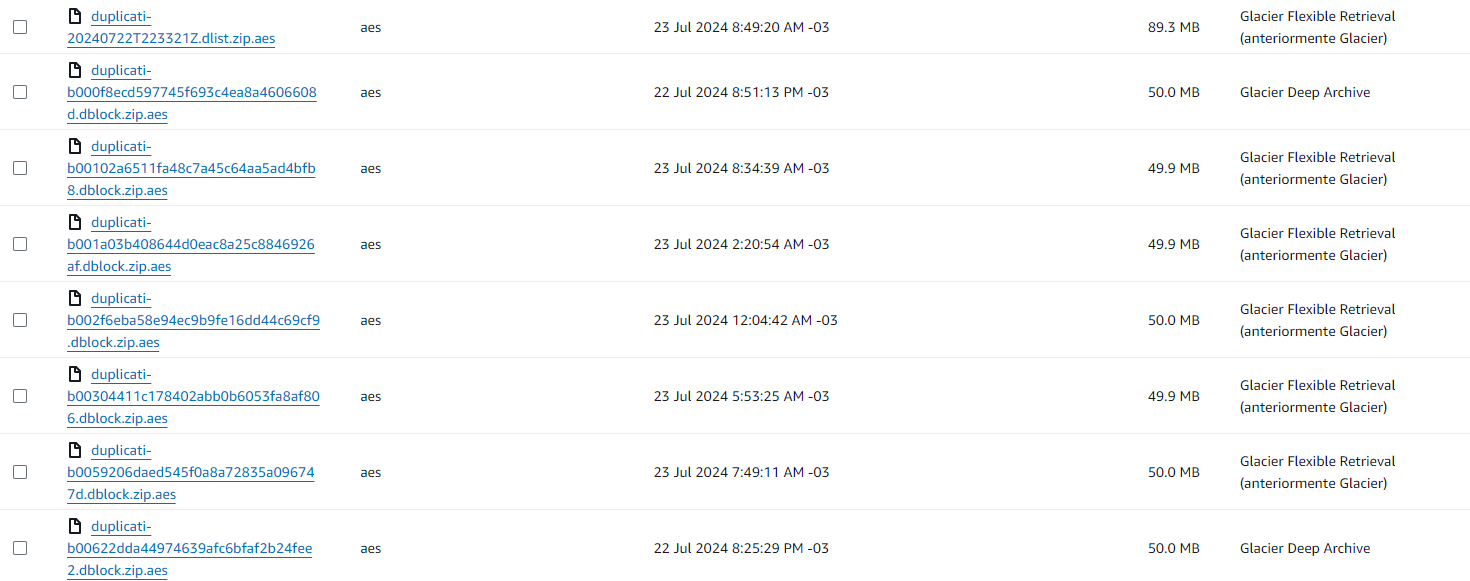
(I’m attaching a capture of S3 type of storage config and some overview of the errors)
Duplicati will by default attempt to verify that data is stored correctly. For most storage options this is a good safeguard that prevents nasty surprises.
But for Glacier, this does not work as the files are not readily available. Quick fix is to disable remote verification, but restore can be tricky.
Hi there !!! Thanks for your answer. Yes I was reading that post also before posting here, what I don’t yet grasp fully is why my backup restore anyways being that errors arise tellig backup cannot be restore due to S3 type.
Also I’d want to know the strategy to use both in Duplicati-S3 to do a single backup once a week and I move/erase older backups from S3.
Duplicati will attempt to use data from source files to minimize the amount of downloaded data. Use this option to skip this optimization and only use remote data.
I think this option is being revised to default to not do that. There are arguments for either way.
Is it move or is it erase? Would move mean move into local storage for cost reasons or similar?
If you’re thinking that each backup is about the same size, that’s not so. Newer build upon prior.
Incremental backups
Duplicati performs a full backup initially. Afterwards, Duplicati updates the initial backup by adding the changed data only. That means, if only tiny parts of a huge file have changed, only those tiny parts are added to the backup. This saves time and space and the backup size usually grows slowly.
The retention can be set in 5 ways:
Keep all backups:
Backups will never be deleted. This is the most safe option, but remote storage capacity will keep increasing.
Delete backups that are older than:
Backups older than a specified number of days, weeks, months or years will be deleted.
Keep a specific number of backups:
The specified number of backup versions will be kept, all older backups will be deleted.
Custom backup retention: Enter your own settings in the text box that appears.
Smart backup retention: retains one backup for each of the last 7 days, each of the last 4 weeks, and each of the last 12 months.
but because versions share data, a version deletion might generate little wasted space (just as its addition used little additional space). Wasted space is normally cleaned up when it builds up, with
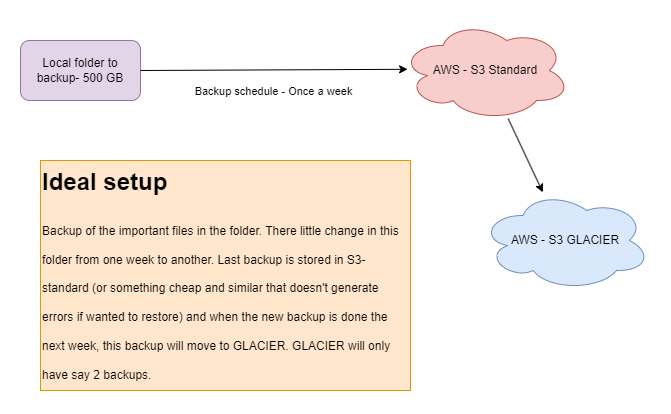
Hi, first of all, thank you very much for responding with so much information on the matter. I realized that I was very brief in my explanation and my needs. I have the disadvantage of being a novice in the two essential areas to achieve what I want (novice in Duplicati, novice in AWS), but I will try to explain as best as I can what I want to accomplish. I made some diagrams to demonstrate this.
As shown in the diagrams, I want to store a total of 2 or 3 backups at most, that is, “latest backup s3-standard (or similar cheap option)” - “penultimate backup s3-GLACIER” and just in case “antepenultimate backup s3-GLACIER”. Due to how GLACIER costs are structured and the early deletion penalty, I would probably accumulate more GLACIER backups in practice, and once they cross the 90/180 day minimum retention period, I would delete them. But in any case, the workflow I want to learn to set up is the initial one I mentioned. Regarding the post you mentioned, I have read it and there are some things I have learned and others that generate doubts, but one thing that comes to mind is: Would it make sense to leave the current backup job (in the diagrams, the current setup) as it is, backing up directly to GLACIER, and only modify the deletion policy I mentioned once the retention days are met, and create a local job to another disk, so in case of data corruption on a disk, my “hot backup” would be this one, and if I have a disaster recovery situation due to system failure, only then would I resort to the “cold backup” in the cloud? Does it make sense or would it be difficult to configure? I want to find the best balance between configuration difficulty and the costs generated by the entire operation. Thank you very much.
This is a bad combination for any complex hazardous schemes. I’m good at Duplicati but not AWS. The person giving advice in the other thread is good at Duplicati. and likely better than me at AWS.
What about ease and costs of restore, short of a full local disaster? Do you expect small restores?
Cold storage is inherently harder to work with, and Duplicati adds to that by not supporting the API for Glacier restore, meaning get files out of cold storage and into something that can be accessed.
Disaster recovery is probably urgent enough that you restore-unfreeze all the files, needed or not. Destination files may become not needed if the entire dblock file has blocks of files not in backup.
Ordinarily the waste would build up, so compact would remove versions and any blocks not used. Cold storage gives this up, so you wind up growing storage use forever and slowing the database.
Cold storage is less expensive, but an unbounded amount of it will run the costs high – eventually.
The “this backup will move to GLACIER” might express the desire, but as mentioned before, there generally aren’t backup versions that stand by themselves. They share data and this saves space.
“little change … from one week to another” means you’ll have a large initial backup, then a weekly backup will probably upload only a little, referencing the older (maybe even initial) backup for data.
People come by the forum asking to delete old files, not realizing that the data blocks are used by current files, when possible. Blocks only turn to waste when no retained version is still using them.
The idea that you can force just hot storage to be used on restore only works if you are certain the data in the file has no blocks that currently exist in the backup and have been sent to cold storage. There is actually another thing that may help, but the no-local-blocks default may change. It’s now:
--no-local-blocks = false
Duplicati will attempt to use data from source files to minimize the amount of downloaded data. Use this option to skip this optimization and only use remote data.
This has the advantage of simplicity and not having to wonder whether restore data is hot or cold. You can also do normal retention and compacts. Basically, it’s a local backup plus a remote copy, possibly just an rclone sync in run-script-after. There might be files that get deleted before getting minimum retention days, but I don’t “think” it’s a penalty in the way it might land on Wasabai. See:
As mentioned, Duplicati backup versions interconnect, so your “just in case” might be broken too. There are recovery tools for slightly damaged backups, but for best safety, use multiple backups – and the more independent the better. A local Duplicati backup and remote clone isn’t independent from a backup integrity point of view, but having a remote copy at all guards against local hazards.
If you’re throwing files onto the remote, I suppose you could throw the local database too, though there’s an argument that you can usually (maybe slowly) recreate the database from remote files.
I mention the database because having all the dlist and dindex files in cold storage will prevent an occasional test that a direct restore from backup files or similar database recreate actually works.
I don’t know how big this backup is. It sounds large enough that storage cost is worth some worry. Generally, anything over 100 GB should increase blocksize in proportion to avoid SQL slowdowns because of too many blocks. Never cleaning up versions or waste also leads to blocks building up.