It would be nice if one of the options when restoring files is to skip files that currently exist rather than just overwrite or save with a new name. I restore directories with 100’s of files in them and had to do a restore today where about 1/2 the files were missing, and my 2 options were to overwrite the existing files, making the restore take way longer than it needed to, or go through and deselect all the files that were still there, taking nearly as long to do as overwriting the files would have.
Welcome to the forum @nachoha
This request seems like it’s for what Duplicati does now, which is to only restore files needing change.
If a file is already as it should be (which does require reading it), there’s no need to restore its contents.
This does confuse people when they see the warning. For one example of that, read Failure to restore.
You can see this for yourself with a small test file. Here’s its About → Show log → Live → Verbose log.
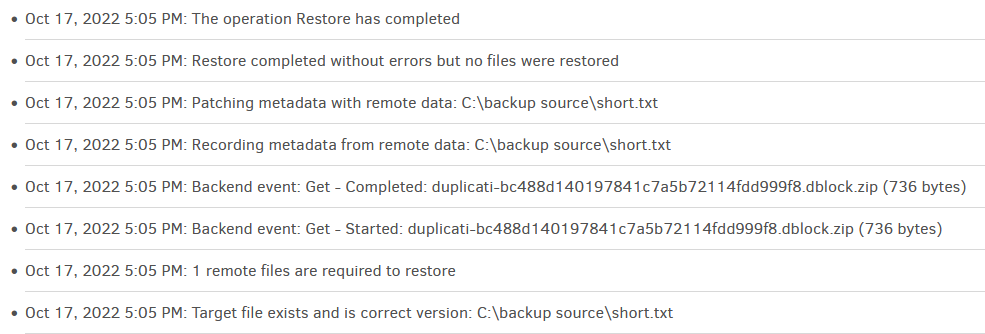
I suppose (in addition to the manual addressing this), the option could say “Overwrite different versions”.

I was more thinking of a skip existing files version that wouldn’t that you could select that if it wouldn’t even try to fetch the file from the backup to compare. For example, you have files 1.txt, 2.txt, and 3.txt in the backup, and file 2.txt in the restore location. Duplicati gets the list of files in the backup, and in the restore location, sees that 2.txt is already there and rather than comparing checksums it skips 2.txt altogether and never touches it in the backup, only restoring 1 and 3. This would I think result in a very large speed increase in cases where for example some files were accidentally deleted, but you know the existing files are fine, and just want to restore the deleted once.
I keep reading the theory here, but at least now it sounds more like a thought. Have you tested anything?
My thought is that it would result in a very small speed increase, in addition to being a very special case.
The very small time it probably takes to look the file over is well worth it IMO, to make certain file is good.
It doesn’t fetch the file from the backup. The local database already has records on what the file contains.
The local file merely needs to be checked against the local SQLite database, and this should be very fast.
Note that Duplicati doesn’t store your file in the backup directly. It backs up and restores at the block level.
Deeper:
How the backup process works
How the restore process works
A block based storage model for remote online backups in a trust no one environment
In the implementation all information is stored in a local SQLite database, with the exception of
the actual data blocks. This enables all queries to be performed locally with SQL commands.
The database is essentially a replica of the remote storage, meaning that it is possible to build
the remote storage from the database and vice versa (excluding the actual data blocks).
When reconstructing files (restoring data), the database is queried to obtain all required blocks.
Initially the destination files are scanned (if they exist) for matching blocks. This enables
“updating” or “reverting” existing folders by only touching required blocks.
Pictures:
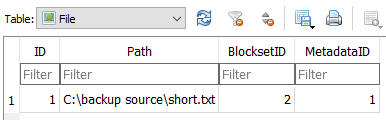
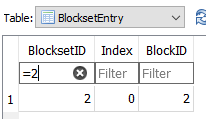
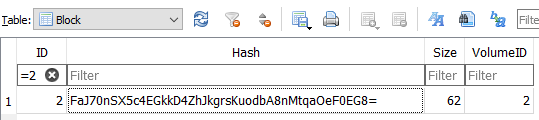
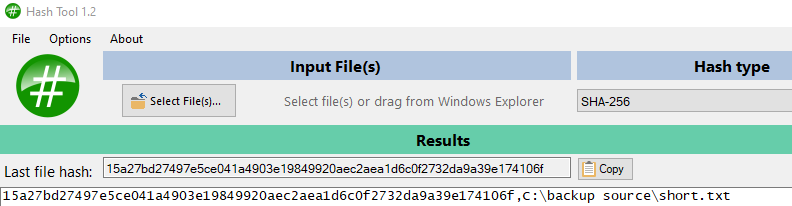
https://cryptii.com/pipes/hex-to-base64
shows Base64 of the SHA-256 Hash of 15a27bd27497e5ce041a4903e19849920aec2aea1d6c0f2732da9a39e174106f
is
FaJ70nSX5c4EGkkD4ZhJkgrsKuodbA8nMtqaOeF0EG8=
so matches the local database. This example uses a one-block file. Multi-block checks more blocks.