I have been testing some Duplicati changes, consequently I’ve had the system running backups very frequently, but I’ve also noticed Duplicati slowing down. Duplicati got to the point where it had over 500 versions but it was taking around 15 minutes before it would start backing up. I investigated further and found that it was running a verification query across each fileset (version) before it started backing up… I then set out to improve the performance of the query.
The query is being run in the LocalDatabase class here (where I’ve added the comment /* here */ to the quote):
if (verifyfilelists)
{
using (var cmd2 = m_connection.CreateCommand(transaction))
{
foreach (var filesetid in cmd.ExecuteReaderEnumerable(@"SELECT ""ID"" FROM ""Fileset"" ").Select(x => x.ConvertValueToInt64(0, -1)))
{
using (var rd = cmd2.ExecuteReader(DBQUERY_CountFilesetEntriesAgainstDataAndMetadataRecordsForTheSameFileset, filesetid))
{
while (rd.Read())
{
var expandedlist = rd.GetInt32(1);
var storedlist = rd.GetInt32(2);
if (expandedlist != storedlist)
{
var filesetname = filesetid.ToString();
var fileset = FilesetTimes.Zip(Enumerable.Range(0, FilesetTimes.Count()), (a, b) => new Tuple<long, long, DateTime>(b, a.Key, a.Value)).FirstOrDefault(x => x.Item2 == filesetid);
if (fileset != null)
/* here */ filesetname = string.Format("version {0}: {1} (database id: {2})", fileset.Item1, fileset.Item3, fileset.Item2);
throw new Interface.UserInformationException(string.Format("Unexpected difference in fileset {0}, found {1} entries, but expected {2}", filesetname, expandedlist, storedlist), "FilesetDifferences");
}
}
}
}
}
}
I’ll go into the details of my performance tuning analysis shortly, but for the backups I’m performing I’ve managed to consistently reduce backup time from around 20 minutes to around 6 minutes. There is also a corresponding significant reduction in server load. I can improve performance further but this would require database schema changes.
I’ll now progress through my analysis so people know what I’ve done.
The original query is as follows:
select
count(*)
from
(
select
distinct "Path"
from
(
select
"L"."Path",
"L"."Lastmodified",
"L"."Filelength",
"L"."Filehash",
"L"."Metahash",
"L"."Metalength",
"L"."BlocklistHash",
"L"."FirstBlockHash",
"L"."FirstBlockSize",
"L"."FirstMetaBlockHash",
"L"."FirstMetaBlockSize",
"M"."Hash" as "MetaBlocklistHash"
from
(
select
"J"."Path",
"J"."Lastmodified",
"J"."Filelength",
"J"."Filehash",
"J"."Metahash",
"J"."Metalength",
"K"."Hash" as "BlocklistHash",
"J"."FirstBlockHash",
"J"."FirstBlockSize",
"J"."FirstMetaBlockHash",
"J"."FirstMetaBlockSize",
"J"."MetablocksetID"
from
(
select
"A"."Path" as "Path",
"D"."Lastmodified" as "Lastmodified",
"B"."Length" as "Filelength",
"B"."FullHash" as "Filehash",
"E"."FullHash" as "Metahash",
"E"."Length" as "Metalength",
"A"."BlocksetID" as "BlocksetID",
"F"."Hash" as "FirstBlockHash",
"F"."Size" as "FirstBlockSize",
"H"."Hash" as "FirstMetaBlockHash",
"H"."Size" as "FirstMetaBlockSize",
"C"."BlocksetID" as "MetablocksetID"
from
"file" A
left join "blockset" B on "A"."BlocksetID" = "B"."ID"
left join "metadataset" C on "A"."MetadataID" = "C"."ID"
left join "filesetentry" D on "A"."ID" = "D"."FileID"
left join "blockset" E on "E"."ID" = "C"."BlocksetID"
left join "blocksetentry" G on "B"."ID" = "G"."BlocksetID"
left join "block" F on "G"."BlockID" = "F"."ID"
left join "blocksetentry" I on "E"."ID" = "I"."BlocksetID"
left join "block" H on "I"."BlockID" = "H"."ID"
where
"A"."BlocksetId" >= 0
and "D"."FilesetID" = 578
and (
"I"."Index" = 0
or "I"."Index" is null
)
and (
"G"."Index" = 0
or "G"."Index" is null
)
) J
left outer join "blocklisthash" K on "K"."BlocksetID" = "J"."BlocksetID"
order by
"J"."Path",
"K"."Index"
) L
left outer join "blocklisthash" M on "M"."BlocksetID" = "L"."MetablocksetID"
)
union
select
distinct "Path"
from
(
select
"G"."BlocksetID",
"G"."ID",
"G"."Path",
"G"."Length",
"G"."FullHash",
"G"."Lastmodified",
"G"."FirstMetaBlockHash",
"H"."Hash" as "MetablocklistHash"
from
(
select
"B"."BlocksetID",
"B"."ID",
"B"."Path",
"D"."Length",
"D"."FullHash",
"A"."Lastmodified",
"F"."Hash" as "FirstMetaBlockHash",
"C"."BlocksetID" as "MetaBlocksetID"
from
"filesetentry" A,
"file" B,
"metadataset" C,
"blockset" D,
"blocksetentry" E,
"block" F
where
"A"."FileID" = "B"."ID"
and "B"."MetadataID" = "C"."ID"
and "C"."BlocksetID" = "D"."ID"
and "E"."BlocksetID" = "C"."BlocksetID"
and "E"."BlockID" = "F"."ID"
and "E"."Index" = 0
and (
"B"."BlocksetID" = -100
or "B"."BlocksetID" = -200
)
and "A"."FilesetID" = 578
) G
left outer join "blocklisthash" H on "H"."BlocksetID" = "G"."MetaBlocksetID"
order by
"G"."Path",
"H"."Index"
)
)
The following diagram shows how these tables are related together in the query. Note that the Duplicati database doesn’t have any referential integrity relationships (foreign keys), I’ve added them to the diagram for clarity… the addition of foreign keys would improve DB integrity, it would also improve performance through less joins being required (demonstrated below)). The table aliases in the query are extremely difficult to follow, so they have been included in the blue notes against each of the tables. Where there are two aliases, the first belongs to the top query (before the union) the second belongs to the bottom query.
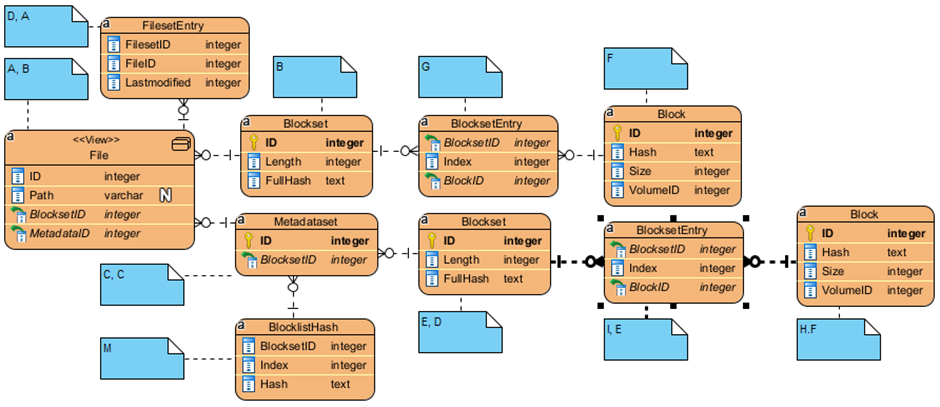
I’ll now discuss how I improved the performance of this query as follows…
Looking at the “where” clause in the top query:
where "A"."BlocksetId" >= 0
and "D"."FilesetID" = 578
These restrict the entire resultset. Therefore A can be inner-joined to D rather than a left outer join. This reduces join work later in the query (as the inner-joined set is smaller). So move D closer to A and change to an inner join. Move these filter criteria to the join criteria.
In the top query, note the left outer join to BlocklistHash. As this is an outer join and there are no filtering criteria, this join does not filter the resultset. Looking at the top-most query, Path is the only parameter required from this resultset and it’s not being provided by the BlocklistHash table. This entire join and therefore the sub-query can be removed.
The left outer join to BlocklistHash in the bottom query can be removed for the same reason as above… thus the entire subquery can be removed.
The two “order by” clauses (top and bottom queries) can be removed – they provide no benefit.
This brings us to this:
select
count(*)
from
(
select
distinct "Path"
from
(
select
"J"."Path",
"J"."Lastmodified",
"J"."Filelength",
"J"."Filehash",
"J"."Metahash",
"J"."Metalength",
"K"."Hash" as "BlocklistHash",
"J"."FirstBlockHash",
"J"."FirstBlockSize",
"J"."FirstMetaBlockHash",
"J"."FirstMetaBlockSize",
"J"."MetablocksetID"
from
(
select
"A"."Path" as "Path",
"D"."Lastmodified" as "Lastmodified",
"B"."Length" as "Filelength",
"B"."FullHash" as "Filehash",
"E"."FullHash" as "Metahash",
"E"."Length" as "Metalength",
"A"."BlocksetID" as "BlocksetID",
"F"."Hash" as "FirstBlockHash",
"F"."Size" as "FirstBlockSize",
"H"."Hash" as "FirstMetaBlockHash",
"H"."Size" as "FirstMetaBlockSize",
"C"."BlocksetID" as "MetablocksetID"
from
"file" A
inner join "filesetentry" D on "A"."ID" = "D"."FileID"
and "A"."BlocksetId" >= 0
and "D"."FilesetID" = 578
left join "blockset" B on "A"."BlocksetID" = "B"."ID"
left join "metadataset" C on "A"."MetadataID" = "C"."ID"
left join "blockset" E on "E"."ID" = "C"."BlocksetID"
left join "blocksetentry" G on "B"."ID" = "G"."BlocksetID"
left join "block" F on "G"."BlockID" = "F"."ID"
left join "blocksetentry" I on "E"."ID" = "I"."BlocksetID"
left join "block" H on "I"."BlockID" = "H"."ID"
where
(
"I"."Index" = 0
or "I"."Index" is null
)
and (
"G"."Index" = 0
or "G"."Index" is null
)
) J
left outer join "blocklisthash" K on "K"."BlocksetID" = "J"."BlocksetID"
) L
union
select
distinct "Path"
from
(
select
"B"."BlocksetID",
"B"."ID",
"B"."Path",
"D"."Length",
"D"."FullHash",
"A"."Lastmodified",
"F"."Hash" as "FirstMetaBlockHash",
"C"."BlocksetID" as "MetaBlocksetID"
from
"filesetentry" A,
"file" B,
"metadataset" C,
"blockset" D,
"blocksetentry" E,
"block" F
where
"A"."FileID" = "B"."ID"
and "B"."MetadataID" = "C"."ID"
and "C"."BlocksetID" = "D"."ID"
and "E"."BlocksetID" = "C"."BlocksetID"
and "E"."BlockID" = "F"."ID"
and "E"."Index" = 0
and (
"B"."BlocksetID" = -100
or "B"."BlocksetID" = -200
)
and "A"."FilesetID" = 578
) G
)
)
A further left outer join to BlocklistHash in the top query can be removed for the same reason as above… thus the entire subquery can be removed.
All return parameters apart from “Path” can be removed from the top and bottom queries as they are not being used by the top-most query… only “Path” is required.
This brings us to this:
select
count(*)
from
(
select
distinct "Path"
from
(
select
"A"."Path"
from
"file" A
inner join "filesetentry" D on "A"."ID" = "D"."FileID"
and "A"."BlocksetId" >= 0
and "D"."FilesetID" = 578
left join "blockset" B on "A"."BlocksetID" = "B"."ID"
left join "metadataset" C on "A"."MetadataID" = "C"."ID"
left join "blockset" E on "E"."ID" = "C"."BlocksetID"
left join "blocksetentry" G on "B"."ID" = "G"."BlocksetID"
left join "block" F on "G"."BlockID" = "F"."ID"
left join "blocksetentry" I on "E"."ID" = "I"."BlocksetID"
left join "block" H on "I"."BlockID" = "H"."ID"
where
(
"I"."Index" = 0
or "I"."Index" is null
)
and (
"G"."Index" = 0
or "G"."Index" is null
)
) J
union
select
distinct "Path"
from
(
select
"B"."Path"
from
"filesetentry" A,
"file" B,
"metadataset" C,
"blockset" D,
"blocksetentry" E,
"block" F
where
"A"."FileID" = "B"."ID"
and "B"."MetadataID" = "C"."ID"
and "C"."BlocksetID" = "D"."ID"
and "E"."BlocksetID" = "C"."BlocksetID"
and "E"."BlockID" = "F"."ID"
and "E"."Index" = 0
and (
"B"."BlocksetID" = -100
or "B"."BlocksetID" = -200
)
and "A"."FilesetID" = 578
) G
)
)
The outer-most top and bottom queries can now be removed, the distinct clauses are moved to their inner queries.
This brings us to (now formatting by hand to improve readability):
select
count(*)
from
(
select
distinct "A"."Path"
from "file" A
inner join "filesetentry" D
on "A"."ID" = "D"."FileID"
and "A"."BlocksetId" >= 0
and "D"."FilesetID" = 578
left join "blockset" B
on "A"."BlocksetID" = "B"."ID"
left join "metadataset" C
on "A"."MetadataID" = "C"."ID"
left join "blockset" E
on "E"."ID" = "C"."BlocksetID"
left join "blocksetentry" G
on "B"."ID" = "G"."BlocksetID"
left join "block" F
on "G"."BlockID" = "F"."ID"
left join "blocksetentry" I
on "E"."ID" = "I"."BlocksetID"
left join "block" H
on "I"."BlockID" = "H"."ID"
where
(
"I"."Index" = 0
or "I"."Index" is null
)
and (
"G"."Index" = 0
or "G"."Index" is null
)
union
select distinct "B"."Path"
from "file" B
inner join "filesetentry" A
on "A"."FileID" = "B"."ID"
inner join "metadataset" C
on "B"."MetadataID" = "C"."ID"
inner join "blockset" D
on "C"."BlocksetID" = "D"."ID"
inner join "blocksetentry" E
on "E"."BlocksetID" = "C"."BlocksetID"
inner join "block" F
on "E"."BlockID" = "F"."ID"
where
"E"."Index" = 0
and
(
"B"."BlocksetID" = -100
or "B"."BlocksetID" = -200
)
and "A"."FilesetID" = 578
)
We’re now down to ~75% of the original execution time.
On both the top and bottom queries, each BlocksetEntry only has one Block… and block is not being filtered or used in the resultset… it can therefore be removed. Oops… no it can’t, this database has no referential integrity therefore, as this is a validation query, the join is required to confirm the record at the end of the BlockId exists… this database needs referential integrity to improve integrity and query performance.
In the bottom query, move the where-clause criteria to the join criteria. Rename the aliases to improve readability. Group the join clauses to improve readability.
This brings us to:
select
count(*)
from
(
select
distinct F1."Path"
from "File" as F1
inner join "filesetentry" as FSE1
on F1."ID" = FSE1."FileID"
and F1."BlocksetId" >= 0
and FSE1."FilesetID" = 578
-- join with data
left join "blockset" as BS1
on F1."BlocksetID" = BS1."ID"
left join "blocksetentry" as BSE1
on BS1."ID" = BSE1."BlocksetID"
-- join with metadata
left join "metadataset" as MDS1
on F1."MetadataID" = MDS1."ID"
left join "blockset" as BS2
on BS2."ID" = MDS1."BlocksetID"
left join "blocksetentry" as BSE2
on BS2."ID" = BSE2."BlocksetID"
where
(
BSE1."Index" = 0
or BSE1."Index" is null
)
and
(
BSE2."Index" = 0
or BSE2."Index" is null
)
union
select distinct F2."Path"
from "file" as F2
inner join "filesetentry" as FSE2
on FSE2."FileID" = F2."ID"
and
(
F2."BlocksetID" = -100
or F2."BlocksetID" = -200
)
and FSE2."FilesetID" = 578
-- join with metadata
inner join "metadataset" as MDS2
on F2."MetadataID" = MDS2."ID"
inner join "blockset" as BS3
on MDS2."BlocksetID" = BS3."ID"
inner join "blocksetentry" as BSE3
on BSE3."BlocksetID" = MDS2."BlocksetID"
and BSE3."Index" = 0
)
Note in the bottom query, the last join for BlocksetEntry is with Metadataset.BlocksetId. It would be more efficient if it joined with Blockset.(Blockset)Id which is indexed… moving the join.
BlocksetEntry is a many join off Blockset. The query is filtering BlocksetEntry by:
- “index = 0” and this will filter out blocksets that don’t a zero-index BlocksetEntry… as this is a validation query I’ll assume the query is trying to confirm that all blocksets have a BlocksetEntry with an index of zero.
- “Index is null” and this will filter out blocksets that don’t have a BlocksetEntry at all. Analysis of the data shows that when a file is zero-length Duplicati will store the blockset but will not store any BlocksetEntries or Blocks. The corresponding zero-length blockset (where blockset.length=0) confirms this observation.
Notice the inconsistency in the above query where the top query uses left outer joins for obtaining metadata whereas the bottom query uses inner joins. It would be fair to assume that the bottom query is correct as all files would contain metadata, so there would never be zero-length metadata. There is a skip-metadata flag in Duplicati that I assume should just create a metadata blockset without any blockset entries or blocks. In looking at the code, I don’t think the skip-metadata option actually does anything, and if it does it only skips metadata for a restore task.
Based on the above I’ll change all the metadata joins to be inner joins.
In the top query, I’ll also move the F1.BlocksetId >= 0 query criteria at the start of each data or metadata join block (you’ll see why in a minute). Similarly, in the bottom query move the F2.BlocksetId query criteria into the metadata join block.
This brings us to the following:
select
count(*)
from
(
select
distinct F1."Path"
from "File" as F1
inner join "filesetentry" as FSE1
on F1."ID" = FSE1."FileID"
and FSE1."FilesetID" = 578
-- join with data
left outer join "blockset" as BS1
on F1."BlocksetID" = BS1."ID"
and F1."BlocksetId" >= 0
left outer join "blocksetentry" as BSE1
on BS1."ID" = BSE1."BlocksetID"
left outer join "block" B1
on BSE1."BlockID" = B1."ID"
-- join with metadata
inner join "metadataset" as MDS1
on F1."MetadataID" = MDS1."ID"
and F1."BlocksetId" >= 0
inner join "blockset" as BS2
on BS2."ID" = MDS1."BlocksetID"
inner join "blocksetentry" as BSE2
on BS2."ID" = BSE2."BlocksetID"
and BSE2."Index" = 0
inner join "block" as B2
on BSE2."BlockID" = B2."ID"
where
(
BSE1."Index" = 0
or BSE1."Index" is null
)
union
select distinct F2."Path"
from "file" as F2
inner join "filesetentry" as FSE2
on FSE2."FileID" = F2."ID"
and FSE2."FilesetID" = 578
-- join with metadata
inner join "metadataset" as MDS2
on F2."MetadataID" = MDS2."ID"
and
(
F2."BlocksetID" = -100
or F2."BlocksetID" = -200
)
inner join "blockset" as BS3
on MDS2."BlocksetID" = BS3."ID"
inner join "blocksetentry" as BSE3
on BSE3."BlocksetID" = BS3."ID"
and BSE3."Index" = 0
inner join "block" as B3
on BSE3."BlockID" = B3."ID"
)
Looking at the above two unioned queries, note that the initial join in both is the same. The top query is made up of two parts which are the collection of data and the collection of metadata. The left outer joins in the collection of metadata don’t restrict the query at all they just provide more information if the join succeeds, but it will only succeed with BlocksetIds > 0.
The metadata portion of the top query brings back all distinct paths with a BlocksetId > 0, and bottom query brings back all distinct paths with a BlocksetId of -100 or -200 (which is everything < 0). As this is the complete set of metadata, the bottom portion of the query can be combined with the top portion as such:
select
count(*)
from
(
select
distinct F1."Path"
from "File" as F1
inner join "filesetentry" as FSE1
on F1."ID" = FSE1."FileID"
and FSE1."FilesetID" = 578
-- join with data
left outer join "blockset" as BS1
on F1."BlocksetID" = BS1."ID"
and F1."BlocksetId" >= 0
left outer join "blocksetentry" as BSE1
on BS1."ID" = BSE1."BlocksetID"
left outer join "block" as B1
on BSE1."BlockID" = B1."ID"
-- join with metadata
inner join "metadataset" as MDS1
on F1."MetadataID" = MDS1."ID"
inner join "blockset" as BS2
on BS2."ID" = MDS1."BlocksetID"
inner join "blocksetentry" as BSE2
on BS2."ID" = BSE2."BlocksetID"
and BSE2."Index" = 0
inner join "block" as B2
on BSE2."BlockID" = B2."ID"
where
(
BSE1."Index" = 0
or BSE1."Index" is null
)
)
“File” is a view containing a string concatenation. This can be replaced with the two fields being concatenated from FileLookup to avoid the expense of the concatenation (a significant performance improvement ![]() ).
).
This brings us to:
select
count(*)
from
(
select
distinct FL1."Path", FL1.PrefixID
from "FileLookup" as FL1
inner join "filesetentry" as FSE1
on FL1."ID" = FSE1."FileID"
and FSE1."FilesetID" = 578
-- join with data
left outer join "blockset" as BS1
on FL1."BlocksetID" = BS1."ID"
and FL1."BlocksetId" >= 0
left outer join "blocksetentry" as BSE1
on BS1."ID" = BSE1."BlocksetID"
left outer join "block" as B1
on BSE1."BlockID" = B1."ID"
-- join with metadata
inner join "metadataset" as MDS1
on FL1."MetadataID" = MDS1."ID"
inner join "blockset" as BS2
on BS2."ID" = MDS1."BlocksetID"
inner join "blocksetentry" as BSE2
on BS2."ID" = BSE2."BlocksetID"
and BSE2."Index" = 0
inner join "block" as B2
on BSE2."BlockID" = B2."ID"
where
(
BSE1."Index" = 0
or BSE1."Index" is null
)
)
But for each fileset the files are unique and this query just looks at one fileset. After a littler more of a clean-up, this brings us to:
select count(*)
from FileLookup as FL1
inner join filesetentry as FSE1
on FL1.ID = FSE1.FileID
and FSE1.FilesetID = 578
-- join with data
left outer join blockset as BS1
on FL1.BlocksetID = BS1.ID
and FL1.BlocksetId >= 0
left outer join blocksetentry as BSE1
on BS1.ID = BSE1.BlocksetID
left outer join block as B1
on BSE1.BlockID = B1.ID
-- join with metadata
inner join metadataset as MDS1
on FL1.MetadataID = MDS1.ID
inner join blockset as BS2
on BS2.ID = MDS1.BlocksetID
inner join blocksetentry as BSE2
on BS2.ID = BSE2.BlocksetID
and BSE2.[Index] = 0
inner join block as B2
on BSE2.BlockID = B2.ID
where
(
BSE1.[Index] = 0
or BSE1.BlocksetID is null
)
These changes have improved query performance by 37%. Due to the significant reduction in server resourcing required for the optimised query, in real-world scenarios, for a backup with ~500 versions, this has consistently reduced total backup time from 20-22 minutes to around 6 minutes.
Further improvements can increase performance by 54% if the joins to “block” are removed. This is can be safely accomplished by adding referential integrity to the database. At the moment the query is checking data that would normally be enforced by a referential integrity constraint.
Other changes to the database will further improve integrity and performance such as the removal of the metadataset table which is redundant. The “benefit” of this table can be achieved by simply adding a code or flag to Blockset to distinguish between data and metadata.
I also suggest that the FileLookup table be normalised as at the moment file paths are duplicated in this table…. Normalising this table would further improve performance and it would also improve data integrity when combined with RI constraints.
I also see other opportunities for performance and integrity gains in the database. If people are keen I can look at making these changes.
This change will be released as a pull request shortly, when I have time ![]()