From what I understand by reading the documentation and the forum, Duplicati does not support the backup of multiple sources to the same destination.
My use case would be a bit special though, because I would need to backup several external hard drives, but they will always be done one at a time, and always made from the same computer.
So my idea would be to use the same database and destination, and from time to time change the source.
I’ve done some simple tests, and it seems to work, because as far as I can see each backup produces a .dlist file completely independent of the previous ones, so then when I need to access a backup of a specific disk, I’ll just use a specific .dlist file.
Is there something I’m missing, or something that can go wrong?
The only problem I see is that it would become unreliable and useless to automatically delete versions, so I would keep all versions.
Technically this approach should work fine. And yes, I agree you would definitely want to set unlimited retention.
I can only really think of one good reason to do it this way though: deduplication across all your external hard disks. If that isn’t one of the reasons for doing it this way, I’d probably set up separate backup jobs for each external hard drive. You can target the same general destination as long as each backup job uses a different folder in that destination.
Setting up separate jobs would let you use a retention policy again. And if the back end data got corrupted somehow, it would limit the damage to just that one backup job. It would also keep individual job databases smaller and more efficient.
Whatever you do, make sure you set a good deduplication block size. It sounds like these might be large backups (especially if you do the single job approach). 100KB is the default dedupe block size and that is too small for anything in the terabyte range. What is the total amount of data you want to protect?
Yes, this is exactly why I want to do this. I often have to move files between hard drives, so deduplication would be very convenient.
They are currently about 6 TB, which will most likely increase over time. Reading some threads here on the forum, I was thinking about 5 MB block size, and 200 MB volume size. Could this make sense?
Unless this is something like disaster recovery, people usually use version not .dlist
Either way, I guess either you keep records or maybe look for a restore tree difference.
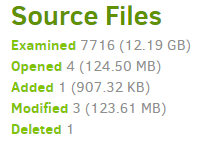
Did the log report show a lot of “Added” and “Deleted” source files on a drive switch?
Going back to an old drive will probably take some time to reconnect previous blocks.
I’m not sure it’s smart enough to recognize a new file as an old friend that’s returning.
You could look at the “Opened” report to see if it read through all of the returning files.
Aren’t versions and .dlist files basically the same concept? Anyway yes, this is like a disaster recovery plan, I don’t plan to restore the backups regularly, it’s just in case some of my hard drives fails.
Yes, the report show the number of the previous drive files as deleted, and the number of the current drive files as added. On successives switches without local file changes, nothing is uploaded to the remote, except the new .list file, so I guess it’s correctly recognizing that files are already present on the backup location.
Very much, but in terms of the user interface, it’s versions. There’s no way (I think) to ask for a .dlist.
Look at the “Opened” count. If it opened it, it didn’t recognize it as the same file, it just read it all through.
Block-level deduplication did the rest. If it didn’t actually open any files, then it’s smarter than I guessed.
The possible slowdowns I mentioned may or may not matter to you, but you asked what can go wrong.
Where I can see the “opened” count? I’m using duplicati-cli, I only see files added, files deleted and file changed.
Yes sorry, I had to be more precise, I mostly meant what can go catastrophically wrong. Slowdowns are not a big deal, my priority is avoid data loss and backup corruptions.
That makes it more cumbersome, and I’m not sure why, except maybe the server coming later added it:
If you know where your database is, you can just point a throw-away (don’t run it) GUI job Database there.
If you send yourself results email even on a success, you can get it that way. Below is an example of that:
Okay I found it, OpenedFiles is equal to AddedFiles, so it seems it doesn’t recognize it as the same file. Just out of curiosity, if it instead recognized that the file is the same, it would only check the last modification date, and would not recalculate the hash of the file chunks if it has not been modified, is that correct?