--keep-time, --keep-versions and --retention-policy are part of the backup job configuration.
They are defined in step 5 of the Add/Edit Backup wizard.
--keep-time and --keep-versions can be supplied under “General Options”:
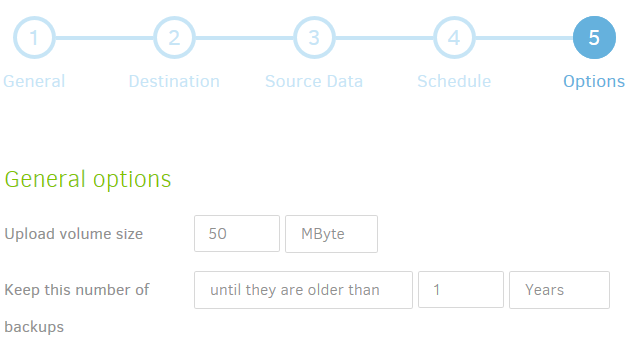
--retention-policy is an advanced option.
The --keep-time, --keep-versions and --retention-policy options are applied after completion of each backup job. Compacting is started automatically when needed. You can set thresholds for compacting the advanced options --small-file-max-count and --small-file-size.