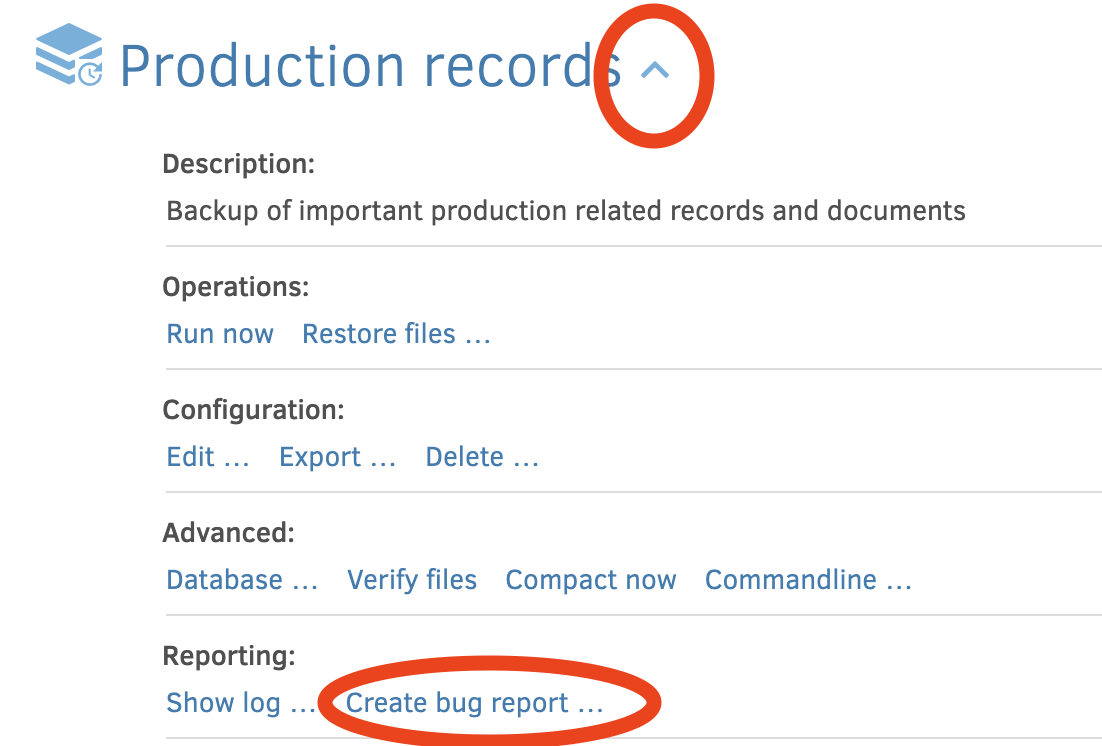
Thanks for the bug report. What sort of destination is this? It seems to sometimes give trouble.
@ts678 the destination is set to my Dropbox account. Let me know if that answers or not ![]()
Thanks! That makes it a lot easier to track down.
My pleasure! Love seeing active response, it’s refreshing vs. many other projects
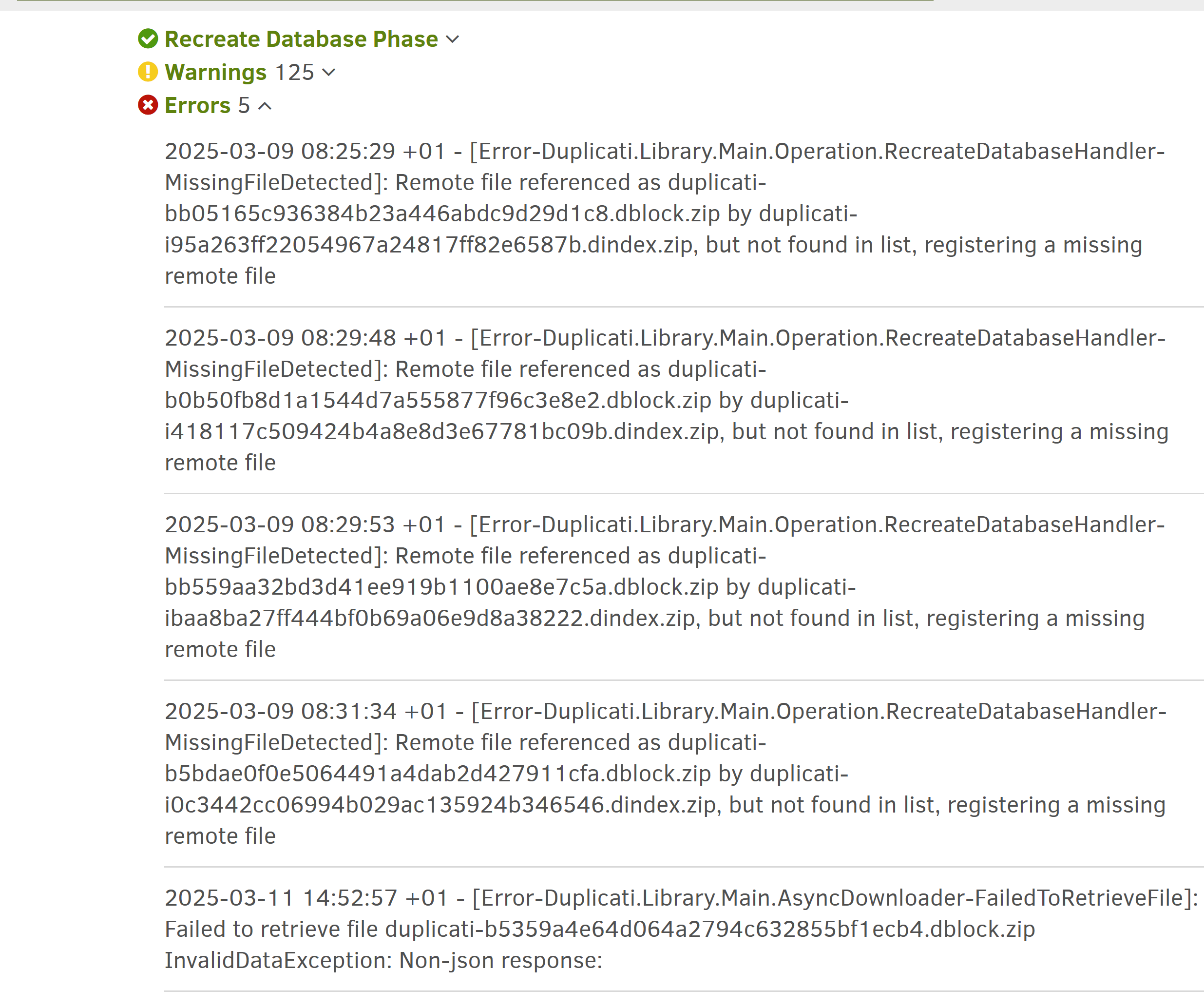
@ mathdu In the UI, do you see any errors for the backup that was running on 2025-02-02T13:12:00.9864685Z (UTC)? > I am suspecting that something in the shutdown logic is perhaps causing errors that are not logged.
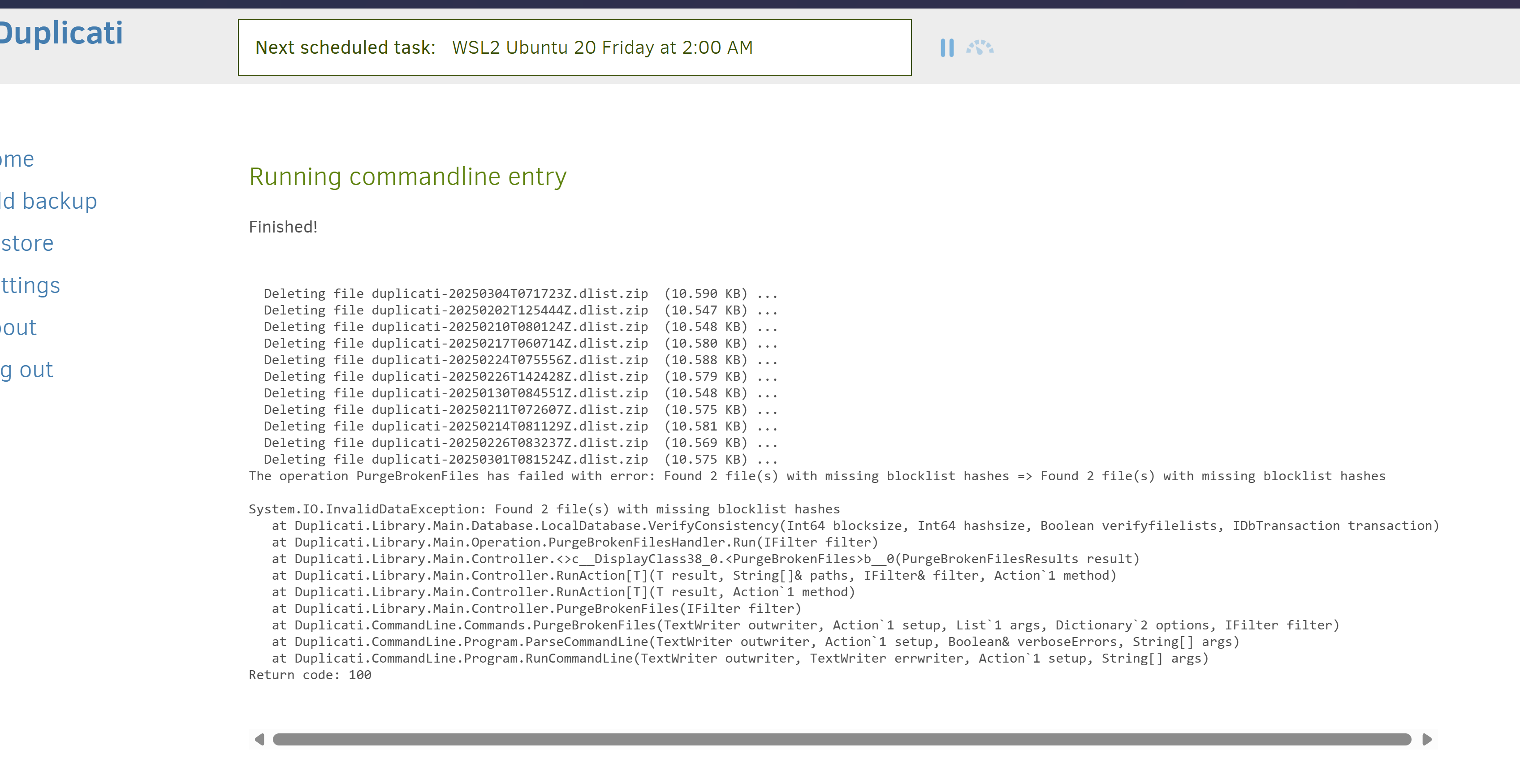
Fortunately, I have removed all the code in question here for 2.1.0.108, but it does not fix the setup.
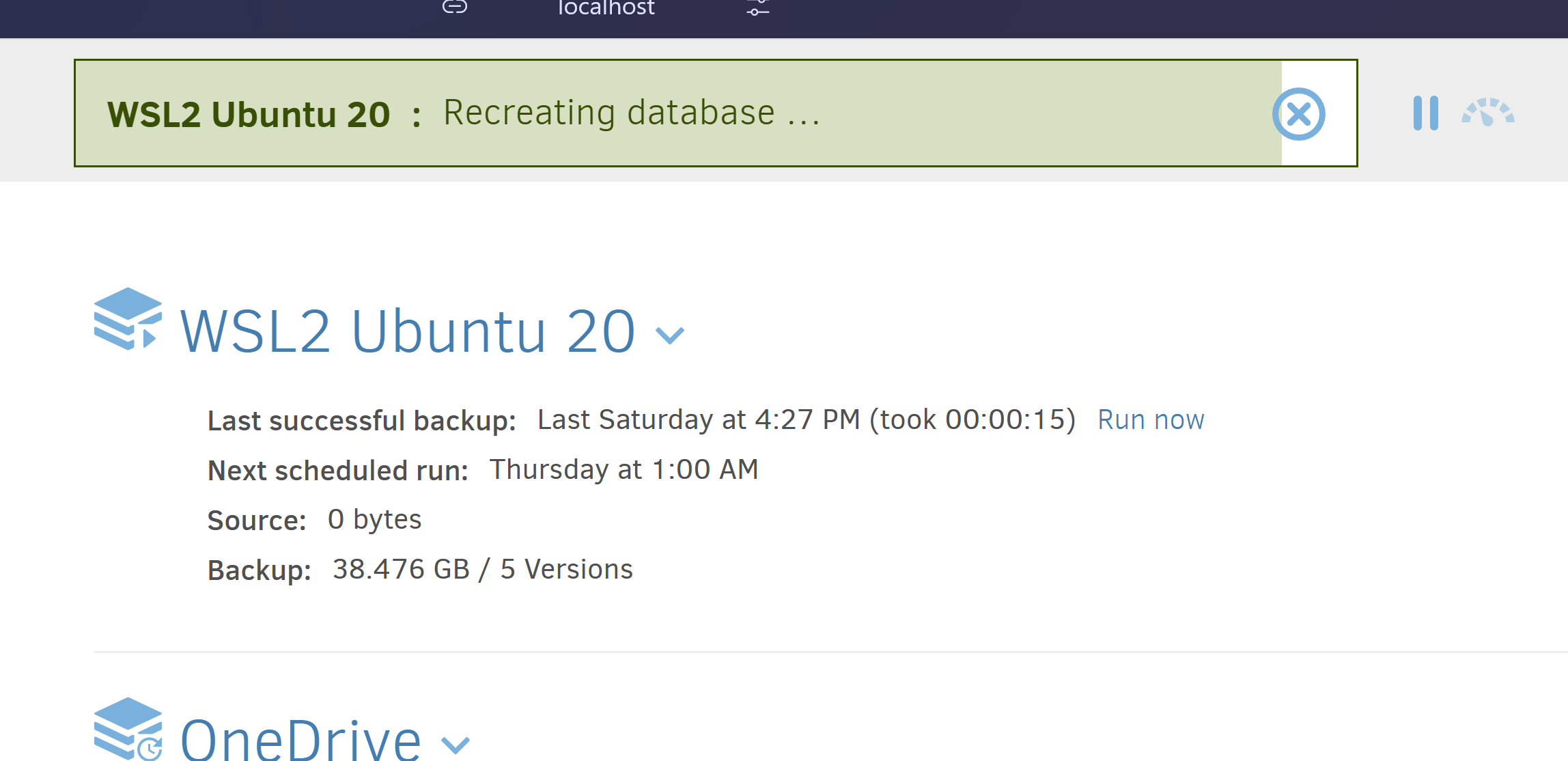
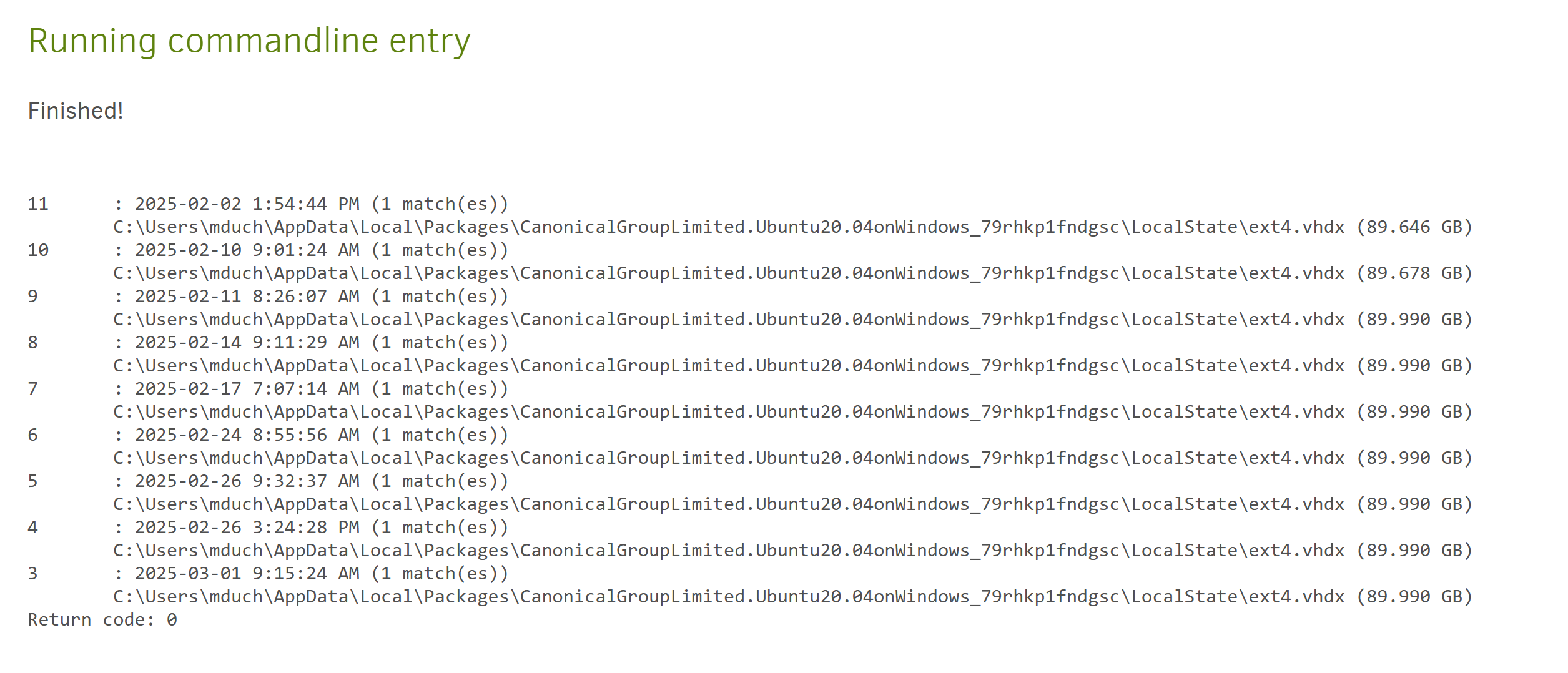
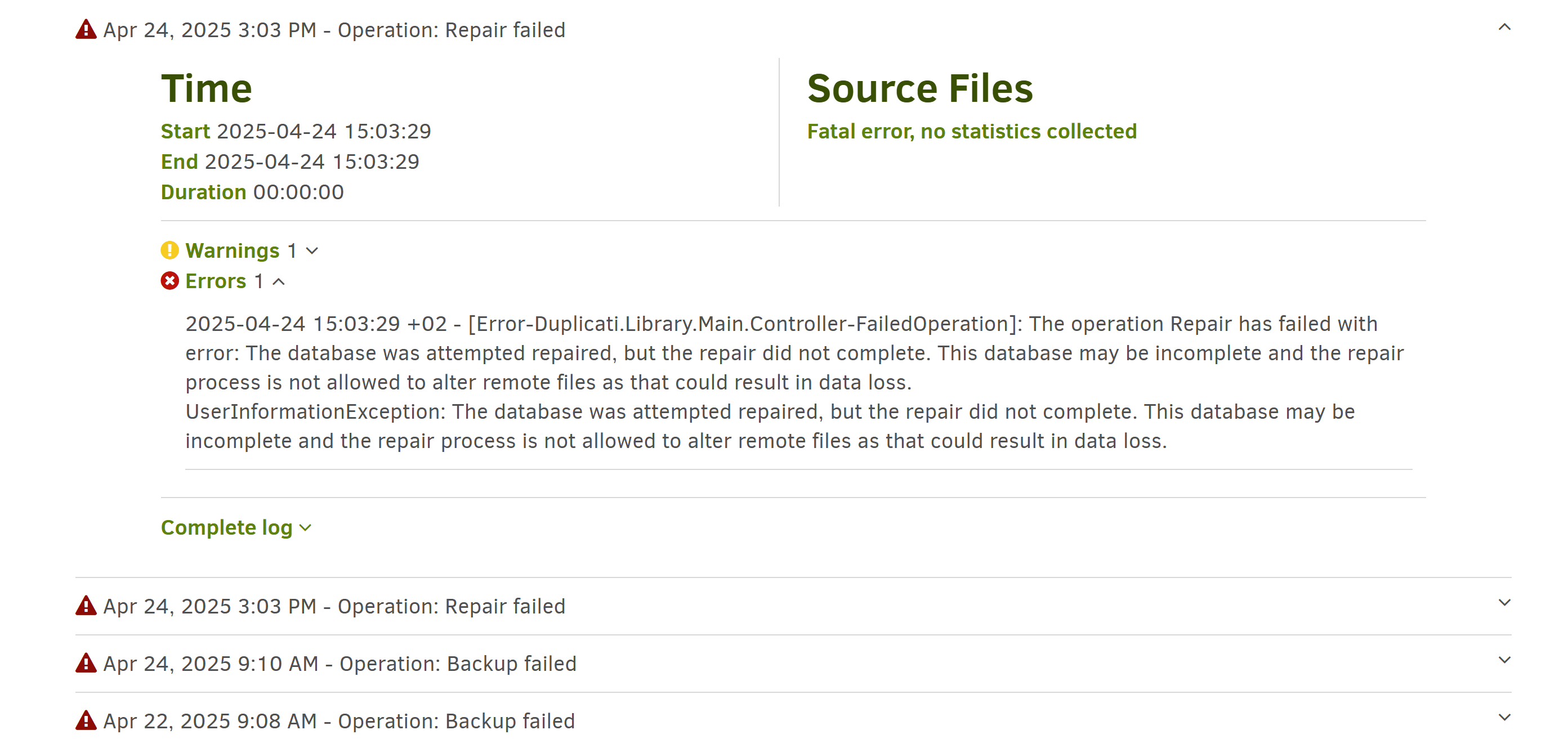
@kenkendk You’re meaning this one, correct? I don’t see any errors (it’s actually the last one showing success), but let me know if you need more than this:
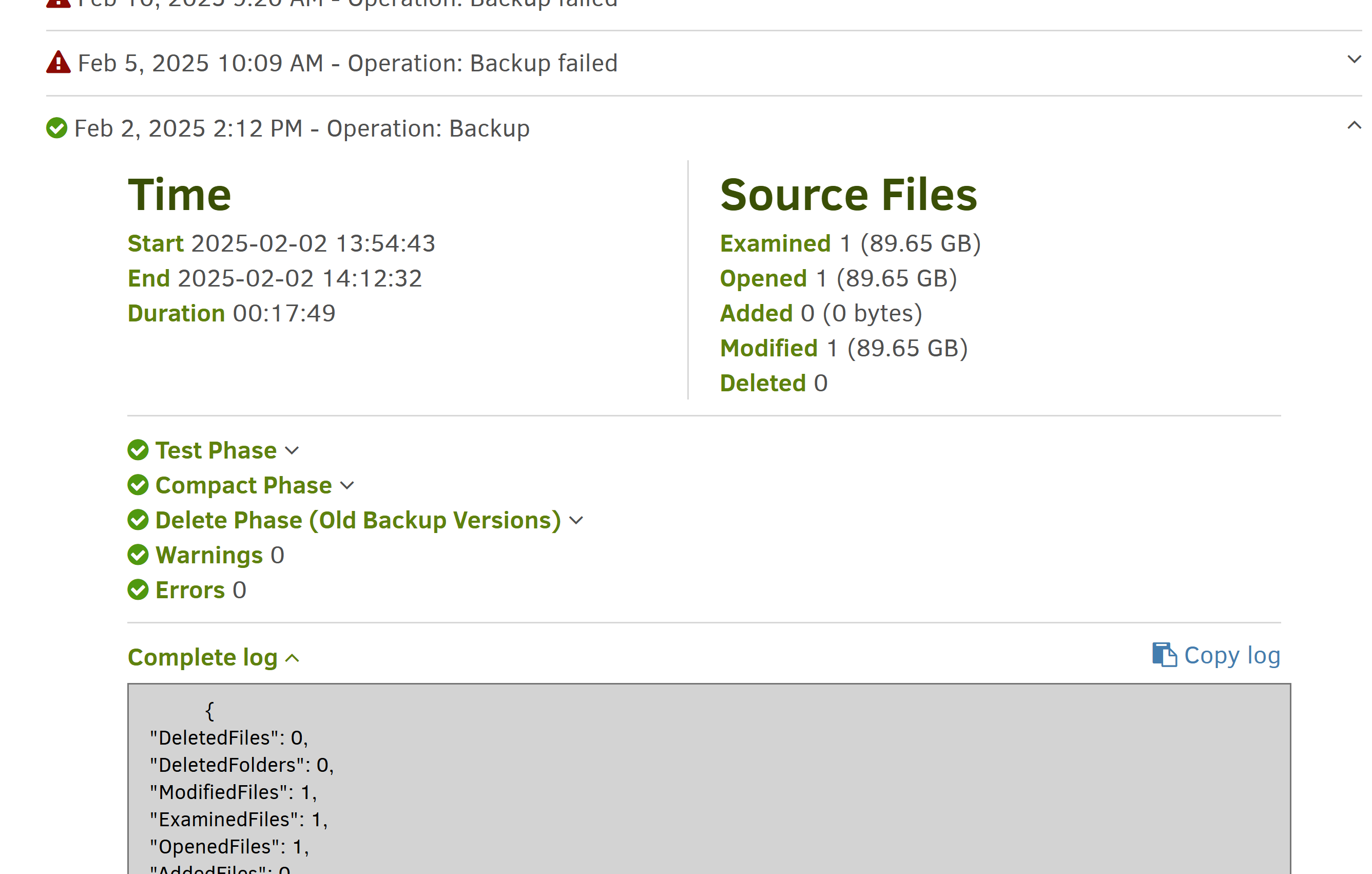
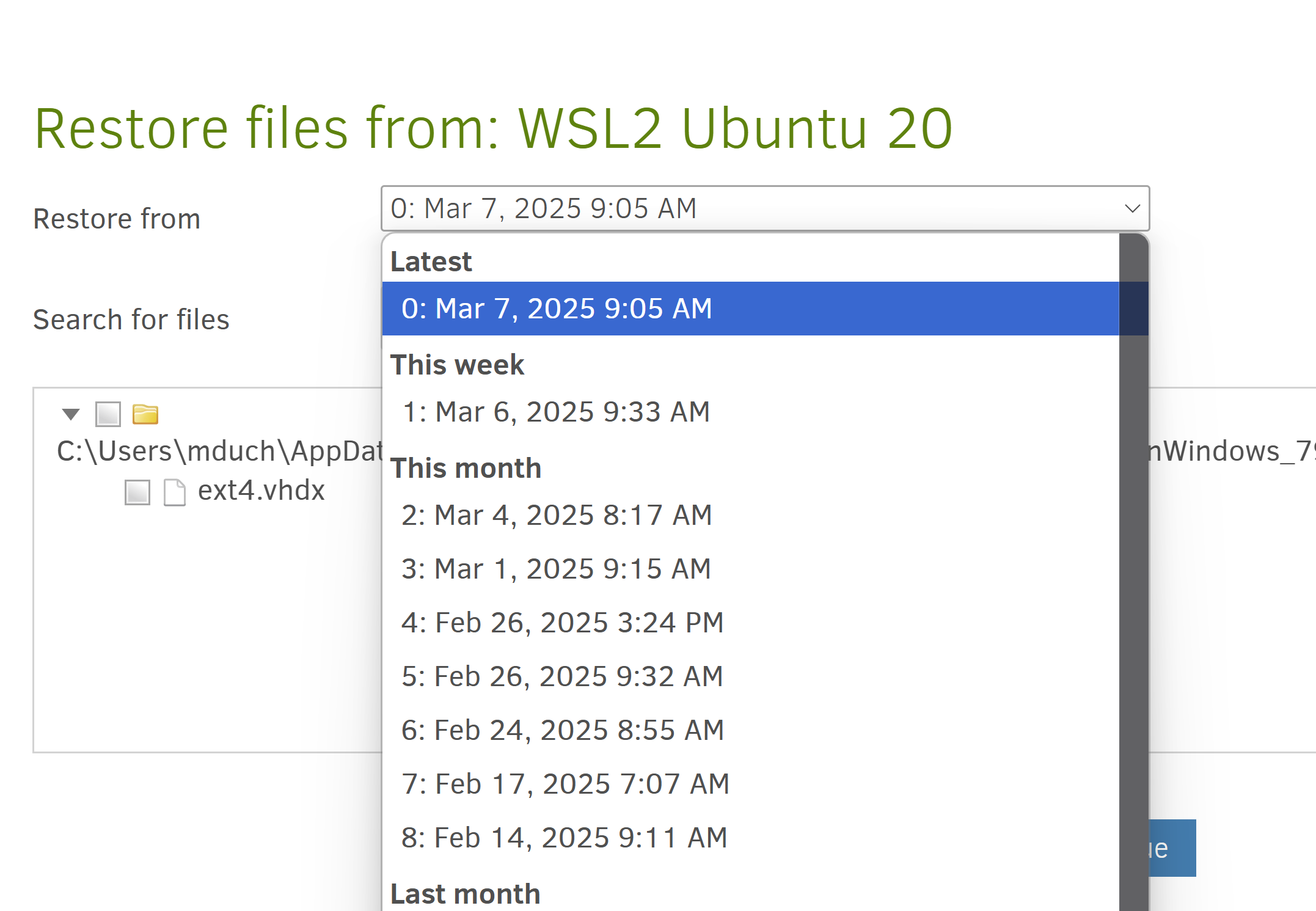
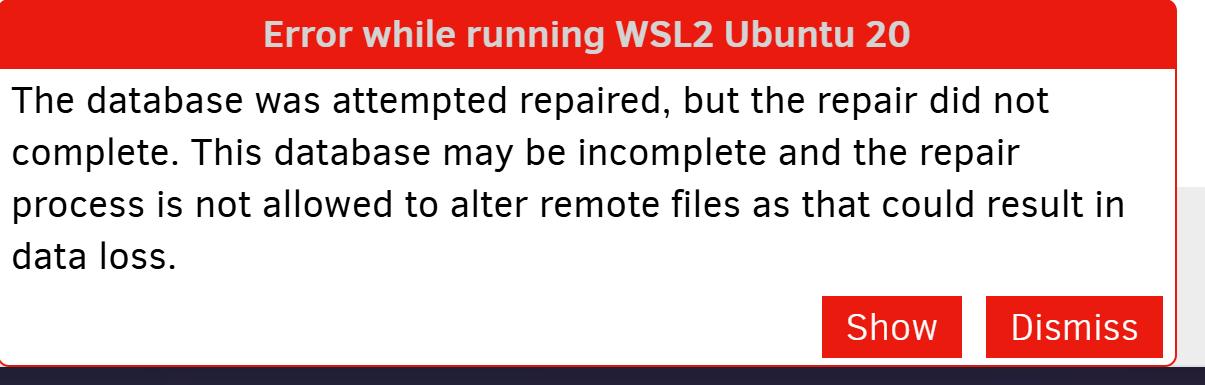
Also, @ mathdu do you want to try to recover the backup to the state before 2025-02-02 ?
That would overwrite my current state, correct? I’m hesitant but i’ll consider it (wouldn’t be dramatic, all the changes are in git repos).
From looking at this, that would mean selecting Jan 30th? Interestingly, it’s not showing Feb 2nd (despite it showing successful)
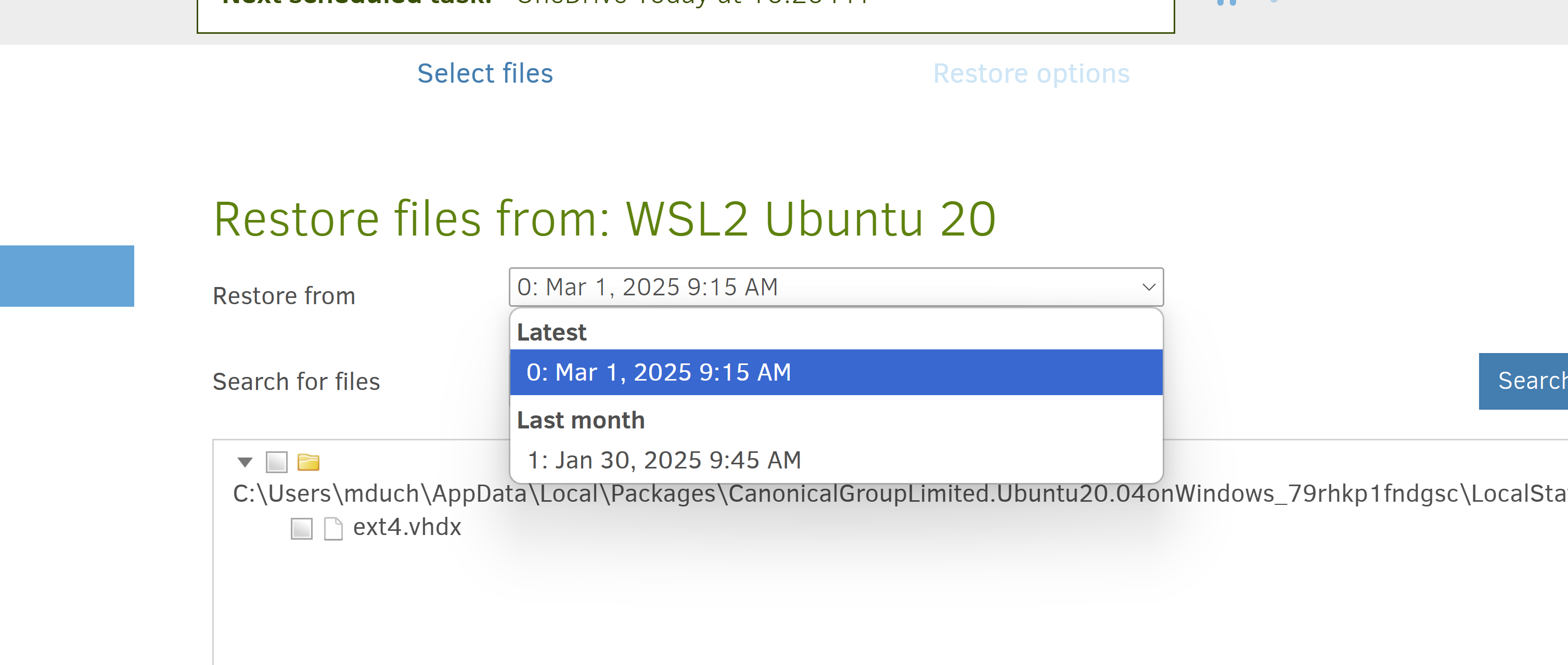
Question: I’m excited to install the new stable version you posted in another thread, but for the purposes of this topic i won’t touch anything until you tell me to ![]()
![]()
Thanks a bunch to you both!