Duplicati backup works well.
I use two parallel backup: So I backup my data to two location. Googledrive and local.
Local backup is 4T very fast SATA. Physically it is connected to internal SATA connector. So, I does not use USB etc. Between three month I change it disk- I use two disk. One connected and one in Safe.
Data quantity is about 1,5 T.
Okay, but this was not question. It was Prologi.
Now I test restore data. Not emergency, test. I connect this backup disk to one linux-computer and start restore. It is fast restore reason restore is “from internal disk to other internal disk”.
But- restore is very slow. Now, after 20 hour, “Downloading file… checking remote backup… 1530286 files restored (1,47 T)… checking existing target files… Scanning local files for needed data”.
Now, after 20 hour, folders are restored. So in my opinion, looks all folders are created. Still empty.
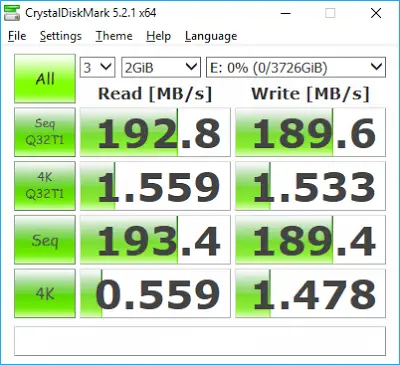
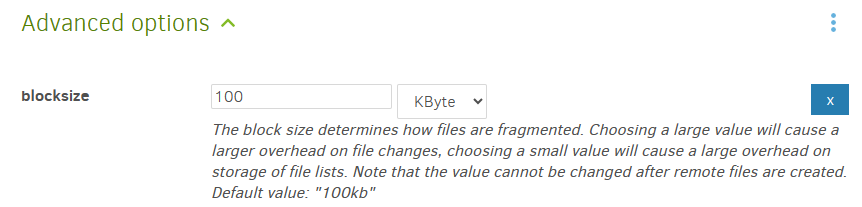
Okay, I understand restore from google drive will be very slow. It is understable. But this is pure, real local disk. Remove volume size is 50 MB.
Backup is scheduled and speed of it is not interesting. But restore speed is. So, is it any way how to grow-up speed of the backup restore? If I create new backup, what I can do? Remote volume size 500 MB? Or Remote volume size 1 kt? Or any other jinx? Just now I restore data. 20 hour. And when ready- many, many days. So, question is: “What is good way make local backup- remember parallel backup to googledrive- what I can do? How I can make it quite fast restore?”
Edit… “scanning local files for needed data”, now time spent about 27 hour. Tomorrow I will check again status. This is very interesting I make restore from internal SATA disk to other internal SATA disk. For me this is ok, but I imagine case “I must restore 15 T”- if 1,5 T take 72 hour, 15 T take 720 hour. Quite slow this Duplicati… ![]()