There are some updates to the spreadsheet I’ve shared.
@jl_678 sent me the results of testing and I included them on new tab “ARM board”
After some more reading, I realized that my TI restore testing was not correct:
when restoring to different destination and if original files are still on the file system, then files will be patched from local blocks instead of being downloaded
TI will also run local files verification test at the end of the restore and CY does not have this step
To equalize both applications, I added two parameters to TI restore command I use:
Disabling usage of local blocks slows down to a point that TI is no longer faster that CY in any test.
Disabling post-restore verification put both applications on the same level.
And one more - download speeds vary a bit and there is no way to watch it easily, so timing depends on download times a lot. Would be really nice if TI can log min/max/avg download/upload for each operation.
And one other observation, about which I am scratching my head now - before disabling local blocks usage, TI reported that it still need to download 50% of all dblock files even that all original source files existed in original location. Not sure what the criteria TI is using for initial scan, but it does skip some local files and require chunk downloads.
After disabling local blocks, TI downloaded all dblock files as expected.
While reading this post, something else occurred to me. When I ran a backup using the CI cli, at the end there was a comparison scan of some sort. I do not think that Cy does this and makes me wonder if it unfairly penalizes ci. Your restore post got me thinking about this because it looks a similar scan is performed there.
This seems to be a bug - it did actually restore all the files. It also pauses for a bit after "Verifying restored files …"
Compare with the output when verification was enabled:
Yes, support for SFTP is built-in for destinations. But, not as a source. DC allows SFTP servers as a source besides local storage. Very useful when backing up multiple websites (over SSH) and multiple (macOS/linux/cygwin) computers.
Would you consider splitting up
‘Supports SFTP servers as source’ and
‘Supports SFTP servers as destination’?
If you’re asking for a Duplicati feature allowing for SFTP as a SOURCE, that sounds like a good point to start a new Topic (I can split these posts off for you if that’s what you’re asking).
My GUESS is that the initial answer will likely be that on Linux (and Mac?) one can use Fuse to mount the SFTP source so it just appears to be any other “local” folder and that on Windows it’s not an option. Hopefully that answer would be enough to get must current users wanting such a feature to where they need to be while time could potentially be found by developers to implement non-local SOURCE support.
If it’s a feature you’d REALLY like to see you could also consider heading over to Github and either putting a bounty on the feature (if you have the money) or try implementing it yourself (if you have time skill / time).
Indeed, that is what I’m referring to. I’ve changed the wiki page, please check and change if that is not to your liking. I was looking for a central backup solution (something to run/orchestrate from 1 server), hence the desired feature.
I - unfortonately - do not have the coding skills to develop that myself. But the bounty idea is one to go with. I’ll put a small/symbolic amount on it as I believe that it will be of great use for many other users, especially those who do not want to pay a fee for every system they need to backup, and who want central administration out of the box.
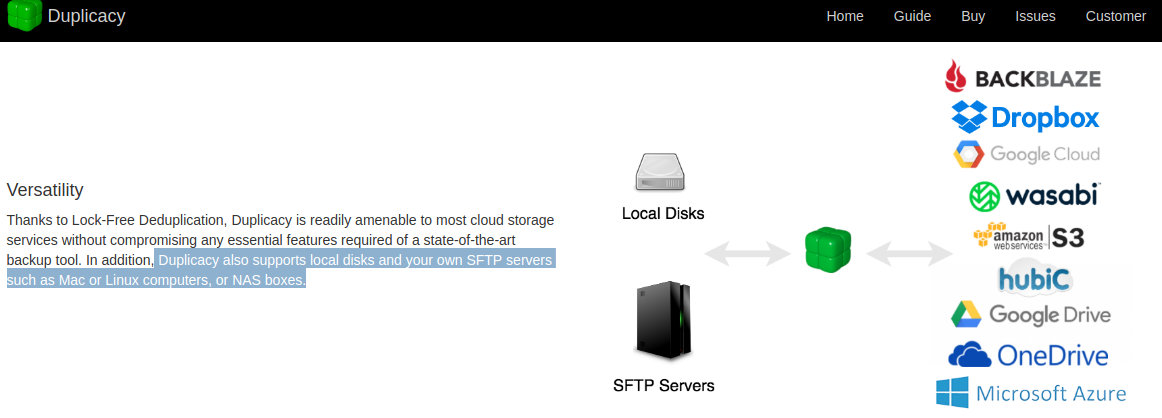
@fred - No, duplicacy does not support SFTP as a source, the image on its home page is misleading - it actually depicts source in the center and all destinations around it.
I would actually go further and state that source support in duplucacy is not good.
@dgcom you are right. Duplcacy does not support SFTP as a source (contrary to what I understood from reading their website), I’ve just checked with the Linux CLI and windows gui clients. Why do you think making source and destination interchangeable is not a good idea?
I’m open to better idea’s. I’m assuming I’m missing something here. How can one:
set up 1 single system (e.g. NAS, home/SMB server) to store backups from locations that only allow SSH/SFTP (e.g. shared webhosting, friends, multiple computers))
backup collected data securely to remote (cloud) locations
It is not a bad idea to be able to switch source and destination, but that is usually design for sync tools (ex. rclone).
Backup usually designed to archive local data somewhere else. And NAS is one exception, but it usually exposes itself as shared drive, hence local source works. But from performance and open files reasons, I’d run backup command locally on NAS itself.
Indeed one way to do backups is to archive data from local to remote. Yet, that would require backup software such as duplicati to run from all devices, or use a different backup system to pull the data out of the devices first. Whereas if remote to local backups are also supported, that would:
Allow backups to be made from locations that do not allow interactive shell.
Allow backups from low resource devices that do offer SFTP but not much else.
Relieve the need for installing and maintaining software on all devices.
PS We are talking about backup, not synchronization indeed.
Most backup software (and I am talking about traditional ones - Veritas/Symantec, Bacula, etc.) use local agents and central server design for a reason - it is possible to control endpoint state, preventing machine from sleep, verify file hash, copy open files…
Without local agent you loose this flexibility. You can’t (in most cases) copy open files, machine can sleep, and to check hash to verify if file have changed, you’ll need to send entire file over the wire.
Those are the reasons why you do not see this architecture often.
If you are talking Unix/Linux - you can always mount remote SSH as a folder (SSHFS) and use any backup tool as it it is local (all issues still apply). If your remote is Windows - just install SSH server - there are couple of free ones.
And keep in mind - SFTP performance is not up to SMB or even HTTP. in many cases.
That sounds like with DT you can’t have two computers backing up to the same account at the same storage provider. Is that correct? Or does it just mean that DT can’t have concurrent backups to the same folder in that account?
From reading the source code for Duplicacy, it appears that they actually build a table of all known blocks and keeps this in memory. We had that option some time ago, but it was a real memory hog, so I removed it.
I have just tested with a small backup (~2000 blocks), and a block lookup cache had a tiny positive effect on the backup speed. But it is possible that this speedup is much more pronounced with larger backups, so I made a canary build with the option --use-block-cache. If it turns out that it really does improve performance without ridiculous memory overhead, I will convert it to a --disable-block-cache option.
If @dgcom and @jl_678 have a test setup, I would like to know the performance difference from the --use-block-cache option. I am aware of another performance issue related to how a file’s previous metadata (size, timestamp, attributes) is fetched, so it is possible that this is what really makes the difference, but maybe the --use-block-cache can help shed light on that.
If that is how it works, it would require that the destination supports some kind of “If-Modified-Since” approach.
Without actually running Duplicacy, it does appear that it lists all remote blocks first, and keeps them in memory:
I think it works by having a copy (maybe without contents) of the remote store, in the local filesystem:
Some of the complexity in Duplicati is there to handle big backups. If you have a file of 1TB, you need 300mb of raw hash data (with 100kb blocks). To avoid a blowup in memory and large file-lists, Duplicati keeps it in database and uses “blocks og blocks”.
But if you have a smaller backup, this should not perform worse.
I will test this new build and provide the results. I’ll use SMB share for the destination - that should remove extra variables from testing.
Interesting. I’d like to test this, but how often you’ll have to backup 1Tb file? Would this difference be really noticeable on a bunch of, let’s say, 4Gb files?
I tested Duplicati 2.0.2.6 Canary and added test results to the spreadsheet.
This time I used locally attached USB 2.0 drive and used single up/down thread for CY compare.
And CY still noticeably faster, even with single thread.
I do not see much of a change between --use-block-cache="true" and not setting this option.
On backup, time is actually spent reading source files and there is no CPU bottleneck.
I’ll see if I can dig more into why TI is much slower in comparable configuration.
EDIT
Some more testing did not reveal any real help from --use-block-cache="true"
The only way I was able to speed up backup was to enable --synchronous-upload="true"
Restore with --no-local-db="true" is a bit faster compared to two separate operations.
I ditched VSS since it may take variable time and also measured compression and encryption impact on the backup.
Here are some of the results:
Backup
00:08:49.995 --synchronous-upload="true" --no-backend-verification="true" - COMMON for below
00:08:42.335 --use-block-cache="true"
00:07:23.040 --no-encryption="true" --use-block-cache="true"
00:06:08.722 --zip-compression-level=1 --use-block-cache="true"
00:05:04.746 --zip-compression-level=1 --no-encryption="true" --use-block-cache="true"
Restore
00:01:52.741 --no-local-db="true" --no-local-blocks="true --skip-restore-verification="true" - COMMON for below
00:01:45.409 --use-block-cache="true"
00:00:18.345 DB repair
00:01:32.149 --dbpath=<repaireddb> --use-block-cache="true" --no-local-blocks="true --skip-restore-verification="true"
These results are still noticeably worse than CY
As suggested before, I’ll try backup of very large files instead of many small ones.
Thanks @dgcom for trying that out, much appreciated.
I am a bit surprised that TI is that much slower, and I guessed at maybe the in-memory lookup table was reason, but it should not matter a lot, since most lookups will fail (the block is new), and the database is using a log(n) lookup time anyway. Your results show that the database is indeed fast enough (at least on an SSD).
Compared to CY there are not many differences, so I think TI should be able to reach similar speeds.
CY stores all blocks “as-is” on the remote store (in some cases using folders to reduce the number of files in a single folder).
TI stores files inside archives to reduce the number of remote files and requests.
CY keeps a cache of the remote data locally on-disk.
TI keeps a cache/lookup of the remote data in a database.
CY uses a flexible block width (content defined chunking), TI uses a fixed block width and a block-of-blocks.
They both use SHA256 as the hashing algorithm.
I see a big jump when you lower the compression level, so maybe the bottleneck is really the zip compression.
The speedup from --synchronous-upload is a bit strange, as it just “pauses” the backup while there is an upload happening.