I have 5TB of data in Azure blob at 5GB block sizes. The sole purpose of this is for DR, hence the large blocks.
Something happened with my server where this backup is going to save me (I hope!)
The issue is I see it download some 5GB chunks every so often, which I’m fine with, but I’m wondering if it’s only doing this to rebuild the database or will it also use these files to restore the actual data.
Jun 27, 2019 8:44 AM: Backend event: Get - Completed: duplicati-b052c766aa4054cbd9adddf074a3c3b83.dblock.zip.aes (5.00 GB)
So basically, once it’s down rebuilding the database, is it going to download these again?
I’m not sure, but it’s possible that it will. Ordinarily, database shouldn’t need dblocks at all, but 2.0.4.5 sometimes downloads ALL dblocks by mistake during the DB rebuild, looking for an empty file that it’s never going to find. This phase starts at 70% on the progress bar, which then moves very slowly. For backups as large as yours, you might consider (IF you see this symptom) installing canary which is in (probably) a lead-in to next beta, otherwise I would consider canary something a bit dangerous to run, except for test situations. Or you could use canary for restore, then start a fresh backup using 2.0.4.5 which won’t be able to deal with the newer database. Or if you’re willing to stay with canary awhile and contribute your experience (hope it’s good), then you could jump back into beta when next one arrives.
Aside from the bug that you may or may not be seeing, the reason for later dblock downloads would be actually restoring the files. This is always required, but dblock downloads for DB recreate might not be.
If you think canary will might do a better job for the restore, I’ll definitely do that. I’m afraid that i’m Going to hit some quotas in Azure if if had to redownload the dblocks multiple times…
Make sure your case fits the symptoms I described, otherwise I can’t say whether canary will do better. There also might be legitimate reasons why it’s in the block-fetching phase, but I suspect false-alarm is widespread. What are the chances that you DON’T have an empty source file somewhere that was backed up previously?
If you can acquire a bunch of extra disk, it’s possible to ensure single downloads (and maybe process faster) by doing your own download using some fast downloader (Duplicati is single-threaded), then working off that.
This is my first time having to do a non-test restore with duplicati. I have enough storage space available where I could download everything from azure onto a share. If I do that, there shouldn’t be any issues pointing the direct restore to that local share I assume?
Duplicati backups are the same regardless of storage, so just download and direct restore from whatever, however “share” makes me slightly nervous. You’d treat it like a local file, but I’m not sure how fast it runs. Integrity glitches (if they happen, but frequently shares are just fine) should be spotted. Hopefully it’s all OK.
Thanks, I generically mean share. It’d be moving it to an unraid server where the duplicati docker will see it as a share basically, but it’s private and local
Release: 2.0.4.21 (experimental) 2019-06-28 was just announced, so canary now has some ability to diverge as experimental turns into beta sometime soon (we hope). If you stay on canary too long, you might pick up a newly added bug, or a DB format update that impedes return to beta (which you may or may not intend to do).
Plus, as much as canary testers are needed, testers for experimental are the last line of testing before beta…
Regardless, I hope your restore and continued backups go well.
Is your test specifically the false-alarm from an empty dblock, or might there be a genuinely missing one, which would legitimately keep on looking, until such time as there’s some option or question to limit that?
I was testing it on one of my production backups - I’m not intentionally testing for the false alarm. How can I tell if there’s a missing file that would require dblock(s) to be downloaded? Would it be a missing dindex, dlist, or…? Also the backups normally work fine - Doesn’t Duplicati normally warn when there are any missing files?
If you have a suitable debugger (and preferably a debug-friendly build), maybe you can look at lst below:
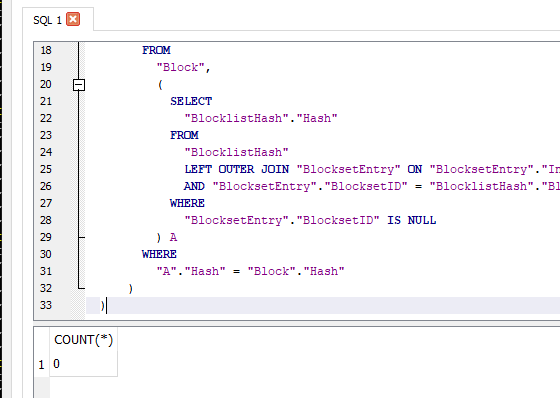
Or you might run the same SQL yourself if you can manage to safely copy the database during Recreate, or if the Recreate is just a test, and you kept the old DB, then maybe run query on that. Query is as below:
and to avoid me having to expand it again (though it does get easier with practice…), I’ll point to the issue Empty source file can make Recreate download all dblock files fruitlessly with huge delay #3747 where original post has a pretty-printed query without the fix. It’s left as an exercise to edit in the fix, and to try to trace things around better than just getting a count. Sometimes it’s an exercise in cutting things down, e.g. which chunk of SQL in the UNION was the one that found something to cause countMissingInformation to stay non-zero, and continue downloading dblocks? From my test notes on tracking the bug down, it ends:
missingBlockInfo is
SELECT "VolumeID" FROM "Block" WHERE "VolumeID" < 0;
and in my test it returns -1 for the Hash=47DEQpj8HBSa+/TImW+5JCeuQeRkm5NMpJWZG3hSuFU= Size=0 ID=2 Block row for C:\backup source\length0.txt
but assuming the empty file fix is working, your missing information may be from missingBlocklistVolumes.
Ok thank you for the info - I will try to mess around with it today to see what I can find.
I remember the issue posted about empty source files, but I thought that fix was included in 2.0.4.21. That’s the main reason I was testing this - I wanted to see if recreation is a lot better now.
I tested recreation on a different system with a much smaller backup. It downloaded all dlists and then all dindexes (not surprising) and then it did download a handful of dblocks before completing the rebuild. The newly recreated database is about 50% the size of original, which is a bit puzzling. (The original database had been vacuumed so that’s not it…)
I’m wondering if the recreate also fixed the cause of why dblocks had to be downloaded, or if that problem still exists. If it still exists is there any way to fix the main issue so that I can do a recreation without downloading any dblocks?
Maybe normal? Or at least it doesn’t hurt a lot. Per earlier cited source there are 3 passes of dblock gets, and the last pass (from 90% to 100%) is the long-running last-ditch retrieve that happened for empty files.
If the old one was 2.0.4.5 beta, the DB format changed to a more compact path representation in January.
If it is then I’ll not worry about it!
I was under the impression from my previous reading (which admittedly wasn’t that in depth) that a db recreate should only need dindex and dlist files. If dblocks are needed, something was wrong.
“Maybe normal?” was not said with any certainty – I’m not an expert in what the first two passes do, although anyone who wants to practice their SQL (and Duplicati) skills further is welcome to have a try.
I did just confirm what I thought was true, which is that rather than have to fetch blocklists from dblocks, dindex files have the actual binary blocklist (8 byte SHA-256 hash per block) directly in their list folder.
–index-file-policy reads like it would influence how much of this redundant “helper” data gets in a dindex.
This is not the empty volume problem. When you see this message, Duplicati knows it is missing some information, and also knows where to find it. It will then download the files and extract the required information.
After this has completed, if there is still data missing from the database, Duplicati goes into a “lets download everything until we get whats needed” phase. This used to happen with the empty-file problem that @ts678 refers to.
You can see the messages for each of the phases here:
The intention is that the dindex files should contain everything needed to recreate the database. The download of dblock files is skipped completely if all data is found after downloading the dindex files.
I am not sure what causes the dindex files to miss some of the required data though. It does not happen in my tests or in my personal backups.
I don’t know. It does not seem to happen in any of the simple tests, so I suspect it happens during compacting, where it “forgets” to add some of the index-block copies to the newly generated dlist files.