As explained, it’s not a large download and store, but it’s a download (time and maybe money).
There are some relatively tiny downloads that would give some info. I’m tempted to study dlists.
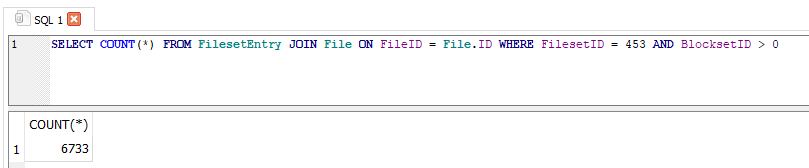
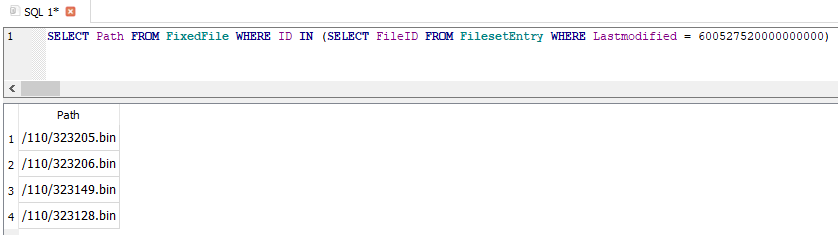
These are what should match the fileset, and one theory is the filesets got fewer files somehow.
The dlists for you are about 25 to 30 MB each, so should be very fast and easy to get manually.
The idea is to compare the file list from the dlist with the file list from the fileset in the database.
A rough compare is pretty easy, using a spreadsheet and counting lines. A good one could use
a Python script that I have that normally looks at dlist and dindex files. It’d change to look in DB
instead of dindex to see what blocks are there. If needed blocks are missing, it will reveal them.
A good starting point may be one of the middle ones on the list, as I think the end ones are OK.
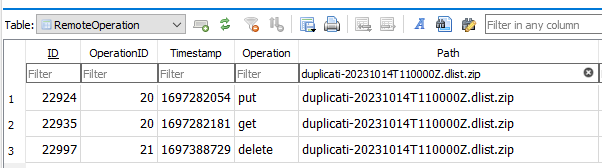
Fileset 5 is duplicati-20230929T110000Z.dlist.zip, and we have looked at it some. Maybe that?
Incremental backups
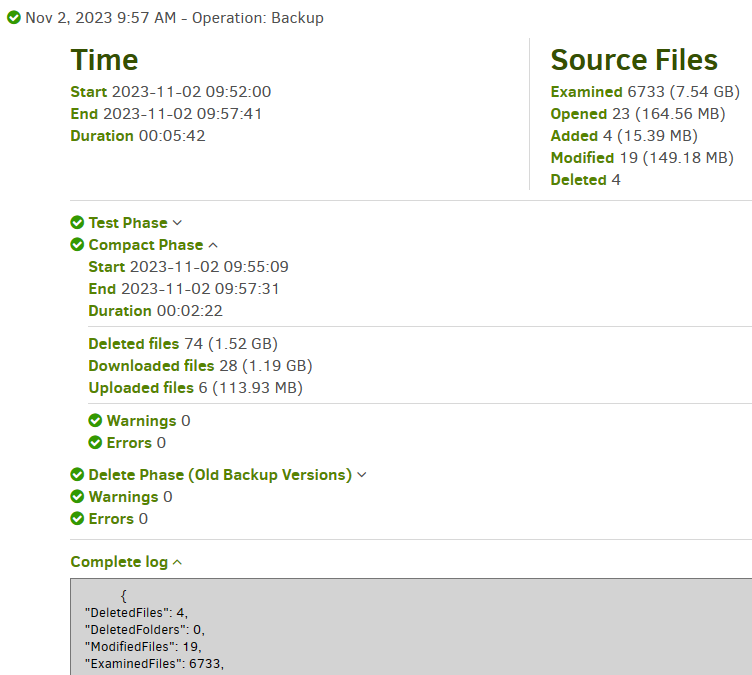
Duplicati performs a full backup initially. Afterwards, Duplicati updates the initial backup by adding the changed data only. That means, if only tiny parts of a huge file have changed, only those tiny parts are added to the backup. This saves time and space and the backup size usually grows slowly.
New backups build on prior ones. If old ones get discarded, new ones have more changes to grab.
As mentioned, we could try hand-cleaning DB using SQL, but the destination might be still be bad.
You would then think you have a backup, perhaps have a disaster, and find your backup is broken.
There are several commands that do what you ask, but they’re for known damages, not unknown.
Did list-broken-files have anything to say? If so, there are follow-on commands for cleanups.
At the moment, you might have a couple of intact backups – the first and last, so that’s protection.