This is nice. The bug report privacy protection removes paths, which might be relevant to this issue.
Logs can get removed too (maybe based on having paths in them), so I might need some help later.
The info so far will take a little time to look at, but on the surface you have the same fewer-files-than-expected that was seen before. Cause never got fully tracked down, but more data will possibly help.
We have some history with these too, but again no full understanding of how they come about. Sorry.
IIRC it says something Duplicati decided to change had already been changed. Database confusion should become more visible when we can see the database bug report and get some context for this.
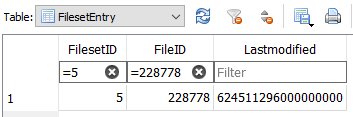
Here is the result. I hope I did it correctly. I assumed that “Unexpected difference in fileset version 8: 29.09.2023 13:00:00 (database id: 5)” meant that I should put 5 as fileidnumber.
Translation from french : Execution without error. Result : 0 records bring back in 14529s at line 1
L’exécution s’est terminée sans erreur.
Résultat : 0 enregistrements ramenés en 14529ms
À la ligne 1 :
SELECT DISTINCT PATH, FilesetID, FileID, Typ FROM
(
SELECT
A.Path AS Path, D.FilesetID, D.FileID, “regfile” as Typ
FROM
File A
LEFT JOIN Blockset B
ON A.BlocksetID = B.ID
LEFT JOIN Metadataset C
ON A.MetadataID = C.ID
LEFT JOIN FilesetEntry D
ON A.ID = D.FileID
LEFT JOIN Blockset E
ON E.ID = C.BlocksetID
LEFT JOIN BlocksetEntry G
ON B.ID = G.BlocksetID
LEFT JOIN BlocksetEntry I
ON E.ID = I.BlocksetID
WHERE
A.BlocksetId >= 0 AND
D.FilesetID = (5) AND
(I.“Index” = 0 OR I.“Index” IS NULL) AND
(G.“Index” = 0 OR G.“Index” IS NULL)
UNION
SELECT
B.Path, A.FilesetID, A.FileID, “dirlink” as Typ
FROM
FilesetEntry A,
File B,
Metadataset C,
Blockset D,
BlocksetEntry E,
Block F
WHERE
A.FileID = B.ID
AND B.MetadataID = C.ID
AND C.BlocksetID = D.ID
AND E.BlocksetID = C.BlocksetID
AND E.BlockID = F.ID
AND E.“Index” = 0
AND (B.BlocksetID = -100 OR B.BlocksetID = -200)
AND A.FilesetID = (5)
) R
WHERE NOT EXISTS
Duh, you did but my query was not powerful enough to catch this problem.
Here is one better I think (beware that this time you have to put 5 in 3 locations - there is no need to put () around the number, by the way)
SELECT file.path, filesetid, fileid
FROM FilesetEntry
JOIN file ON (file.id = FilesetEntry.fileid)
WHERE
Filesetentry.FilesetID=(fileidnumber) AND
FilesetEntry.FileID = File.ID AND
NOT EXISTS
(
SELECT DISTINCT PATH FROM
(
SELECT
A.Path
FROM
File A
LEFT JOIN Blockset B
ON A.BlocksetID = B.ID
LEFT JOIN Metadataset C
ON A.MetadataID = C.ID
LEFT JOIN FilesetEntry D
ON A.ID = D.FileID
LEFT JOIN Blockset E
ON E.ID = C.BlocksetID
LEFT JOIN BlocksetEntry G
ON B.ID = G.BlocksetID
LEFT JOIN BlocksetEntry I
ON E.ID = I.BlocksetID
WHERE
A.BlocksetId >= 0 AND
D.FilesetID = (fileidnumber) AND
(I."Index" = 0 OR I."Index" IS NULL) AND
(G."Index" = 0 OR G."Index" IS NULL)
UNION
SELECT
B.Path
FROM
FilesetEntry A,
File B,
Metadataset C,
Blockset D,
BlocksetEntry E,
Block F
WHERE
A.FileID = B.ID
AND B.MetadataID = C.ID
AND C.BlocksetID = D.ID
AND E.BlocksetID = C.BlocksetID
AND E.BlockID = F.ID
AND E."Index" = 0
AND (B.BlocksetID = -100 OR B.BlocksetID = -200)
AND A.FilesetID = (fileidnumber)
) R
WHERE
R.Path = File.Path
)
I added a ‘fake’ problem that triggered my query and it shows that when there is a structural problem for a given file in the database, it impacts all filesets including this file. That’s why it’s not really useful to start to delete filesets. A better workaround would be to delete the file(s).
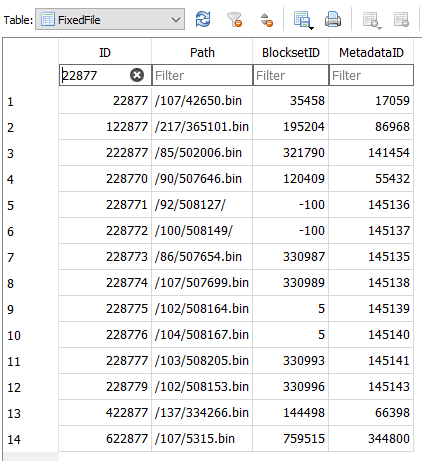
SELECT * FROM "FilesetEntry" LEFT JOIN "FixedFile" ON "FilesetEntry"."FileID" = "FixedFile"."ID" WHERE "FilesetEntry"."FilesetID" = 5 AND "FixedFile"."ID" IS NULL
If using an original database, refer to File view instead of FixedFile table in the database bug report.
Result table has 65 rows, probably corresponding to 65 reduction of calculated files versus fileset’s list:
is 65 short from the complex query that looks for data bits compared to the simple expected fileset list.
Above query (if I’m doing this right) means that again some records of old files got removed somehow.
looks like it might be trying to look in the other direction (if fileset had extras). EXISTS is also suspect, although all this comment is tentative. Regardless the query did not return any rows when I had run it.
Sorry. I quoted to the wrong one. I’m talking about this one:
I adjusted it to FixedFile (as I’m looking at the database bug report), replaced placeholder with 5, and played with NOT EXISTS versus EXISTS (true if a row is returned, so a NOT EXISTS is likely to be false unless all that querying (is this still the union of files and folders/symlinks) is not returning any row at all.
EDIT:
Ran it again. Original run returns 0 rows. If I change NOT EXISTS to EXISTS, I get 317826 rows which matches the calculated count reported by the user, so wonder if it’s trying to run the concept of NOT IN.
317891 which user reports as the expected value from the short (compared to huge one) SQL query.
EDIT:
Run of Duplicati short query also gives 317891 from this about-as-short-as-possible query SELECT COUNT(*) FROM "FilesetEntry" WHERE "FilesetEntry"."FilesetID" = 5
This is baffling, there is no filesetentry not referring an existing file then. I don’t understand why the not exists don’t return the missing entries.
Probably because EXISTS is true therefore NOT EXISTS is false and so filters out all rows in WHERE.
EDIT 1:
WHERE Filesetentry.FilesetID = (5)
AND FilesetEntry.FileID = FixedFILE.ID
AND NOT EXISTS (
EDIT 2:
Notice the lack of 228778 above. One possibility is some deletion decided to remove it, however these things are supposed to be coordinated. Did something (maybe network error?) block the coordination?
Ah yes, I see now. It’s the left join. These fileset entries are disconnected from any file name. So they can’t be restored anyway. This is impacting several filesets, so it is either a recurring problem, or generated by a misbehaving compact (more likely I think)
While I was waiting for the bug report to download, I have made a Pull-request to more accurately report this situation.
Could this specific point be related to the issue trigger ?
The data I was recovering from my ancient USB keys dated a time when I was an Apple user. They had files with non standard characters in the name files. Moreover, the corruped data files, as Grsync could extract them, had very strange characters in the file names. The size of the files were goofy too (how can a 100Gb file come from a 32Gb usb key ?)
Maybe when Duplicati tried to analyse these files before I could purge them and add them to the database, it messed something up ?
I think that it’s more likely than crashes have corrupted the database.
I’d say that a possible way forward could be first to do a deep test of the backend in the Command line mode of the Web UI, using ‘all’ as parameter and setting full-block-verification to true. Then if this goes well, exit Duplicati, rename the job database (find its name before closing Duplicati), then try to recreate it using the Duplicati.Commandline.exe utility:
Possible OS difference in how non-US-ASCII were represented long ago on Apple, versus current?
Non-English system for awhile used lots of 8 bit character code pages. Currently Unicode is typical.
I wonder how much of that time is upload speed limited, versus Duplicati processing time for big backup. blocksize is at default 100 KB which is slow past 100 GB. You have over 600 GB at destination, and the proposed deep test will download it all. The recreate might too (normally not, but damage may cause it). Keeping an eye on the Verbose output will give warning (if dblock files get downloaded, it may get long).
Regardless, it’s one way to proceed, and might let us save those 65 files, which interestingly are coming up in later backups as missing. This is different than the other database bug report, where losses varied.
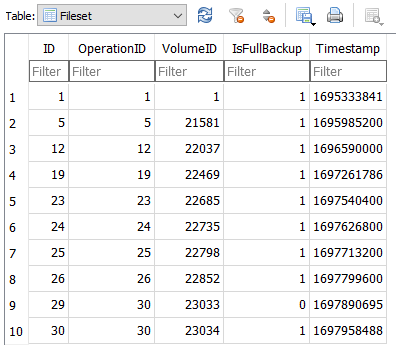
Here, with broken backup, it looks like the same names. Tested it first by manually trying each fileset ID. Out of 10, the oldest and newest are OK (by this test), and the other 8 have 65 losses, looking the same:
SELECT "FileID","Lastmodified" FROM "FilesetEntry" LEFT JOIN "FixedFile" ON "FilesetEntry"."FileID" = "FixedFile"."ID" WHERE "FixedFile"."ID" IS NULL
gives 520 rows (65 * 8). Add DISTINCT after SELECT, and row count drops to 65, so no variation I think.
is interesting because Backup at Operation 30 seemingly finished backup 29 before (shown as partial), probably using a synthetic filelist as mentioned in the other case. RemoteOperation table shows 29 did lots of put operations then kind of stopped before uploading its dlist on 21 Oct. Backup 30 uploaded:
I read both your post several times, and from what I understand (which is not everything, sorry), possible solutions from now on will mean downloading everything that is on the backup server. I don’t really have the space though, I would have to buy a new external hard drive just for this.
Maybe at this point it would be better for me to connect to the swift server with Cyberduck and delete everything, and start fresh with a new configuration file and database.
If I understand correctly, some 65 files on the backup server are goofy and causes the error. What I don’t understand is why I can’t just tell Duplicati “hey, backing up my current files is more important. Discard whatever old versions of the goofy things you have and just backup the current ones !” It’s not like my computer had crashed, I have everything right here on my computer… If this is about 65 files that he does not find anymore on my computer, they are probably one of many corrupted unsalvageable usb key garbage stuff that I voluntarily decided to delete… But, well, if I have to start fresh then I will do so.
Except if you have any idea that I can try without having to purchase a new hard drive to download the backup server ?
I’m not sure of what you are talking about here, if it’s the ‘test’ command, it downloads everything yes, but not for storing it, it’s checked one block at a time. The downside of ‘downloading everything’ from the cloud is real, but it’s a matter of bandwidth, especially if you are paying for it.
Nonetheless, I was suggesting a deep backend test because you had (from your history) quite a few crashes so the backend state is not known.
In this case you will have to upload everything again. It may be annoying if your bandwidth is limited, and also if you are paying for bandwidth.
It may be that it is possible, but just now I don’t know since it’s a problem I have not yet encountered and it could be the case that hidden somewhere in the mass of options there is one that handles it. The only thing that I can be sure of at this moment is that if the backend is all right, rebuilding the database will get rid of this stuff and build a new sane database (minus the history). The state of your database is strange and suggests either a bug or that it has been interrupted in an updating phase.
One thing I know too is that it’s possible to get rid of this extraneous data using Sql, but I’m not sure of the outcome.
Fortunately, my bandwidth is not limited. I pay a fixed amount per month no matter how much I upload or download. I just don’t like deleting the distant files.
Since I have backups of the database, I think it might be interesting to attempt a new database re-creation with the live log on verbose to see what happens. I don’t know why the last one didn’t proceed but know I have learn a buch of ways to watch what Duplicati is doing that I didn’t know before