Hi there! I’m pretty new with Duplicati, so please excuse me if I say something wrong.
I would like to use Duplicati with AWS Glacier Deep Archive. I took a look at the code, and I understand that for the compaction operation the volumes to be compacted are downloaded from the back end. This leads to wasted time and money using AWS Glacier Deep, as well as the fact that Duplicati probably doesn’t work out-of-the-box with AWS Glacier Deep, because a specific API call is required to initiate the process of retrieving a file (which will then actually be available about 12 hours later).
I was thinking that, in all cases where the files to be included in the new volumes are available on the local device, that it might be more convenient and cost-effective to create the new volumes from there, without then having to re-download the old ones.
Do you think it could be possible? Am I forgetting something?
I don’t think this will work. Remember, Duplicati keeps multiple versions of files. Or more correctly, it keeps blocks from multiple versions of files. It probably doesn’t have much of a chance of using only blocks from the latest version of files during a compaction event.
For AWS Glacier we usually recommend you use unlimited retention, disable testing, and disable compaction.
An alternative that I and others are experimenting with: use AWS to hold only a copy of your Duplicati backup data. All my PCs back up to my NAS, and then the NAS synchronizes with AWS. I use a lifecycle policy on my S3 bucket to transition files to deep archive after so many days. With this approach I don’t have to use unlimited retention, nor do I have to disable testing or compaction. The only time I’ll ever need to read data from my S3 bucket is if my primary backup gets destroyed for some reason.
Yes, I thought about it, I imagined in fact this as an additional feature, to be applied when possible, and in all other cases we could continue compacting as it is done now (or disable it in case of particular storage, such as Glacier Deep).
I think I’ll start that way, then maybe in a few months I’ll try to come up with some statistics to see if what I’m doing makes sense, or I’m wasting too much space, since I wouldn’t need to keep all the versions.
If you leave it enabled and set up logs at whatever verbosity level you can stand, you get messages like
so I think you can at least sometimes go straight for delete if it gets to completely empty before threshold.
--threshold=<percent_value>
The amount of old data that a dblock file can contain before it is considered to be replaced.
2022-01-21 15:54:28 -05 - [Verbose-Duplicati.Library.Main.Database.LocalDeleteDatabase-FullyDeletableCount]: Found 2 fully deletable volume(s)
2022-01-21 15:54:28 -05 - [Verbose-Duplicati.Library.Main.Database.LocalDeleteDatabase-SmallVolumeCount]: Found 2 small volumes(s) with a total size of 8.82 MB
2022-01-21 15:54:28 -05 - [Verbose-Duplicati.Library.Main.Database.LocalDeleteDatabase-WastedSpaceVolumes]: Found 24 volume(s) with a total of 6.03% wasted space (824.01 MB of 13.35 GB)
2022-01-21 15:54:28 -05 - [Information-Duplicati.Library.Main.Database.LocalDeleteDatabase-CompactReason]: Compacting because there are 2 fully deletable volume(s)
Setting compact threshold to 0% will maybe compact eternally. I haven’t tested setting it to 100% though.
This probably merits another look, but trying to optimize it for different storage pricing is kind of complex.
Threshold too low makes churn and eats bandwidth Setting high maybe holds wasted space too long…
Compact - Limited / Partial is a big discussion on this, but ultimately any changes may need a volunteer.
Duplicati’s progress and success is very much limited by people volunteering to contribute in some way.
and “disable testing” is going to have some effects, but I don’t use Glacier so I’m not sure how much.
I assume “disable testing” means the Verifying backend files step that sample-downloads some files.
How well and fast do other Duplicati operations like file list and delete operations work on Glacier
without having to suffer through a long wait? If those two don’t work, that’s another loss, so contents
can’t be verified at the file level either. There’s also the case where a failed put gets a delete then a
retry put under a different name. A list may be tried to check on the original failure or the recovery.
All of this odd handling is why I’m not a big fan of cold storage. In comparison, Google Cloud Archive
class sounds like it acts like hot storage, with the primary difference being in the way that you pay…
I’m not sure where to follow up. This is slightly related to both @cristianlivella topics, but not totally.
This setting implies that flying blind is necessary, which would go against the goal of good backup integrity.
Duplicati.CommandLine.BackendTool.exe using URL from Export As Command-line could directly test the necessary Duplicati S3 operations. Duplicati doesn’t support the Glacier API directly, and I don’t know what lifecycle policies and manual operations you would need to get reliable backups for your disaster recovery.
There is probably some other discussion in the forum about this, but it’s definitely not my area of expertise.
I’ve been also thinking a lot the compaction. I made suggestion for the same goal, but from different point of view: Compact - Limited / Partial
Yet for your situation, my best suggestion is to keep small volumes. Because you don’t need to download for compacting, if you’re just deleting obsolete volumes. If volume and deduplication block size are the same, then there’s no need to download any blocks to release blocks. - I’m not saying it would be practical solution for all cases, but in some cases it could be. Like with my backup sets, where I backup disk images and other large archives. Which aren’t basically ever modified, nor there’s anything to deduplicate. So using huge “dedupe block” solves this issue.
compression probably allows still multiple deduplication blocks in a volume, if blocks are very highly compressible. - Yet in my case, the data is already precompressed and encrypted, so this isn’t the case and I’ve disabled compression.
Perhaps the “practically disables” moves closer to “disables” if a big blocksize makes wastepercentage jump to 100% when its one block turns to waste. Maybe in other cases, rounding somewhere stops it, or
As a technical side note, the blocks in a dblock file may include small blocks such as metadata that don’t follow deduplication blocksize, so you might get a dblock volume that’s almost-but-not-completely empty.
Threshold based compacting at a volume level would do a download-compact on the remnants, but this might require a compact trigger at the destination level, if I recall correctly, and I haven’t looked in awhile.
--threshold = 25
As files are changed, some data stored at the remote destination may not be required. This option controls how much wasted space the destination can contain before being reclaimed. This value is a percentage used on each volume and the total storage.
Feature Request: Time Limit for Compaction is another feature request aimed at limiting long compact run. Tweaking the single threshold setting could not get there. Maybe separate settings for destination and the individual volumes could reduce the avalanch effect a little, but it all needs to be thought out – and written…
Please let us know if you have any comment on what I’m saying based on my rather limited look awhile ago.
Just wondering if --no-auto-compact prevents deleting fully obsolete blocks and files. If I remember correctly it doesn’t. So it’s pretty much same as threshold=100, but more explicit. My point with having same file size and deduplication block size, was that there’s only one block per file, so technically there’s no need to compact. Just delete the block or not. → It doesn’t end up wasting space like “partially filled” files after parts of those have become obsolete. Which is exactly what compaction clears out by downloading and writing new blocks.
It appears to disable checking for whether Compact is needed, as evidenced by my log after that change, done recently to prepare for manual compact under close observation to see if it’s the source of an issue:
Part (but not all) of my backup is similar to yours, where compressed files larger than dblock size change, tending to turn the whole dblock into waste all at once (I think – regardless, I do get whole-dblock deletion).
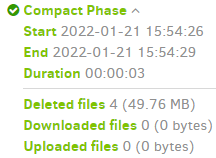
2022-01-21 15:54:28 -05 - [Information-Duplicati.Library.Main.Database.LocalDeleteDatabase-CompactReason]: Compacting because there are 2 fully deletable volume(s)
2022-01-21 15:54:29 -05 - [Information-Duplicati.Library.Main.Operation.CompactHandler-CompactResults]: Deleted 4 files, which reduced storage by 49.76 MB
2022-01-21 17:53:01 -05 - [Information-Duplicati.Library.Main.Database.LocalDeleteDatabase-CompactReason]: Compacting because there are 1 fully deletable volume(s)
2022-01-21 17:53:02 -05 - [Information-Duplicati.Library.Main.Operation.CompactHandler-CompactResults]: Deleted 2 files, which reduced storage by 31.15 MB
2022-01-21 19:53:45 -05 - [Information-Duplicati.Library.Main.Database.LocalDeleteDatabase-CompactReason]: Compacting not required
(after here, other lines happen, but lines on Compact do not)
but I pointed out that there could be other blocks (such as metadata), and those need to be preserved too.
Test a backup of a folder with a one-byte file to see how many dblocks you can force. Maybe look inside it. Probably you’ll get just one dblock containing folder metadata, file metadata, and the source file byte itself.
EDIT:
Statistically, your plan is good if one dislikes downloads, but if Glacier errors on delete, one is too many.
It seems nobody here so far knows how Glacier works when all one has access to is the primary S3 API.