@drwtsn32 - Ref: Is Duplicati 2 ready for production? - #73 by drwtsn32
I’ll reply here, because the ready for production thread is wrong for this topic. It was just important that it’s important to people know that there are several trust issues. And that it’s extremely important to actually restore test from destiation and without the local blocks or duplicati database at hand.
About the Backend, I upgrade the Filezilla Server version. I updated all Duplicati’s to the latest version and triple checked everything on the backend, including all backups and other massive files with hash-validation, so I know that the backend itself is not corrupting data. We did also mem-test it and full storage system tests, on several levels. Also, all tranports are over TLS so there’s integrity check.
Then to the problem, why I don’t suspect the backend to begin with, but I also checked it.
I saved the smallest backup + source configuration. So I can repeat the problem. I can’t well reproduce the problem how it initially formed, but I can reproduce the restore error + run tests and repair which both end up saying that everything is good.
Unfortunately I’m also business software developer, so I have decades long history of trouble shooting multiple complex business systems including my own code which fail in multiple different agonizing ways. I just today told my colleague that if this would be my own code, I would be really pissed, because I would know it’s broken, but I couldn’t easily and quickly tell exactly what lead to it.
The trail is similar, something ends up being wrong in the destination, it could be left over file or something. Something which messes up the restore logic. I can’t directly say with confidence, if it’s the backup or the restore which is causing the problem.
Let’s recap what I know. I know that the latest version of Duplicati seems to handle the roll forwards much better than the old versions, which well, in some cases systemically failed. But with the latest version I see that if it uploaded file A and it wasn’t finished, it’s deleted or re-uploaded. And also the compaction even if aborted seems to at least in most of cases work as I would transactional system expect to work.
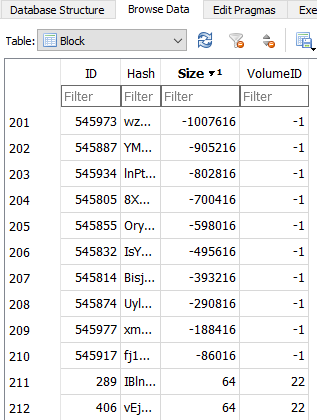
This is not a single event. I run, well, many backup sets daily. And in this case, I just had two failing sets, but both with exactly the same problem. And now it’s important to remember that the test with full remote verification passes. So there are NO MISSING FILES, and ALL THE FILES GOT CORRECT HASH… If we can assume that the test / repair itself isn’t flawed?
I did also reset the failing sets today, and re-backup from source. And both restores were successful after that, without any configuration changes. So that’s not the problem either.
Based on all this, I’m pretty confident that there’s quite simple (!) logical mistake or implementation error somewhere. We’re very very close to the goal.
Yet, as said, my experience is totally generic about file transfer, database, transactions and other failures with related logic. I’m not Duplicati expert. How could we get forward from this point? I’ve collected all forensic evidence about the event.
It would be all so wonderful easy, if the backup set didn’t contain data, which I couldn’t share with you guys. I would just upload the whole packet somewhere. But in this case that’s not possible. But the data is practically meaningless to you and I’ve got no problem with IP addresses, or even credentials, because it’s all on closed system.
I assume you as Duplicati expert know the best, what I should share with you. I really would love to help, this is very frustrating for me as well. If I wouldn’t like Duplicati I would have dropped and swapped to Restic a good while ago. Yet I really did think about that hard again today. But this is hopefully the last logical issue somewhere?
I’ll share you the numbers confidentially, so you’ll understand how many backups I’m running daily, and how rare this issue is. Btw, even the filenames in the backup are totally meaningless, as long as the file contant itself is kept private. So I could share directory listings, whole databasse (the duplicati database) as well as destiation file listing and all the hashes of the files in the destiation folder.
And depending on the database restructuring phase, in theory this all could be caused by something like one extra file being left at target. Sure. Yet I still don’t understand why the repair wouldn’t clear it up. That’s the major question why there are two conflicting truths simultaneously.
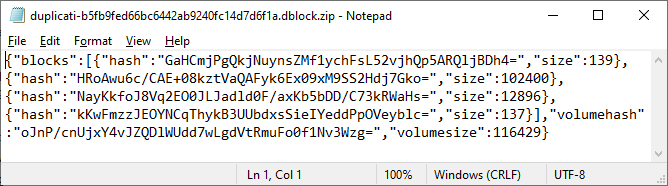
How should we should continue? After thinking a while, my assumption is that I could give you everything, except the dblock files, username and password to the destination, full command lines I use for backup & compact, etc without uid/pwd. Yet I would include file hashes of all files. Would that be helpful? Would you need something else?
Update: data packet delivered with logs and reproducible case where tests pass and restore fails, with full debug & profiling logs. Inclunding database & iblocks and dlists.