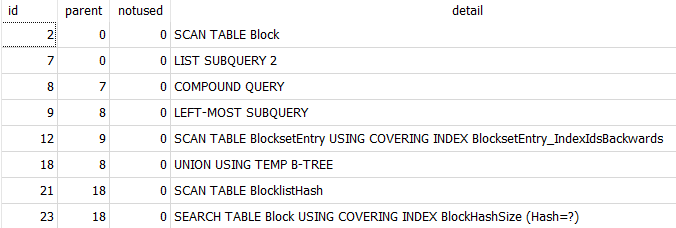
I do… while I can’t claim to wholly understand how Duplicati manages it’s database, in the example of the DELETE operation it’s pretty obvious to me what’s going on. I’m going to walk you through my thinking, so if I’ve made an error please let me know.
From the profiling logs, these are the SQL statements that are executed for the DELETE operation.
DELETE FROM "Fileset" WHERE "Timestamp" IN (1686226500)
DELETE FROM "FilesetEntry" WHERE "FilesetID" NOT IN (SELECT DISTINCT "ID" FROM "Fileset")
DELETE FROM "ChangeJournalData" WHERE "FilesetID" NOT IN (SELECT DISTINCT "ID" FROM "Fileset")
DELETE FROM "FileLookup" WHERE "ID" NOT IN (SELECT DISTINCT "FileID" FROM "FilesetEntry")
DELETE FROM "Metadataset" WHERE "ID" NOT IN (SELECT DISTINCT "MetadataID" FROM "FileLookup")
DELETE FROM "Blockset" WHERE "ID" NOT IN (SELECT DISTINCT "BlocksetID" FROM "FileLookup" UNION SELECT DISTINCT "BlocksetID" FROM "Metadataset")
DELETE FROM "BlocksetEntry" WHERE "BlocksetID" NOT IN (SELECT DISTINCT "ID" FROM "Blockset")
DELETE FROM "BlocklistHash" WHERE "BlocksetID" NOT IN (SELECT DISTINCT "ID" FROM "Blockset")
INSERT INTO "DeletedBlock" ("Hash", "Size", "VolumeID") SELECT "Hash", "Size", "VolumeID" FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" AS "BlockID" FROM "BlocksetEntry" UNION SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash")
DELETE FROM "Block" WHERE "ID" NOT IN (SELECT DISTINCT "BlockID" FROM "BlocksetEntry" UNION SELECT DISTINCT "ID" FROM "Block", "BlocklistHash" WHERE "Block"."Hash" = "BlocklistHash"."Hash")
UPDATE "RemoteVolume" SET "State" = "Deleting" WHERE "Type" = "Files" AND "State" IN ("Uploaded", "Verified", "Temporary") AND "ID" NOT IN (SELECT "VolumeID" FROM "Fileset")
From this I can infer the data hierarchy:
-Fileset
|-FilesetEntry
|-FileLookup
|-Metadataset
|-Blockset
|-BlocksetEntry
|-Block
|-BlocklistHash
|-Block
|-ChangeJournalData
Looking back at the SQL statements, the methodology is clear:
- Delete the root of the hierarchy (Fileset) for the fileset identified by timestamp 1686226500
- Go to the first child of the root (FilesetEntry) and delete all records that do not have a parent.
- Go to the second child of the root (ChangeJournalData) and delete all records that do not have a parent.
- Go to the first child of FilesetEntry (FileLookup) and delete all records that do not have a parent.
etc…
Put another way, the methodology is to delete a parent, and then go to the child table to look for all orphans and delete them.
I’m suggesting that it’s more efficient to start at the bottom of the hierarchy and delete all records there with an ancestry from the identified root. Then, keep moving up the hierarchy and do the same thing.
Let’s look closer at the DELETE statement for the Block table:
DELETE
FROM "Block"
WHERE "ID" NOT IN (
SELECT DISTINCT "BlockID"
FROM "BlocksetEntry"
UNION
SELECT DISTINCT "ID"
FROM "Block"
,"BlocklistHash"
WHERE "Block"."Hash" = "BlocklistHash"."Hash"
)
In plain English: delete everything in Block that doesn’t have a parent in either BlocksetEntry or BlocklistHash.
We know what we want it to delete though… there’s no reason to search for all the orphans. Instead we can say: delete records in Block that have a BlocksetEntry or a BlocklistHash belonging to the Fileset with timestamp 1686226500.
In SQL:
DELETE
FROM block
WHERE id IN (
SELECT blockid
FROM blocksetentry
WHERE blocksetid IN (
SELECT id
FROM blockset
WHERE id IN (
SELECT blocksetid
FROM filelookup
WHERE id IN (
SELECT fileid
FROM filesetentry
WHERE filesetid IN (
SELECT id
FROM fileset
WHERE "timestamp" IN (1686226500)
)
)
)
)
)
OR id IN (
SELECT id
FROM block
JOIN blocklisthash ON block.HASH = blocklisthash.HASH
WHERE blocksetid IN (
SELECT id
FROM blockset
WHERE id IN (
SELECT blocksetid
FROM filelookup
WHERE id IN (
SELECT fileid
FROM filesetentry
WHERE filesetid IN (
SELECT id
FROM fileset
WHERE "timestamp" IN (1686226500)
)
)
)
)
)
It’s worth noting here that the existing code is running the same expensive query twice… once to insert the deleted blocks into the DeletedBlock table, and then a second time for the actual delete operation. It would be more efficient to run the query once, and then for each record returned, write it to DeletedBlock and then delete it. In Oracle I would do that with a cursor and a for loop. I don’t know exactly how that would be done in sqlite, but I’m sure it’s possible.
Carrying on with my proposed methodology, after the Blocks are deleted you can go up the hierarchy and delete the BlocklistHash and BlocksetEntry that belong to the Fileset with timestamp 1686226500.
Once that’s done, you can go up the hierarchy and delete the Blockset that belong to the Fileset with timestamp 1686226500.
And so on, until you’ve made it to the root and delete Fileset with timestamp 1686226500.
That’s my thinking. Of course you are correct that none of this answers my original question as to WHY the update caused my backup job to slow down. However, optimizing the delete operation will likely make my original question irrelevant.
I’m going to do a test of my methodology to see what it looks like performance wise. I’ll reply with the results once it’s done. In the meantime, I’d love to know what you all think.
EDIT: I’m now realizing that the Many-to-One relationship between FilesetEntry and FileLookup foils this plan. I need to think on it more, but at the very least, my suggestion about not running the same query twice is still valid.