I’m using Duplicati 2.0.5.1_beta_2020-01-18 running as a Service on Windows Server 20212 R2, backing up to a Google Drive. The server has 16GB of RAM in it, and floats around 40% memory usage and 12% CPU. It’s backing up a very large number (150k-ish) of small-ish (<10MB) files.
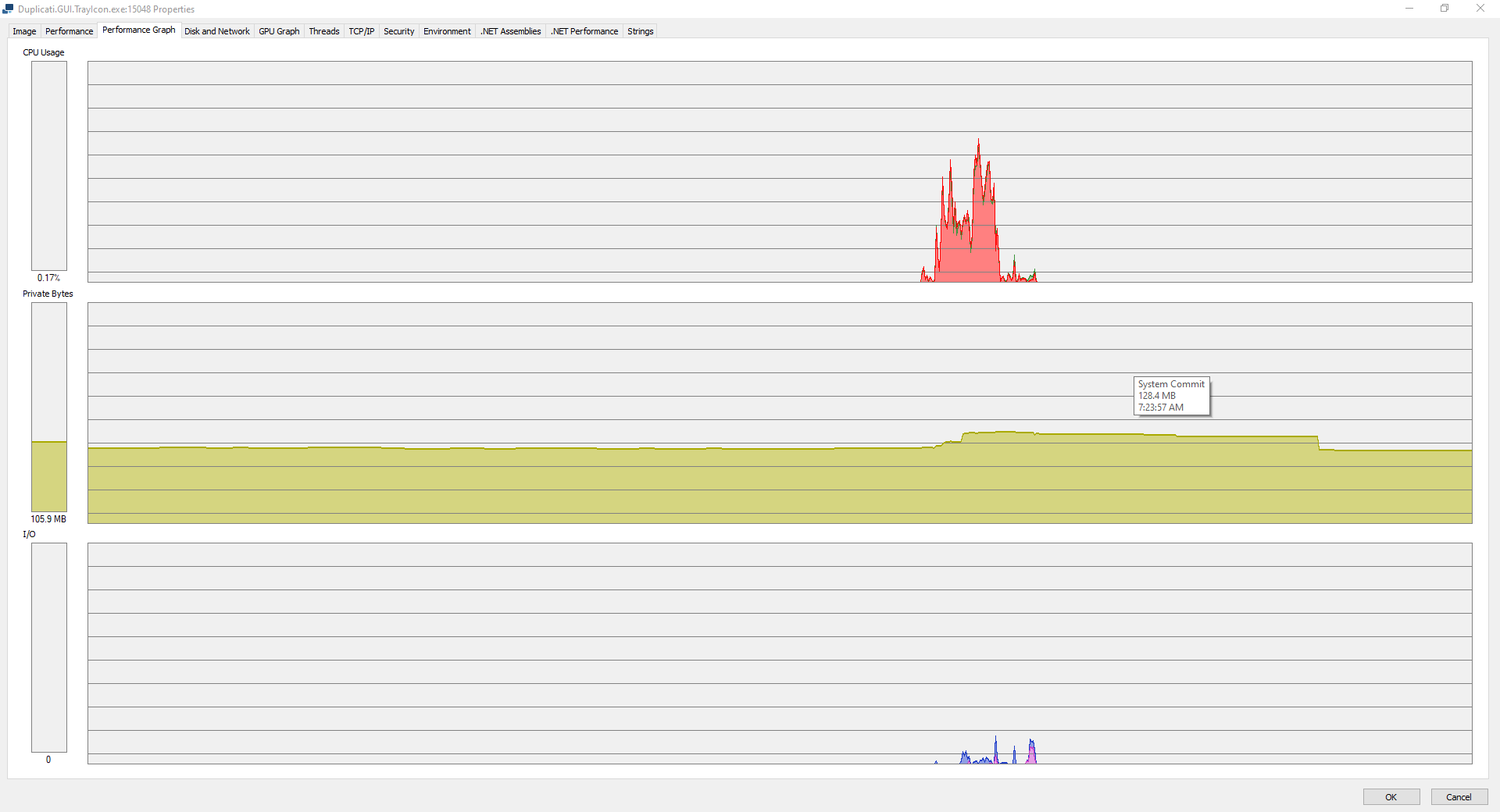
When doing a backup to Google Drive, I notice that Duplicati’s memory consumption seems unusual. It’s reserving 32MB of working memory, and commit memory of 1.0GB.
Duplicati is triggering a lot of page faults - I’ve seen values of over 100 - and as a result is thrashing the pagefile horrendously, making it a real choke point on the I/O of the whole server. End users start to complain about poor file serving performance. (Unfortunately, the pagefile and the data volume are on the same physical disk/RAID array).
I can’t understand why Duplicati isn’t using more physical RAM, or what would be triggering the page faults. I’ve got some options set to try and calm it down -
backup-test-percentage=0
backup-test-samples=0
disable-file-scanner=true
snapshot-policy=off
use-background-io-policy=true
tempdir=(a directory on a separate USB3.0 connected drive)
Any thoughts on how I can stop it thrashing pagefile and blocking up the file system I/O?
I see you have a 150k files or so, but what is the total amount of data that Duplicati shows for the “source”?
Also your use of a USB drive for the tempdir may be an issue. I have seen USB drives cause I/O issues on entire servers before. Can you temporarily change it to use regular internal storage?
Total payload to be backed up is 1.4TB. (Duplicati doesn’t show an accurate source because I’ve got the disable-file-scanner option on. When I previously had it at default behaviour it confirmed it was trying to back up 1.4TB).
I moved the temp to USB because the temp as on C, the pagefile was on C and the data is also on the same physical disk. I was monitoring performance before and after and moving the temp to the USB3.0 seemed to improve throughput. Happy to try putting it back, but it didn’t seem to cause the memory / page fault issues that are smashing the pagefile so hard. (Most times the pagefile is the highest consuming file handle in terms of disk activity, followed by all 5-8 files Duplicati has open).
I agree USB is not related to memory issues / page faults, but it may be related to I/O blocking you are experiencing. Just as a test see if it makes any difference for that particular issue.
1.4 TB is quite a large backup set for the default block size of 100KiB and can result in slow database operations. I am guessing you have a large job-specific sqlite database. Might be interesting to see if you detect any difference after doing a VACUUM operation on the database.
How long have you been using Duplicati to do backups? What is your retention?
So far the backup hasn’t run to completion, because I’ve also been dogged by Google Drive “403 Forbidden” errors which cause the backup to fail. Each time I restart, it has to work through the entire fileset again to work out what it’s already backed up and what needs to add. The retention policy is 1 - we just need one copy of everything somewhere off site.
The pagefile thrashing has reached the point where it’s the largest single disk activity by far; this morning I caught it with nearly 165 Hard Faults (1.4GB of virtual memory, still on 32MB of real memory), and the pagefile sat at the top of the disk activity queue.
As the backup hasn’t completed yet (and not helped that our upload speed is only 20Mbps), and I can’t change block size once a backup has started, I’m going to start with a new backup job but with a 5MB block size, and 100MB volume size, and see if that reduces the transactional activity.
I just entirely deleted and recreated my backup job from scratch. I just started it running, and at 30 seconds into this job, this is the memory situation
I can’t understand why Duplicati’s working memory set never gets above 32MB, when the commit memory is so much larger relatively - and seems to be causing hard page faults?
For information
block-size is now 10MB (most of my files are around 30-40MBs)
volume size is now 200MB
On today’s config of 10MB block size and 200MB volume size, I’m seeing the same ratio of Commit (1.4GB) to Working (32MB), but the hard faults are sat more manageably at 10 or fewer and pagefile thrashing is much reduced. Not surprisingly, performance is generally better.
Would you be willing to test 2.0.5.112 to see if it makes any difference? I don’t normally recommend people use Canary, but in my opinion that Canary release is better than 2.0.5.1. Note that you cannot downgrade back to 2.0.5.1 easily - if you decide to test this Canary version you should probably stick with it until the next Beta version to switch back to the Beta channel.
Yes, I’ll be happy to do that, if you know there’s changes in it likely to help the problem.
The backup I started yesterday is still running, and I’d really like one backup to complete first. It’s got about 5 days to go, so I’ll switch to the Canary then (unless it fails before that).
A relevant point - as I mentioned, initially I was getting periodic 403 Forbidden responses from Google Drive (which I think was probably rate or volume limiting cutting in), which was ending the backup after every 30-40GB of upload. When I restarted the backup, it had to work its way through all the files again, from scratch. The log was reporting a difference between the date/time stamps on the files (correct date/time) and the date/time recording in the database (1970-01-01 00:00:00 (epoch)).
It was during this “catch up” that the worst of the page faulting was happening - up to 200 page faults a second.
I’m guessing (knowing nothing about the internals of either Duplicati or SQLite) that the problem was database related (?). Maybe it’s SQLite that is not pulling more of the database into Working RAM, which is why the commit RAM grows hard (and massive pagefile thrashing) and the working RAM sits at 32MB? (There’s more than 8GB of working ram free).
How did it look before this job ran, or for that matter at Duplicati start with no job going?
If it’s unknown, then maybe we must wait for backup to complete (or maybe die again).
If you’re willing, 2.0.5.1 should be able to do a “Stop after current file” but it’s not instant.
You would get a partial backup, able to restore whatever it got, and it can continue later.
In your case, later might be after a Duplicati restart and setup for watching it carefully…
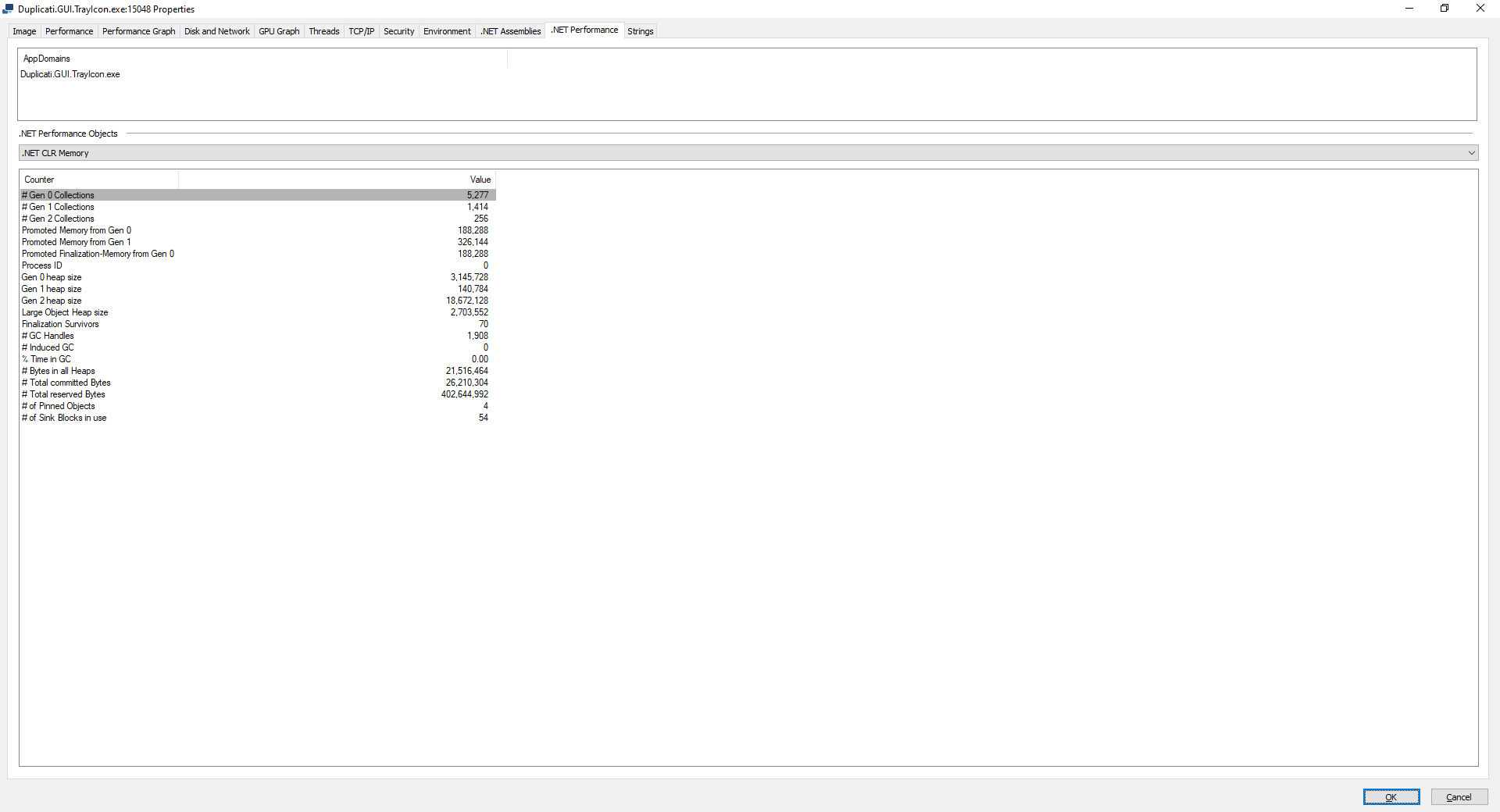
and in the above, # Total committed Bytes is less than the whole process System Commit.
Neither is big enough to hurt me, but you might want to watch yours for its “where” and “when”.
I had thought SQLite memory usage was fixed, and so for a huge DB it does its own thrashing. cache size is actually one of my guesses for why Duplicati slows down when backups get big.
Although Duplicati doesn’t permit tuning that yet, it does support this, even from Commandline:
Usage: vacuum <storage-URL> [<options>]
Rebuilds the local database, repacking it into a minimal amount of disk
space.
and there are some other options for vacuum if this helps something. How big is your DB now?
I don’t have a feel for how large it should be for the backup you described, but somebody might.
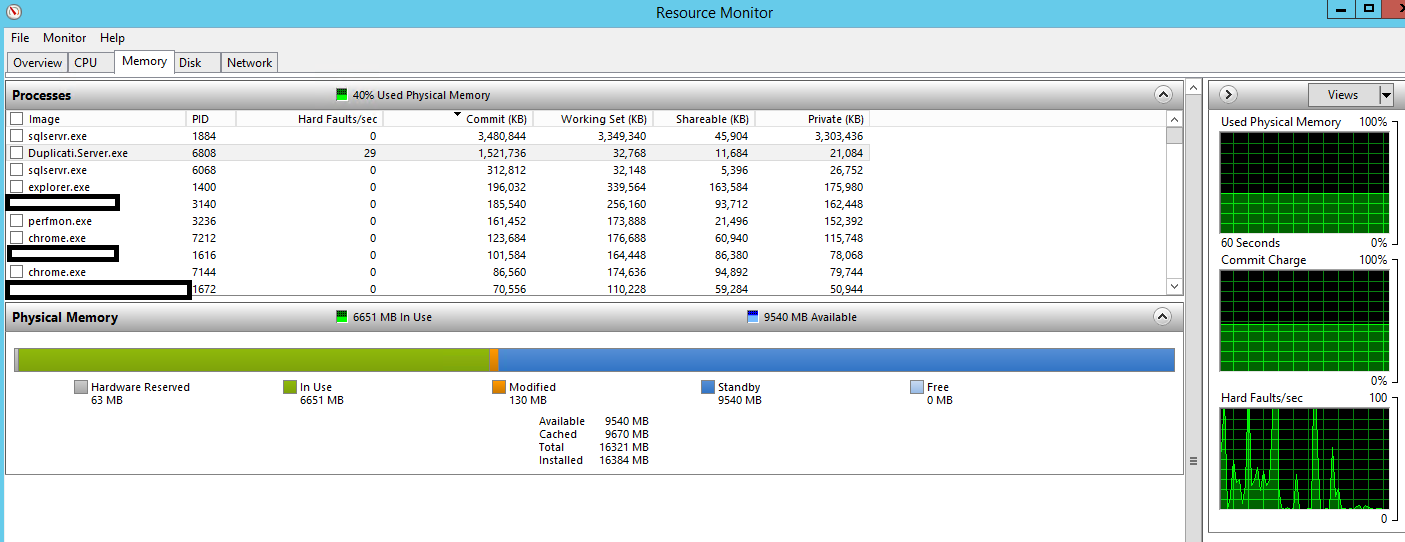
With the Duplicati service Started, but no job processing, I typically see just the Duplicati Working RAM sat at 32MB(ish) and around 100MB of Commit.
In that state, the 16GB of RAM is showing 7-8GB in use (mostly MS SQL at 4GB) and 8-9GB available. There’s no pagefile interaction, and most of the time the server has 5-6 clients connected to Windows shares, pulling no more than 100Mbps from the drive at once. CPU hangs around 10%.
I’m very anxious to get at least one full backup set into the cloud asap, so I’m going to let 2.0.5.1 run until it either falls over with an error or completes. Then I’ll get 2.0.5.112 on there, and try a backup to a different destination. I’ll get sysinternals installed so I can get a different view of CPU and memory consumption (I’m currently using the MS Resource Monitor and MS Performance Monitor).
The previous backup job (the one that I killed when it was about 60% complete) had a SQLite DB file of 3GB. I tried a vacuum on it (from the command line), but it wouldn’t accept that I had no encryption pass phrase set.
If not using the GUI Commandline (i.e. if at Command Prompt), you need to bring the options yourself.
You probably also can’t run vacuum (or many other operations) when in the middle of running backup.
Can you post that message? The per-job database has no encryption, but the server database might.
If using a real CLI, it’s possible to have messages like that. It’s independent, and needs options given. Export As Command-line is a way to have what you need (and then some) to non-GUI Commandline.
This got an informational note for The BACKUP Command, but the same options need applies widely.
At 2GB behavior is the same. At 1GB I began to see numerous hard faults.
I’m not a SQL expert but from my experience it is a memory pig and seems to assume it’s the only thing running on a server. How much free memory does Resource Monitor show when Duplicati is running? 0MB? SQL can be tuned to use less than “all the RAM”.
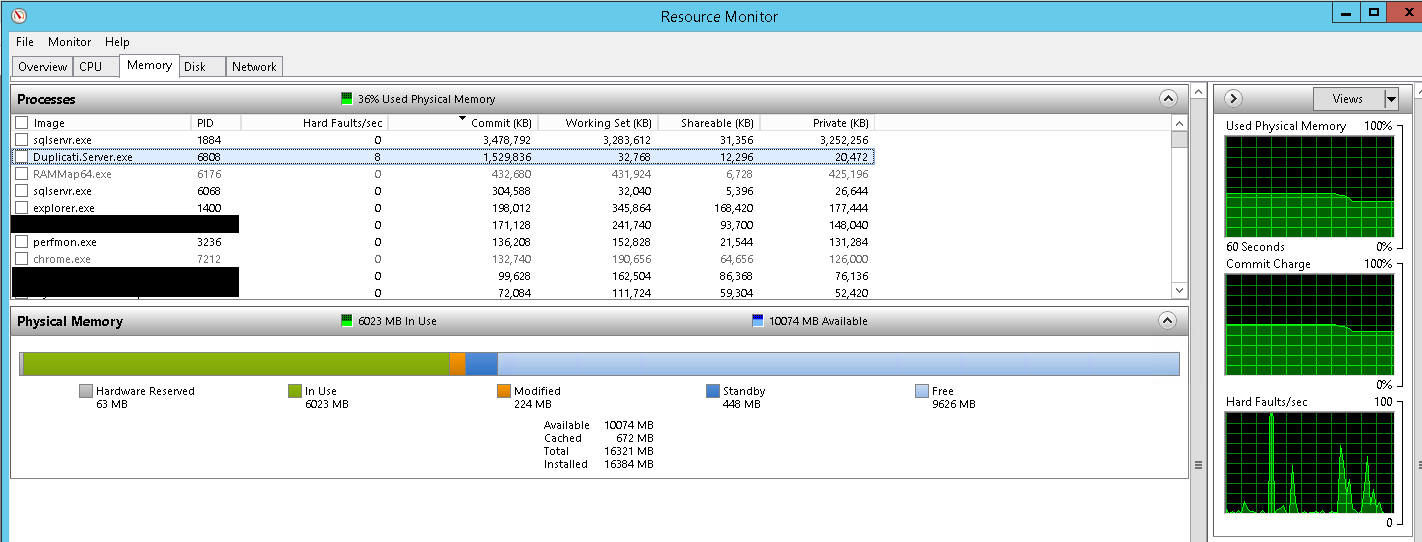
(This screenshot is taken just now, with a 10MB block size and a 200MB volume size, and there’s been no errors from Google Drive to cause the job to abort. But you can see it’s still throwing page faults).
My theory at the moment is that the crippling page faults happen as a result of this set of circumstances:
Block size is small (100KiB) and volume size is 100MB.
Backup job starts, and processes a “large” (let’s say 30k) number of files (around 30-40MB each)
Backup job aborts - in this case because Google Drive throws a 403 Forbidden error
Backup job restarts - it works through the files in the same sequence, and compares the date/time stamp of every file with the database. So it’s finding the object in the database, but then spotting that the date/time stamp in the database is “1970-01-01 00:00:00” which doesn’t match the date/time of the file. This causes…??? A recheck of the hash in the file?
It seems to be when the job restarts that you see huge numbers of page faults. I’m guessing the SQLite DB is already 3GB in file size by this point because it’s indexing (30 000 x 30 000 / 100 =) 9 000 000 blocks.
What I can’t understand is why the working set stays jammed at 32MB. You can see that SQL is growing to 3.4GB, and there’s tons of free “actual” RAM to work into.
I think the reason you see page faults is because you have 0 MB Free, according to the screen shot of Resource Monitor. In my testing I didn’t see page faults until I was in the same situation. (I am not running SQL, but I could replicate the issue by lowering the VM memory to 1 GB.)
I don’t think the page faults have anything to do with your block size, volume size, hitting Google Drive limits, etc.
I am not sure why you see the working set at 32MB, on my test it was higher and closer to the Commit number.
The Standby RAM is just a loose cache, which should be released if anything requests “real” RAM. That happened to appear maxed out because Chrome had been running for a while, so I quit Chrome and it actively flushed Standby down.