TL;DR
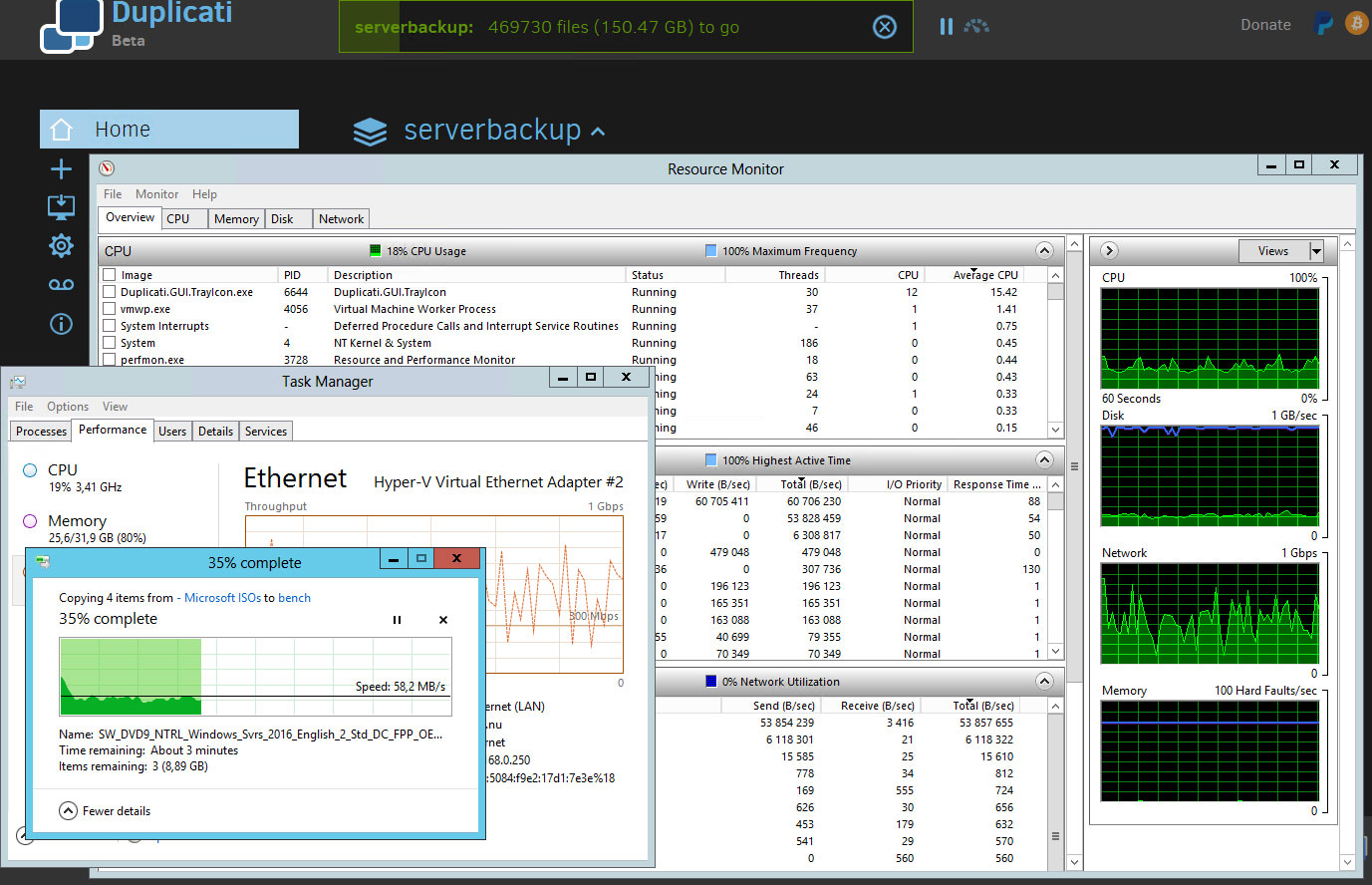
Copying files between two computers runs at 500-1000Mbit.
Backup job between the same two computers runs at max 50Mbit.
. Setup:
Duplicati on Winsrv 2012. 32GB ram, SSD system disk. 7200rpm data disks.
Minio on virtual Debian9 on same box. 1GB ram. system on own SSD, backup store on own 5400rpm disk. The two are (obviously ) directly connected network wise. 1Gbit.
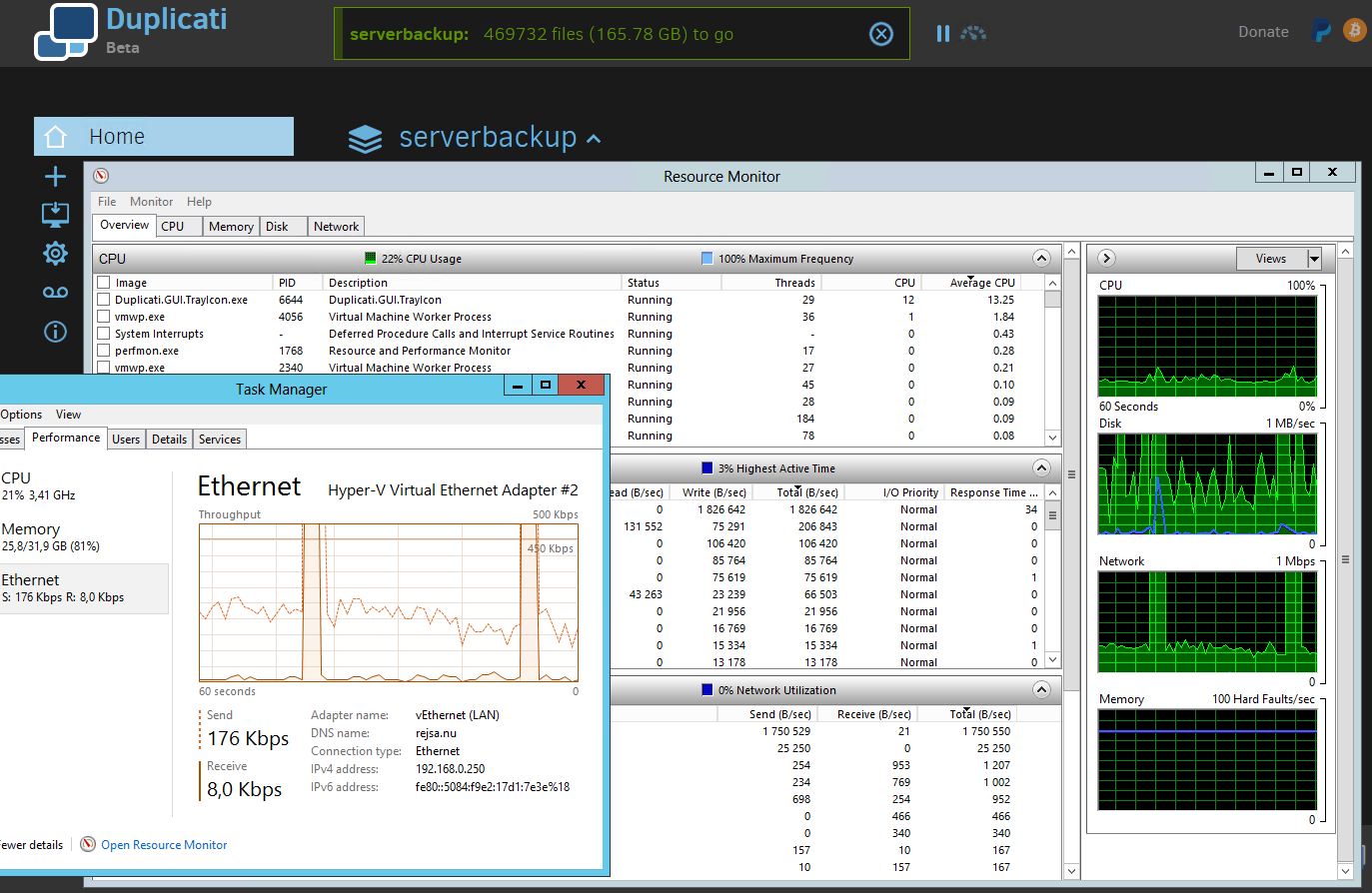
Scenario One: Duplicati backup job.
According to the windows and Debian tools network speed hovers around a few hundred kbits with much faster but short bursts. Clocking the count down on the Duplicati web page’s “to go” counts down roughly around 5MB/s.
I find nothing special when looking in Windows Resource Monitor regarding disk, cpu, mem or network load. Duplicati as service runs at 13% cpu. Nothing special in Debian top, htp, iftop as far as I can tell. Very low loads on everything. See screenshot below. I also tried running a backup job from another (physical) computer to the same Debian/Minio virtual computer. Exactly the same speeds and system loads.
Scenario Two: Copy files
500-1000Mbit. See screenshot below.
If I’m to understand correctly, Duplicati doesn’t do parallel processing / multithreading - so I suppose maybe that means it doesn’t prepare dblock chunks and upload chunks at the same time, which would explain the pattern you’re seeing. It’s spending ~80 - 90% of its time preparing and processing dblocks, and then (because of the fast local file transfer rate) only 10 - 20% of the time actually uploading.
(I might be slightly wrong about that - I at least know it doesn’t attempt to upload multiple chunks at the same time, i’m less sure whether it prepares dblocks during an upload or not)
As I’ve asked elsewhere: are you overriding the default volume size of 50mb? I believe such tiny chunks cause a lot of overhead in terms of the engine switching back and forth between preparing a chunk then uploading it, and any upkeep needed between each repeat of the above. For local destinations I’ve been recommending between 500MB and 2GB block sizes (though for remote destinations I think it’s best to stay under 200mb, when download bandwidth isn’t free). If you’re running benchmarks, it might be worth a shot - i’d be curious to see whether the numbers pan out.
The default setting of 50MB is probably good for my intended final setup, backing up over internet where I only have 100Mbit anyway. But the first run prepping the new backup computer will be done locally, that’ll take a while being 8TB or so
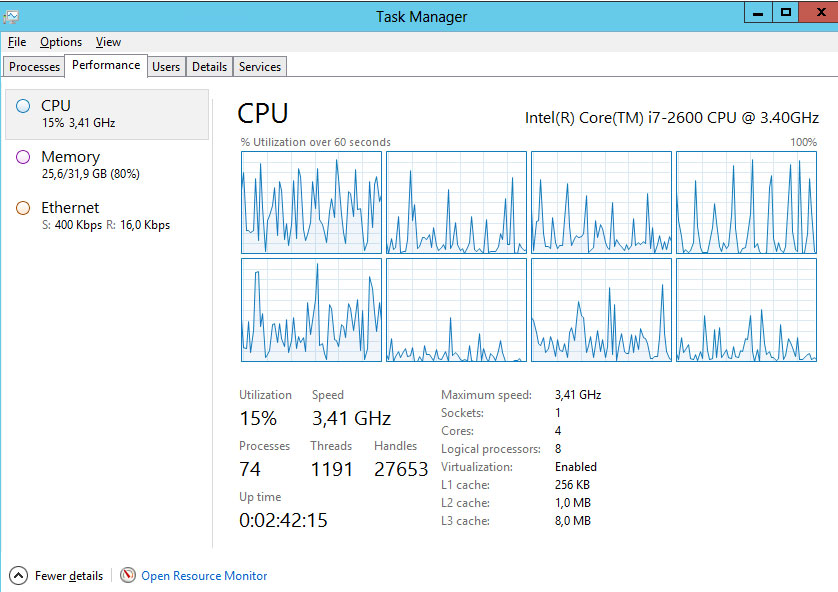
This actually makes sense. You’ve got 8 cores, so a single core maxed out running Duplicati would be 12.5% of your overall. As @drakar2007 mentioned, Duplicati can’t take advantage of multiple cores yet.
A few things you could try:
Try running the latest Canary (if you aren’t already on it) as it has a new hashing mechanism which should be a good bit faster
Bump your dblock size even if only to 100MB (definitely keep your network considerations in mind, but I doubt with a 100Mbit connection you’ll notice)
Lower compression level to 1 or 2
Set exclusions for Defender/AV (don’t see it as a problem in your screenshots)
One other more drastic thing you can do depends on your source data. I started off with one backup job, but ultimately went back and split it into two. One for normal folders/files, and a second for my archive of old software, ISOs etc. Essentially my stuff that is relatively static and won’t dedupe/compress at all. For these folders I set a 10MB blocksize (could go with 1MB or something if your files are smaller) and turned compression down to 1. Not recommended for normal files as it’ll kill dedupe, but made sense given my scenario.
In the end the tested speeds are absloutely good enough for my use running backup jobs over internet and our 100Mbit connections. So I’m actually quite happy with what I got. Although running the first job to a blank backup machine, and doing that run locally, it would have been nice to see higher speeds but I’ll just let it run and take it’s time. Because if I understand it correctly it is not in any way possible to change dblock size for subsequent backup runs.
What I definitely will look closer at is your tip of having separate backup jobs for different types of data! That is brillliant! So I started thinking how I could get an overview of my data from that perspective. Maybe this should be a new thread, what do you admins say?
.
I can divide my data in to these groups:
60GB - Web server content. The bulk is 500 000 small ~150kB pictures. And some php files.
average filesize : small (100-200kB)
changes : very rare
additions : daily
dedupe : minimal
compressable : minimal
100GB - Daily VHD copies. Large VHD files with rather small daily changes within.
average filesize : very large (20-40GB)
changes : daily all
additions : no
dedupe : probably quite a bit?
compressable : minimal
400GB - Saved older VHD files. No changes but sometimes (seldom) VHD files added.
average filesize : very large (20-40GB)
changes: none
additions : rare
dedupe : probably quite a bit?
compressable : minimal
500GB - personal files on desktop, mail pst, documents, install programs, install isos. Maybe I should separate the isos…
average filesize : very mixed
changes: daily
additions : daily
dedupe : minimal (well maybe the install isos)
compressable : minimal
5TB - music collection.
files : 140 000
average filesize : large (30-40MB)
changes: rare
additions : average
dedupe : minimal
compressable : minimal
.
Now I need to find out the best backup options for these Best blocksize, compression and ability to dedupe.
Diskspace is cheap since I’ll run backup storage on my own host. So compression is mainly interesting if it lowers the amount of network traffic (and the backup run times). And balance that vs nice low cpu loads. Same with dedupe, low cpu is good, storage space is of no concern. Network traffic good if kept low.
For the Web server content i would keep the default settings.
Increasing the block size (100KB) will not help much, because most files are not larger than 1 or 2 100KB blocks.
The DBlock size does not have to be increased, 60 GB of source data, the default setting of 50MB will generate 1000-1500 DBlock files.
VHD files: I would suggest to choose a block size that is a multiple of the filesystem block size inside your VHD file. This will (hopefully) upload only changed VHD filesystem blocks if a file is added/modified inside the VHD container. Not 100% sure if this will work the same for thin provisioned VHD files and VHDX files (not sure about the file sturcture of VHD files), but I guess using this rule of thumb will not hurt.
If your NTFS partition uses a block size of 64KB, you could choose a blocksize of 64KB, 128KB, 192KB or 256KB, maybe more if you have very large VHD files.
Music collection:
I would choose to increase block size and DBlock size a bit more, for example a block size of 1MB and a DBlock size of 2GB.
I suppose chances are small that deduplication will happen (all compressed audio files), so a small block size will only result in more overhead.
A larger DBlock will result in a smaller list of files at the backend. Backdraw is that restore operations will require more data to download (Complete 2GB file if it contains a fragment of the data that must be restored), but I gues chances are small that you will need to restore 3 or 4 selected MP3’s from your collection of 140000 files.
If you want to know what approximately the results are if you changes (D)Block settings, you can use the Duplicati Storage Calculator mentioned here:
FWIW, I only have a 50Mbit connection and have been having great success with backing up to my B2 bucket with dblock sizes of 200 - 250 MB. Really the only reason I don’t go somewhat higher is in order to minimize the chances of exceeding B2’s daily free download bandwidth, for when duplicait downloads a dblock to verify.
Now all my backup jobs have run twice or more, so now I can see how much each daily update takes. All jobs but one runs very quickly, very happy about them. But the job that backs up the Hyper-V VHD image files takes over an hour to run each day so I thought maybe I could try to tweak that job to see if it can be improved. It’s no big thing if it takes an hour since there seems to be very little strain on cpu, memory or network load. But maybe the amount of data to transfer over the network could be lowered, that would be nice.
Currently I run with kees-z suggested settings: 256Kbyte block size and 50Mbyte dblock size. Some observations:
The files are thin provisioned. But they do not change in size day to day.
The changes on the disks inside the VHD’s are very small from day to day. A handful of added small files, some minor changes in logfiles/event log (it’s a mix of linux and windows boxes)
Here below under “summary” is the job log entry for the latest daily run.
Does the BackendStatistics: BytesUploaded: 3556435701 mean that the total transfer to the backup host was around three and a half gigabytes? It’s a lot considering what was actually changed in the vhd files. I wonder if this could be trimmed down by tweaking the settings? I wonder if stopping the use of thin provisioning would improve, lower, the amount of daily data transfered? There are some obvious downsides not using thin provisioning… Maybe the changes in the VHD’s are so extremely spread out all over the VHD file? Still, the percieved ratio between uploaded data size and changed data size within the VHD’s maybe seems a bit much?
I’m not very familiar with the structure of (thin provisioned) VHD/VHDX files.
Duplicati uses fixed block sizes, starting with the first byte of each file. If parts of a file change, only those changed parts are uploaded, provided that no bytes are inserted or deleted. This is why it is recommended to make the block size in Duplicati match the block size of the file system inside your VHD(X) image.
If the contents of a file shift because of inserted/deleted bytes, all blocks from this point have changed and will be re-uploaded.
I don’t know if, when using thin provisioned images, complete blocks are written to the VHD(X). If parts of blocks can be written to the VHD(X), or if compression takes place somehow, the blocks of your VHD(X) have a variable size and will go out of sync, causing all contents from the first change to be re-uploaded.
 ) directly connected network wise. 1Gbit.
) directly connected network wise. 1Gbit.