Hello everyone!
This is the second time in over two years that I take a look at Duplicati and this time around I intend to make good use of it. Generally I like the idea of deduplication based backups, in the past I also looked at Arq and similar software. So back to Duplicati and what I noticed after a day of trying it out.
Positive:
-
The UI is overall clean, simple and let’s me do what I want it to do. The advanced options are somewhat awkward to use, but as a user I am more interested in the options being present inside the UI rather than them looking pretty (instead of having to edit config files or rebuild my own code base to get there).
-
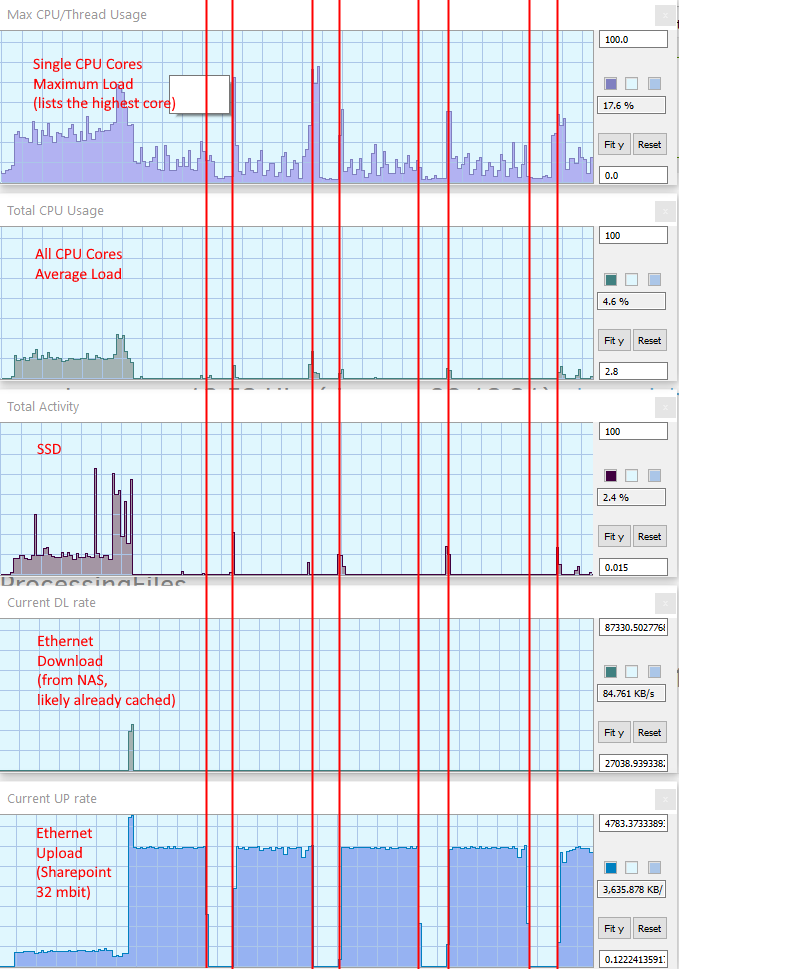
D2 is able to connect to the Office 365 German based Sharepoint server. This is somewhat special, because those German based servers differ in features compared to normal Onedrive/Office 365 servers. Even better, D2 is able to fill my full upload bandwidth of about 32 mbit (3.8 mb/s).
-
It is possible to set up file extensions for files that are not meant to be compressed, usually because they are already compressed anyway. Unfortunately this is done via editing of a config file, but better than the option not being present. I specifically checked whether this feature is case insensitive and fortunately it is (.JPG = .jpg = Jpg).
-
Compression level and even compression type (Deflate, LZMA…) is user configurable, even per backup job.
-
Compression is multi-threaded, making use of multiple CPU cores. While this might seem obvious, many (most?) image based backup programs still compress their images using only a single thread/core, thus being bottle-necked by higher compression levels.
-
Overall there is lots of user control, including such settings as chunk and block size. This is great for those of us who like to (ab)use such options.
-
User data folders in D2 properly follow folder redirection (i.e. Pictures pointing to a NAS share instead of a local folder). Local drive letters that point to network shares are also properly usable.
-
The progress bar tells me useful stuff, like the current file number, throughput (kind of) and how much data still has to be processed. The backup job gives additional information of which file is currently processed (including percentage of said file).
That is, until it does not tell me any useful stuff anymore, which brings us to
Negative:
- The quality of the progress bar information is inconsistent:
Throughput numbers of the progress bar seem mostly useless. Displaying something like 4 kb/s when real I/O throughput if over 40 mb/s.
The progress bar becomes entirely useless when “Stop after upload” is chosen (see below).
Once all files are finished being created, before the backup is finished, the remaining file size turns negative (into absurd numbers).
When “Stop now” is used then the progress bar stops showing any information of what is still going on in the background. The current batch of volumes are still created and uploads are still happening, the database is still locked, but the bar shows nothing of it.
- Graceful cancellation of an ongoing job does not seem possible:
“Stop after upload” seems useless. It keeps finishing the whole backup job, uploading all data, which may be hundreds of gigabytes taking hours and days. I would expect it to only finish uploading those files and volumes it already began working on and then do what I told it to do: stop the backup job.
“Stop now” does not stop now! As mentioned above it keeps creating some files and keeps uploading some data. It even keeps the database locked, sometimes seemingly forever, so that I have to quit Duplicate to unlock the database again. Even worse, it does not clean up after itself, leaving hundreds of megabytes of data inside the temp folder.
-
The “Pause” button is confusing and useless for ongoing backups. As a new user I kept thinking that it would pause the current backup job, but it does not. Instead it kind of pauses the Duplicati server from doing further backup jobs, but it keeps running ongoing backup jobs instead of pausing them. It told me over half a dozen times that it cannot do some “HTTP stuff”, which was solved by just clicking a second time.
-
Compression level cannot be set for compression type LZMA, which is a shame. The default level seems to correspond to 7Z using around level 3/fast. This is fine for many cases, but sometimes using level 5/normal wields considerably better results, especially when you upload a backup to the cloud with the upload bandwidth being the main culprit.
-
The list of raw image files in the compression-extension-file is too short. It should include all extensions listed in the raw image Wikipedia article.
On the other hand it should not include “.tif”, because many TIFF files are not compressed due to compatibility and performance + efficiency reasons.
Even those that are compressed are often compressed badly when created by software other than Photoshop. LZW compressed TIFF files usually can be compressed further, at least the 16 bit per color channel files that are bigger using LZW than being uncompressed. ZIP compressed TIFF files often are compressed badly by software other than Photoshop, but unfortunately these cannot be compressed further unless first being decompressed. Overall LZMA excels in compressing TIFF files (RAR being even better), but even Deflate can squeeze about 10% out of them.
- Compression does not make full use of multi-threading. The default of 8 compression “processes” (means threads?) creates around 50% total CPU load on my 9900K with 16 logical cores. Testing on a single 1.9 gb TIF file reveals that the default of 8 runs faster than using both 4 (25% load) or 16 processes (upto 80% load). Using 7Z on the same source file results in close to 100% CPU load and is considerably faster than Duplicate.
8: 1:55 min
4: >2:20 min
16: >2:10 min
7Z: 0:40 min
-
The finishing process is bottle-necked by being mostly single-threaded (1 core) only. That is when the progress bar reaches 100%, remaining data size turns negative and Duplicity seems to do some finishing touches that can take quite some time because of this CPU bottleneck.
-
During the backup process D2 takes regular brakes for several seconds when nothing seems to happen. There is no bottle-necking CPU load, no SSD load, no network traffic, nothing. This happens regardless of whether the currently progressed file is compressed or not and it happens regardless of the “use-block-cache” option.
- Damages backups cannot be repaired:
When all files of a backup are deleted, D2 only displays an error that tells me to repair the backup. When I click on Repair it does nothing but send me to the home screen. When I try to repair the database via the “Database” option it does the same thing. When I try to “Recreate (Delete + Repair)” it does not work. Only once I specifically hit “Delete” I can start over. I would at least have expected for “Recreate” to do the same thing in one click. And some better communication about errors from Duplicati’s side would be appreciated.
When a single file of a backup is deleted, D2 does the same as above! The only difference being that in the “Database” option it specifically tells me to turn on the “rebuild-missing-dblock-files” advanced option. Alas, once I do that I finally can hit the “Repair” button for something to happen. But what happens is that I get an unspecific “Error: 1” message and that’s it. No rebuilding happening despite the backup being local, from a single local source file that did not change.
- The Synology package does not seem to work at all. The server seemingly keeps crashing when I try to access the UI (connection lost). I cannot reconnect unless I close the UI windows, but then it happens within a few seconds again.
That’s all from the top of my head. Should be plenty enough to chew on anyway. 
Overall: Well done! But also: Way to go…