If that includes the entire drive with your user profile, then you probably lost the database as well.
Your data is available in default 100 KB blocks if tiny pieces will help without any reassembly map,
which would be from either dlist files or the database. There’s actually a bit of help in the dindex by
having blocklist information which can help form files you could rummage in, but names are in dlist.
Restore Backup with only dblock and dindex files was a similar dilemma, and I remembered a tool
had been made, but I had forgotten that a database was found and it used that, not the raw dindex.
It might be possible (if somebody has the time and skill) to bend an existing tool into just assigning
placeholder names to files, if it can put the files together from blocks (which would be a large help).
Do you do Python? If so, you could be the one who makes the tool you need, with some guidance.
To illustrate, I backed up a ten-block file whose blocks are identified by 32 byte hashes in a dindex.
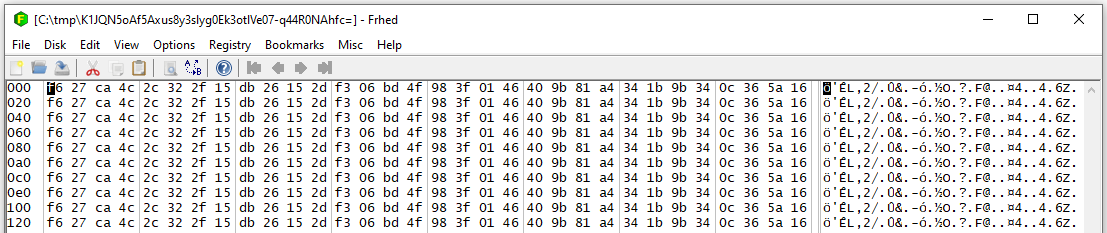
The blocks are NUL because they’re from a past test, but basically after Base64 it’s a file in dblock.
https://cryptii.com/pipes/hex-to-base64 of the SHA-256 f627ca4c2c322f15db26152df306bd4f983f0146409b81a4341b9b340c365a16
is (I’m using their RFC 4648 version which might be the right one – need something filename-safe)
9ifKTCwyLxXbJhUt8wa9T5g_AUZAm4GkNBubNAw2WhY
and here it is in the dblock .zip file:

How the restore process works section Expanding blocklists would follow. Take 10 of those blocks.
Assign some name to that file and invite the user to figure it out. If on Linux, file command will help
EDIT:
and grep can also help if you know what strings could help take you to whatever data you’re after.
If you have the space, you could unzip all the dblock files to a folder and go see what you can get.
That would be OK for single-block (default 100 KB) files. Large ones would benefit from assembly however this could be done by concatenating the blocks that you obtained from unzips of dblocks.
Duplicati Database recreate performance has more hints and a Python script if there’s a volunteer
wishing to extend it into a super-emergency recovery tool or maybe someday a blocksize changer.
Changing blocksize might start with what you need, which is extracting your existing files, however
blocksize change (which you don’t need here) would also require repackaging them into new ones.