I went through nearly all threads I could find and most are outdated, what’s the current method if one wants to use (scaleway-) glacier for backups?
-
I assume --no-backend-verification is necessary, but what about the rest, any other configs needed for duplicati to blindly trust the remote? any of the custom URLs necessary still?
-
how would one attempt a restore; say I restore it to hot-storage first, would I have to set that up as a separate remote first and then point duplicati at it? or is there better UX around this in a single entry
-
what if the local database gets deleted, can I still restore based on remote?
Thanks!
Hello and welcome.
There’s another option you’ll want to set. See my post here: Amazon Glacier Best Practices? - #6 by drwtsn32
I don’t really know how restores would work. You might need to determine which files will need to be downloaded and then change them to a higher tier at least temporarily.
If your local database gets deleted, it should be able to be rebuilt from Duplicati reading all the dlist and dindex files. In some cases Duplicati might decide it needs to read dblock files, which could be pretty painful with archive tier storage.
1 Like
thanks! those two options are all that needs to be set? or has there been more introduced since?
regarding restore, I wouldn’t mind pushing to hot-storage first, scaleway does that natively, I guess to restore I would then instead of using the config option, just point it straight at the hot-storage, makes sense!
There may be other factors, like possibly using unlimited retention to prevent Duplicati from deleting files entirely on the back end. I’m not familiar with scaleway but Amazon S3 archive tiers have a penalty if you delete a file before XX days has passed.
However, using unlimited retention has potentially negative consequences depending on how often you run your backups. The local Duplicati database will grow larger, some operations will slow down, etc., as the number of retained backup jobs grows. (Other important factors related to database performance is the deduplication block size, your total protected backup size, file count, etc.)
I don’t really understand this. Are you saying scaleway will let you repoint to a hot version of your files?
Whatever you decide I’d start with a small test backup and make sure you can do restores as expected.
I forgot about retention policy entirely, I don’t think scaleway charges for early deletion, but since I wouldn’t want it to do that anyway without me manually intervening, that’s a very good reminder, thank you!
once a day, every day; at what point would duplicati start slowing down, is that a known value of sorts? would it have to be e.g. thousands before it happens?
It allows you to move temporarily to regular / standard storage, it’ll take an unknown amount of time till first-byte but is free, not sure if they charge beyond that yet: How to restore an object from Glacier
I don’t have a good idea, myself. Some of my backups have almost 300 versions. I use a tiered retention scheme so only expect to add about 12 versions per year at this point.
As mentioned database performance is affected by a combination of factors: versions, file count, dedupe block size, etc. If you increase your dedupe block size then it should be able to handle more versions.
Personally I would choose the dedupe block size based on the size of the data you’re trying to protect, and maybe increase it further if you expect to keep a lot of versions. The dedupe block size cannot be changed after your first backup so it’s the most important thing to get right. How much data do you want to protect? The default size is 100KB which is too small for very large backups. (Note the remote volume size which defaults to 50MB is a different setting.)
1 Like
hard to say now, currently only 500GB, but it will probably grow to ~5TB of data
I’d probably err on the side of caution and set your block size to 5MB, maybe even 10MB if you want to have a lot of versions.
The main downside to increasing the block size from the default 100KB to 5MB is that it reduces deduplication efficiency. But if files don’t change much then it doesn’t really matter. The larger dedupe blocks will reduce the amount of unique blocks your database has to track.
1 Like
In case you’re interested, this is my solution to the glacier problem:
I back up all my systems to my local NAS. The NAS will sync to S3. On my S3 bucket I defined a lifecycle policy where objects larger than 80% of my remote volume size get moved to Standard-IA after 30 days, and then Glacier Deep Archive after 60 days.
The 80% thing works well (I think) because it avoids transitioning dlist and dindex files. Those files only account for a small percent of my total usage (most is in the dblock files), so moving them to glacier wouldn’t save much money anyway.
Restores will come from my NAS. S3 is only for a worst case scenario where my NAS fails completely or my house burns down, in which case I will pay the penalty to move all the objects back to hot storage for recovery.
Here are my current storage tier stats:
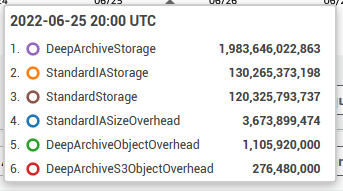
Roughly 90% of my storage is in deep archive, 5% in Standard-IA, and 5% in Standard. It is working out pretty well for having cheap, off-site copy of my backup data.
1 Like
oh so you are actually making use of the same glacier type storage, that’s great! I’ve read about this moving type rules amazon has, I’d have to investigate if scaleway has any alternative to this, or if I need to script something myself.
I also like your approach of NAS first, does that mean you have two backups setup? one locally, the other pushes to S3?
No, I only have a single backup to the NAS. Then on the NAS I use Synology Could Sync to replicate the data to S3. (rclone is another great tool for cloud sync.)
1 Like
ah you have synology take care of the replication, interesting, but yeah I suppose I could simply rclone too with a post-backup hook of sorts