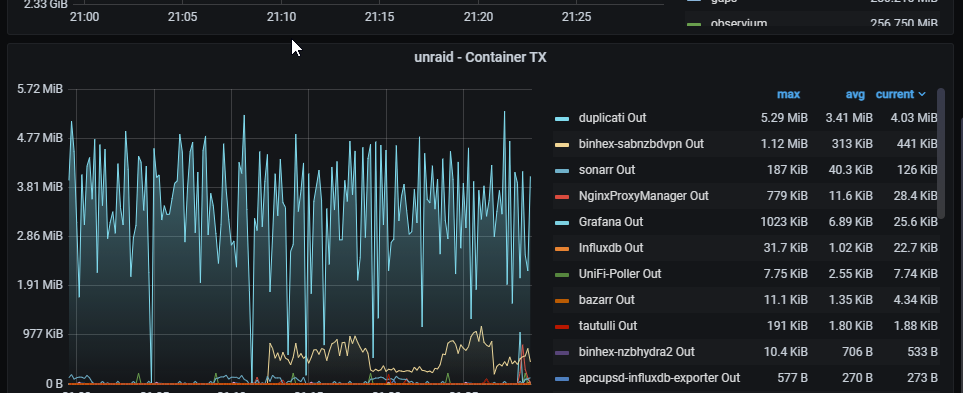
Then let’s see what Duplicati sees, to study its perspective. This is long, but at least do some of this.
Clearly I can’t observe your system, but it seems like you would be able to look at Duplicati, correct?
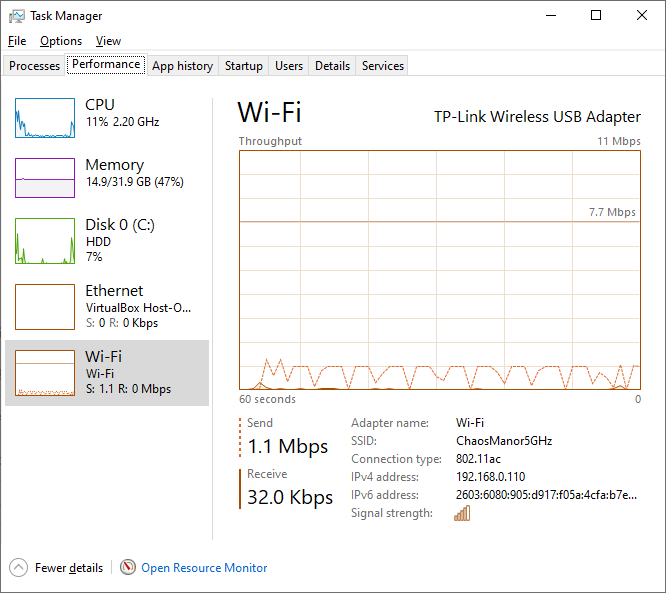
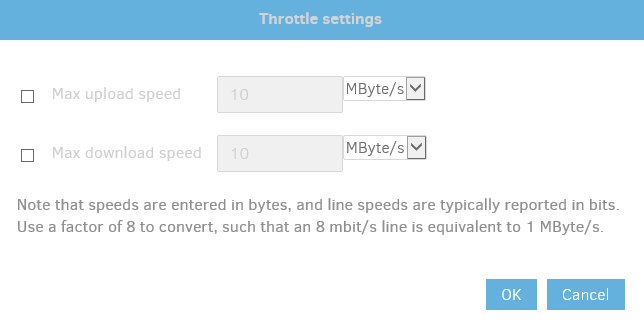
What does Duplicati’s status bar say (similar to my screenshot), is this at asynchronous-concurrent-upload-limit of 1, and which destination are you using? What happens if you change the throttle rate?
If you would rather not impact your regular backup, you can set up a test backup to do settings tests, sometime when the regular backup is not running. Note that you can still throw off the schedule, e.g. extremely low throttles may make the test job run over, which might impact the regular job start time.
Since you seem router-savvy, I’d note that smoother flows could be created by using router facilities, because that’s a router specialty. Duplicati should be able to do average rates well though. For QoS:
came at the end of a technical dive proposing a OneDrive-specific tuning option to reduce burstiness.
Ultimately the OneDrive setting sounds like it wasn’t used because the router method was doing well.
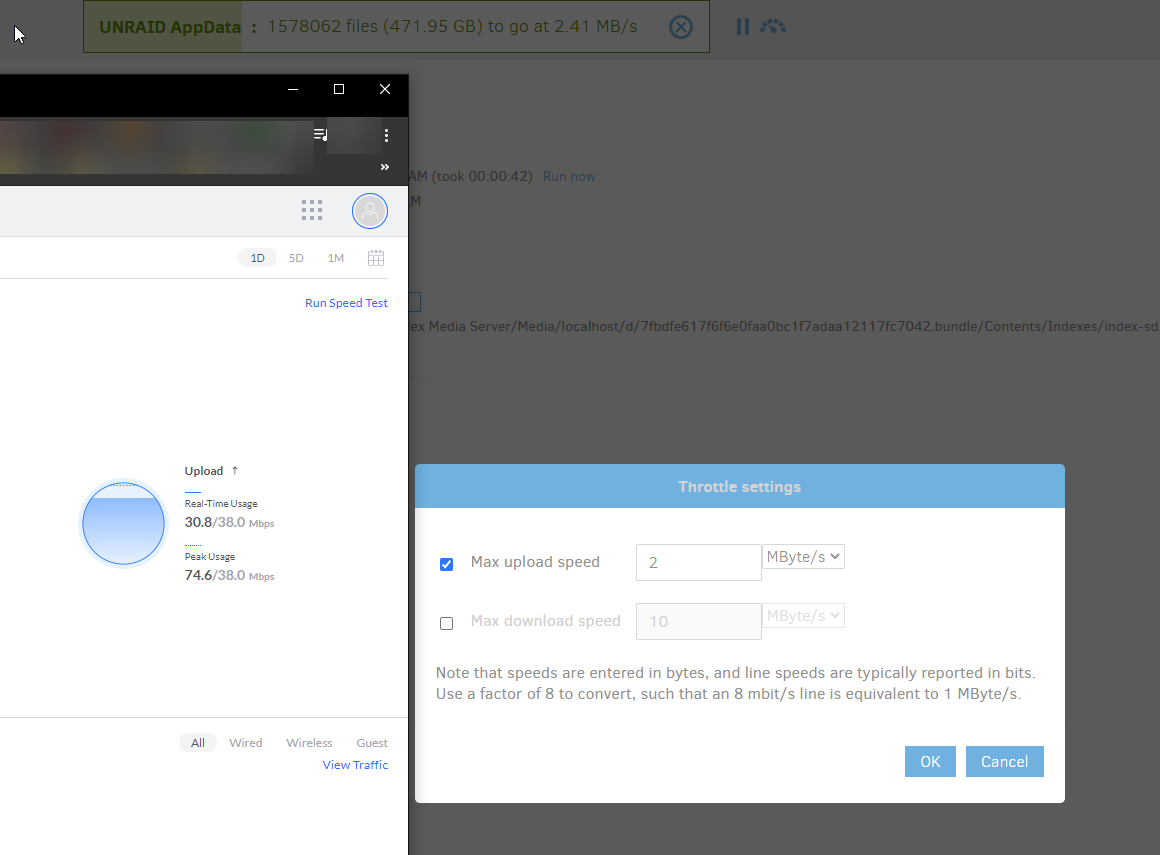
In addition to viewing the Duplicati status bar (like I showed) to see what it thinks its uploading rate is, detailed results information on whole file uploads is available in a couple of other ways. No-setup is at About → Show log → Live → Information and watch the files go up. Most interesting are large dblocks whose size is configurable in Options (Remote volume size). Watch times, see if rate is too high after setting up the other suggested options, possibly at lower values. You now asked for 2 MBytes, got 3.4, however settings questions remain. Regardless, what happens if you ask for 1 MByte? A slower rate?
Another way to see the upload information to compute a rough rate is in <job> → Show log → Remote where the dblock rate should be the main factor because the dindex files for dblocks are much smaller:
This is kind of rough and requires you to do the math, but a better reading requires looking in log file, e.g.
2021-02-13 21:23:24 -05 - [Information-Duplicati.Library.Main.BasicResults-BackendEvent]: Backend event: Put - Started: duplicati-b7c6d668bcc8b414a887d64cda47db334.dblock.zip.aes (4.92 MB)
2021-02-13 21:24:15 -05 - [Profiling-Duplicati.Library.Main.Operation.Backup.BackendUploader-UploadSpeed]: Uploaded 4.92 MB in 00:00:50.9390276, 98.81 KB/s
2021-02-13 21:24:15 -05 - [Information-Duplicati.Library.Main.BasicResults-BackendEvent]: Backend event: Put - Completed: duplicati-b7c6d668bcc8b414a887d64cda47db334.dblock.zip.aes (4.92 MB)
I was running a 5 MB remote volume size to make sure I got a good flow of dblocks with small total data.
Here, Information level time has seconds, not minutes as in live log. Doing my own math, I can compute seconds as 51, and estimate bytes as 5 * 1024 * 1024 = 5242880. 102802/second nears 100 KB target.
Options would be log-file=<path> and log-fle-log-level=information. Retry is similar but shows retry action. Profiling is huge output. You can instead use log-file-log-filter to filter interesting lines, e.g. *UploadSpeed:
2021-02-14 10:27:42 -05 - [Profiling-Duplicati.Library.Main.Operation.Backup.BackendUploader-UploadSpeed]: Uploaded 49.90 MB in 00:08:32.0315811, 99.80 KB/s
2021-02-14 10:27:43 -05 - [Profiling-Duplicati.Library.Main.Operation.Backup.BackendUploader-UploadSpeed]: Uploaded 43.06 KB in 00:00:00.8976540, 47.97 KB/s
2021-02-14 10:28:07 -05 - [Profiling-Duplicati.Library.Main.Operation.Backup.BackendUploader-UploadSpeed]: Uploaded 2.32 MB in 00:00:24.2611805, 97.93 KB/s
2021-02-14 10:28:08 -05 - [Profiling-Duplicati.Library.Main.Operation.Backup.BackendUploader-UploadSpeed]: Uploaded 22.31 KB in 00:00:01.0062725, 22.17 KB/s
2021-02-14 10:28:09 -05 - [Profiling-Duplicati.Library.Main.Operation.Backup.BackendUploader-UploadSpeed]: Uploaded 6.45 KB in 00:00:00.9460525, 6.82 KB/s
The default-size dblock got throttled down, otherwise it would have been about 700 KBytes/s on my line.
Mine is Windows 10, Google Drive, GUI throttle at 100 KBytes, and 1 concurrent upload to keep it simple.
If you’re seeing different results, let’s figure out where things went different, starting from Duplicati’s data.