I’m left feeling like I made a mistake with choosing Duplicati. I am trying to check my backups via the webUI to make sure I am not forgetting about a file inside of a folder I accidentally deleted but it’s currently at 1 hour 39 minutes as of writing and still “Fetching path information …” I can only tell it’s still working by checking ‘htop’ and seeing CPU activity from duplicati. Is there anyway to speed this up?
System
Arch Linux
Samsung Chromebox 3 running coreboot
USB 3.0 card to pci-e for external drives
mSATA SSD 512GB internal storage
Intel(R) Core™ i5-2450M CPU
16GB RAM
Hi @ShapeShifter499 that seems like an excessive amount of time for a simple search.
What size is the local database?
How many files (roughly) do you have in the database?
Is the hanging screen the initial one, or did you see some folders and then it crashed?
If you have a screenshot, that would help in pinpointing the bottleneck.
It eventually loads a list, but it is appearing to take multiple hours to sort through files.
In the WebUI, I go to home → job → operations → restore file. It will bring me to restore files but if I don’t remember the file exactly (name or otherwise) it could take a really long time to check each folder I knew it was in per backup (57 versions in my current list over two years).
Source:
2.83 TB
Backup:
11.23 TB / 57 Versions
One of the most recent successful backups in my logs shows this
I should add that it’s taking hours to load the initial list and every time I click on a folder in the list.
If this were a bare metal file system and a simple file explorer, that action would take seconds, a minute at worst on most of my computers. I feel like if all I am doing is searching up files and names it should not take hours to do so. Only when I try to restore a file should it take any significant time.
Thanks, that gives an idea. The numbers only mentions what has been processed in that backup, not the full backup number of files (I would neeed NotProcessedFiles as well to calculate total = Examined + Not processed.
For your use-case (finding a missing file) we do not currently have a great UI for that.
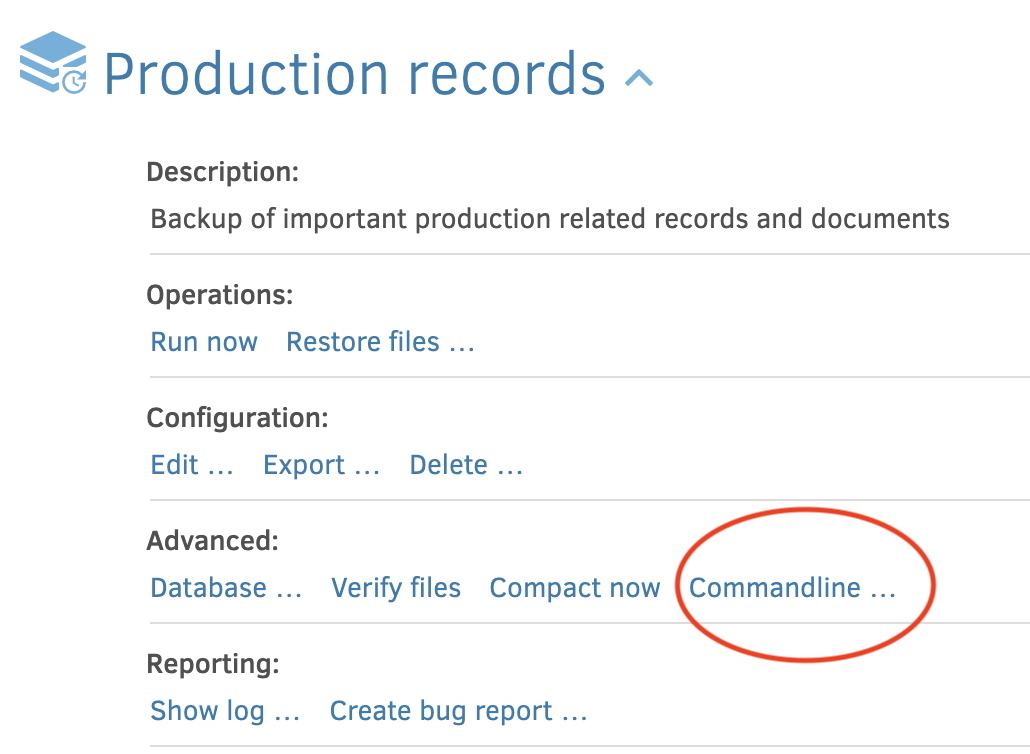
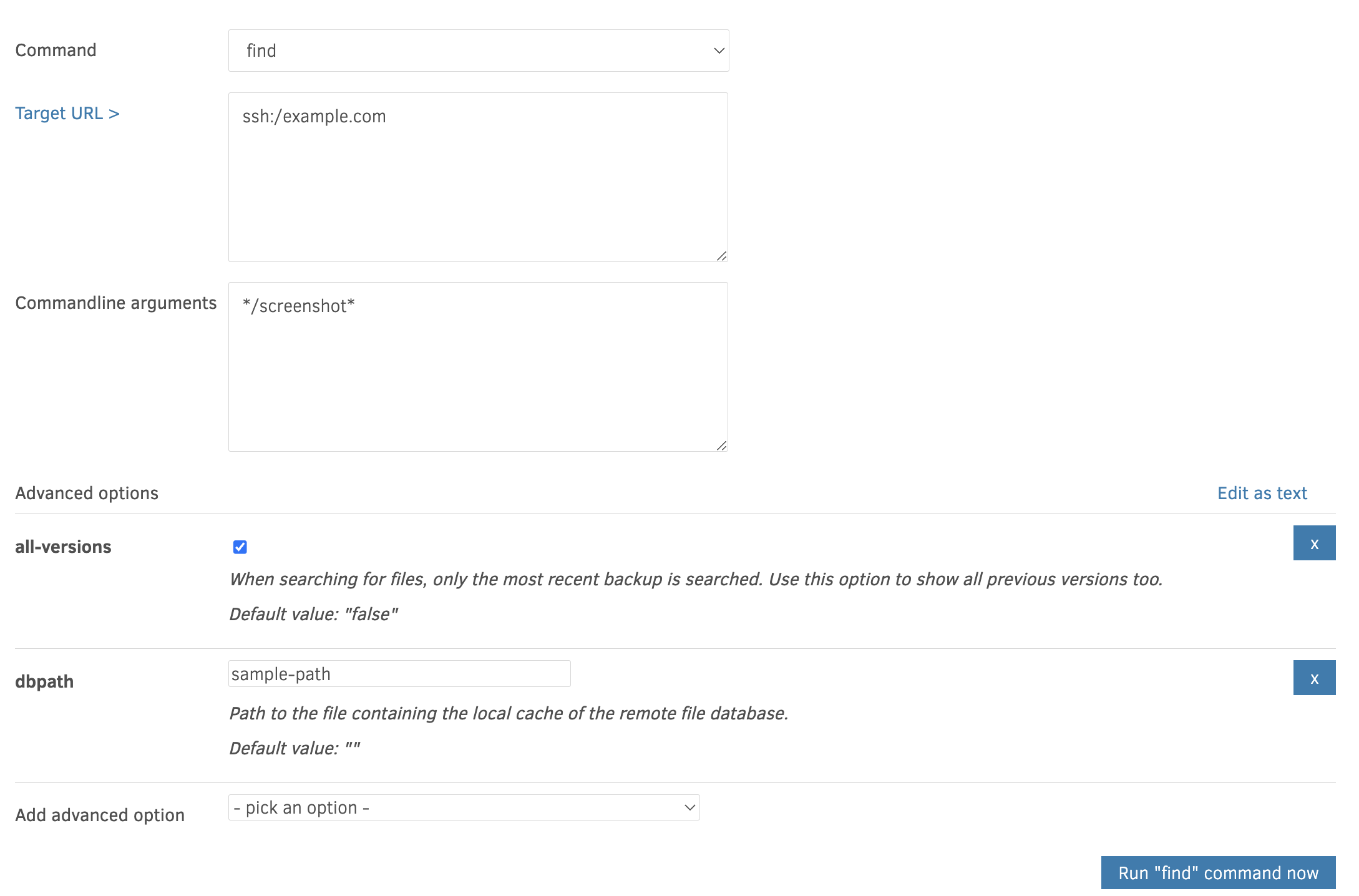
What you can do instead, is use the “commandline” feature of the UI:
In there you can choose “find” as the operation, leave the “Target URL” as-is, and then type in the filename you are looking for, with */ before and * after. Finally set the option --all-versions=true to get a search across versions:
Yes. The expression you type in as the “commandline arguments” is a filter expression, so it can match a folder as well (technically all the files in the folder are matched):
/path/to/folder/*
If you have a terminal, you may want to avoid the UI, and use the real commandline interface:
Arh, that number was 0, so the search is done with ~3million files + folders.
Thanks, that makes it easier to set up a measuring experiment for speeding up the query.
On the topic of slow and not optimized. I ran a version of that ‘find’ command shortly after posting and it’s still running right now. htop shows I/O and CPU usage. I’m not sure if it’s my older hardware but does it really need to take multiple days (possibly weeks) for this sort of ‘find’ command?
It should not, but there has been little work done to optimize this part of Duplicati. It is possible that it is buffering a hug response, if there are many files in the folder.
From the perspective of a user, waiting days for an answer is not useful.
I looked briefly at the code and it supports many complex things that just slow it down.
Once thing is using a Regex, which will revert to evaluating filters in C#, which will be a bit slow due to back-n-forth from the database.
Essentially, it is an SQLite database, so making a query for 3mil strings should take seconds, even on older hardware.
If you are familiar with SQL queries, you could also make a query into the database to locate the path prefix, and return any filenames that are in that folder. Let me know if you want to go that route, and I can assist in crafting the queries.
@kenkendk I am not kidding when I say that ‘find’ command is still on going. I’m wondering if there’s a way to restore all files under a folder with rename for files with differences or if it actuality would be any faster.
@kenkendk I’m going to give up on waiting. I can make a backup of the database to work on. What should I know to work on the database? I’m just trying to get a list of files from a folder in each version to check any deleted files.
In the “Browse Data” tab, you can find the “File” table, and there see all paths. You can filter in the top, under the column name and drill down to the files you need.
You can also use the “Execute SQL” area to write the queries directly.
To find the names of files in a folder, use this query (replace /Users/ with your prefix):
SELECT "Path" FROM "File" WHERE "BlocksetID" > 0 AND "Path" LIKE '/Users/%';
To get the timestamps of the backups where these files are in, use a query like:
SELECT "Timestamp" FROM "Fileset" WHERE "FilesetID" IN (
SELECT DISTINCT "FilesetID" FROM "FilesetEntry" WHERE "FileID" IN (
SELECT "ID" FROM "File" WHERE "BlocksetID" > 0 AND "Path" LIKE '/Users/%'));
The timestamps you get back are in Unix Epoch format, and can be converted to “normal” time with an online tool.
That “only” took 3.6 minutes. Initially I was wondering if Duplicati plans to keep (maybe it hurts performance while reducing storage use) the path prefix design.
If it’s going to stay, opening folders might be able to use it, for example like this:
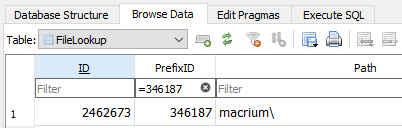
SELECT concat("C:\", Path) FROM FileLookup JOIN FilesetEntry
ON FilesetEntry.FileID = FileLookup.ID
WHERE FilesetID = 15 AND PrefixID = 2
which returns 47 files just like GUI, except it requires 362 milliseconds not an hour including the long query I’m questioning, so compare it to 3.6 minutes if you prefer.
EDIT 1:
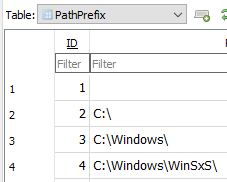
To explain that a little. Duplicati long ago got a space optimization to avoid storing complete paths for every file. Instead, it stores the first part of paths separately for reuse in an SQL view, which then may raise questions of how well it uses indexes.
For my little PoC snippet, I’ve manually picked my latest backup FilesetID which is what pops up when one goes into Restore GUI, and its root is C:\ thus ID 2 here:
Theory is any folder expansion (unlike general search) always expands a folder, therefore one could just look in the FileLookup table to see the files in the folder:
and on that note the reason I’m messing around with a 1 TB backup is to see if it potentially can avoid the need for doing an image backup to get heavy coverage.
Macrium Reflect Free (sadly discontinued) could quickly grab files from an image, though images have their own inherent issues (I think – certainly haven’t tried all).
EDIT 2:
The Duplicati query does return a little more than files, which might slow it a little:
but this was “only” a few minutes. Main slowdown is getting stats for the versions.
I’m afraid I wasn’t initially looking at the restore dropdown during initial tree filling.
It does need to know which versions are partial, so it can flag them on dropdown:
but it looks like it had already done a GET /api/v1/backup/1/filesets for that.
Question remains on whether the 52 minute statistics query serves any purpose.
is what I was testing. After looking at the code in RestoreController.js, I thought it might take less time when opening a subfolder. I clicked on boot, and got query:
which “only” took 2.9 minutes, which avoided 52 minutes more to get the initial list.
I’m unsure why your slowness with subfolders sounded similar to getting initial list.
Speed of the query does vary a bit for me, for example Windows took 4.5 minutes, however if I used my path prefix query, it’s 366 milliseconds, however that method probably doesn’t fit “Search for files” as nicely as it does to open a given subfolder.
There might be a couple of different cases, one the generalized search, but if the folder opening can be made fast, at least that might be comparable to other tools where I’d wonder if a full search is as fast – the cited “Listing directories” issue is more like opening folders, and not all reports distinguished initial from subfolders.
Since @ziesemer is also here in the forum, another data point on that might help. Using browser developer tools to look at queries is also helpful and not very hard.
The plan is to keep the prefix design, but eventually drop the “File” view.
As mentioned, we are currently investigating the recreate speed, and search performance is the next goal.
At least for listing a subfolder, it should be super fast because we can look into the prefix table and grab the id, and then extract the contents. But I think we may need to add pagination to these calls.
The issue with the search feature is that it supports too much and that makes it slow. You can search with regular expressions for example, but since the database does not support it, Duplicati will read all filenames and run the regex in C#.
A similar issue is with comparison that should be case-insensitive, as the SQLite string compare is (was?) not locale aware, adding further complexity. For Windows, this causes all queries to fall back to a slower listing.
We have not started the process yet, so I cannot promise anything, but at least cleaning up the operations will make it clear when we call something slow. This will likely cause breaking changes to the CLI.
If we cannot get the query times down enough, we also need to do some kind of polling (or websocket) to allow long-running queries.