i have a question about the SQL backup I set up. I will backup a 8 GB SQL Database who is Running at a Ms SQL Server.
My goal is that if the Server is down / destroyed i can do a complete recover of the database with the files who are stored in azure.
If i click at the restore page in dublicati i see that there is a 4GB Backup, I think this is ok. But on my onedrive i olnly see a few Files with 90 - 200mb
Is this 4GB Backup stored on the local server? Is there a Option to save a full backup at azure?
This is the first mention of OneDrive. What do you keep there, or does this mean Azure as below?
By default, there will be files up to 50 MB, however Options screen offers Remote volume size to change that. If you did, did you also read link there on what that does? It describes file design too.
A file synchronization program.
Duplicati is a block based backup solution. Files are split up in small chunks of data (blocks), which are optionally encrypted and compressed before they are sent to the backup location.
How do you know with certainty that you don’t have one? You won’t see the original file names.
Original names would show up in the Restore tree though. Have you tried restore somewhere?
Where exactly? My Restore page shows no destination or individual file sizes. Other places will.
Home page should show current destination size, which should also show in job’s Complete log.
Example:
“KnownFileSize”: 8253674056,
(and home screen is apparently using GiB even though it says GB, thus it says 7.69 not 8.25)
It should go where you specified on Destination screen. What Storage Type do you have there?
Are you doing backup with database down? Backing up the live database might be inconsistent. Probably VSS on Windows can help, but make sure to read your DB docs and test your restore.
HI, thanks for your answer. Sorry i work a lot with azure, but i mean onedrive. please delete azure and set onedrive. I want to backup the sql database to onedrive.
The reason why i ask this question is that the files at my onedrive are very small, like 200 mb. But the Database is 8Gb. Maybe this is correct. The reason why I aks is that i want to be sure that this full backup is working.,
The Database is running while i do the backup. This is a productive system so i cant stop it. Maybe create a SQL Backup .bak file and backup this file with dublicati?
The image shows 4.22 GiB, so you should have that amount of data stored in OneDrive. If you edit the backup, the last step (5) shows the remote volume size.
The local database format for an SQL database can be very sparse, so it is possible that it is compressed/deduplicated that much, but I think you should verify.
You can try the restore process and choose to restore the database to another location, and then use some kind of diff tool to check that the database file is similar to the running version.
Choose the last option and click “Next”, then find the database file(s) you want to examine, then click next again, and on the last page, choose a different place to restore it to.
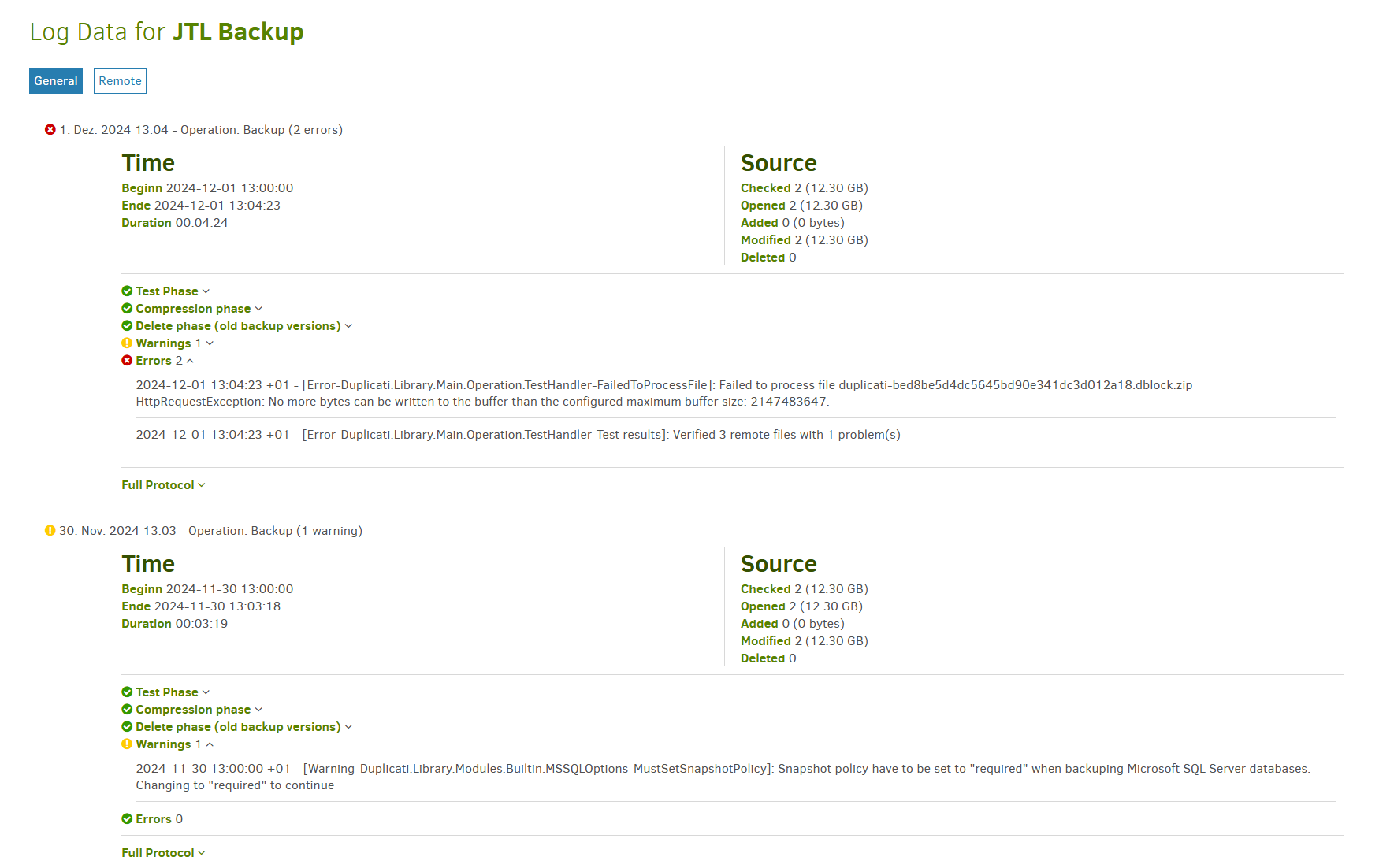
The warning message is benign, but you should edit the backup job and set the advanced option --snapshot-policy=required to make the warning go away.
There should never be any error messages, and since you get two error messages, I think something is not working correctly.
The error message about “maximum buffer size” seems to indicate that you have set a very large remote volume size.
The default value is 50 MiB, and for a ~10GiB backup, I would leave it at 50 MiB or maximum increase it to 100MiB.
How so? Isn’t lack of VSS (a.k.a. setting snapshot policy right) making an inconsistent backup?
I’m also not sure if this message comes out on Linux hosts, so I hope this is on some Windows.
You won’t get much confidence in that goal by looking at backup sizes or running diff programs.
Direct restore from backup files is what you really want, to do a full test after Duplicati gets lost. Ordinary restore won’t test Duplicati’s own database can be rebuilt, and might use Source data.
The latter policy default can be turned off if you’re on 2.0.8.1 and is reversed in the new 2.1.0.2.
Don’t you have some sort of development, test, or disaster recovery environment to do restore?
If you can get the restore attached to an SQL Server, it apparently has integrity check capability, easily found in a web search. I didn’t quickly see a good check without involving a server though.
I don’t use SQL Server. I do see it can support multiple databases, but I don’t know if the restore could be attached in some renamed way so that it can be tested without production interference.
In this case, it warns that it changes the settings to require snapshots, so it is warning that it is activating VSS, despite not being asked to do so.
Ok i was wrong at the start, did not see the 3,67GB backup file in the onedrive folder…
I will create a virtual machine for testing and restore the backup & change the advanced option in the backup to -snapshot-policy=required
One last question. I have taken the option that all backups who are older then 7 days get deleted.
So if my start backup file, the 3,67GB file is 9 Days old it is not deleted. But the files who are 8 Days old are deleted. Is this a problem that if i do a backup restore, that dublicati is missing informations?
So for example if I take the option that all updates who are older den 7 days should be deleted and i do a restore after 30 Days.
Then i have:
my 30 days old start file 3,68GB
21 Days nothing, because this files are deleted
and 7 days of tsmall backup files who are a few mb big.
Is it possible to do re restore with this scenario or is it forbidden to take the option to delete the files who are older then 7 days?
Duplicati works in “snapshot versions”, it does not care about the age of a particular file. If you delete files older than 7 days, it means that it will delete “snapshots” older than 7 days. The delete process is “safe” in that it will not delete information that is needed for any of the “snapshots” that are not yet deleted. It will also never delete the last “snapshot”.
If you run daily backups and delete older than 7 days, it means that the file versions you can restore are:
today
today - 1 day
today - 2 days
…
today - 6 days
If you only have backups for the last 7 days, you cannot restore to a version that you had 30 days ago.
I can read this two ways, so:
Deleting the large file
The setup I see here is:
Make a backup with a 3GB file
Delete the 3GB file
Run backups with no changes for 21 days
Run backups with changes for 7 days
The last 7 days will create new versions, and this will cause the 3GB file to no longer be part of any backup, and thus wasted. Most likely this will cause a compact process that will delete the remote files that are no longer needed, and you will not be able to restore the 3GB file.
Note that no changes is rare, as there are usually tiny changes to metadata etc, which would cause the 21 days to generate “snapshots” as well, making the 3GB file unavailable earlier. If you really do see backups with no changes, you may want to change the retention to keep a specific number of backups (which is a counter and not related to time).
Keeping the large file
In this version I read it as:
Make a backup with a 3 GB file
Run backups for 21 days with only deletions
Run a backup for 7 days where the 3GB file changes a bit
In this case you will be able to restore the 3GB file for the last 7 days in each of the versions. Your remote storage will only grow with the amount of data that was changed.
You can have the retention value as little as keeping just 1 backup, but it depends on your use case, what values make sense. If you have plenty of cheap remote storage, I would set it to a larger value.
This refers to backup versions. A given backup version involves various destination files.
There is no one-to-one mapping. Please see some of the list of links that I posted above.
There might be some confusion between source and destination (e.g. big OneDrive file).
Initial backup will make some files that will hang around a long time as data is still in use.
Newer backups upload new blocks. Data that still exists just references into older blocks.
Upload volumes (files at the backend) likely contain blocks that do belong to old backups only, as well as blocks that are used by newer backups. Because the contents of these volumes are partly needed, they cannot be deleted, resulting in unnecessary allocated storage capacity.
The compacting process takes care of this. When a predefined percentage of a volume is used by obsolete backups, the volume is downloaded, old blocks are removed and blocks that are still in use are recompressed and re-encrypted. The smaller volume without obsolete contents is uploaded and the original volume is deleted, freeing up storage capacity at the backend.