Has anyone asked or considered using SIA storage nodes for distributed storage for Duplicati?
I don’t work for SIA but I’m aware of what they are building…I thought adding SIA network to Duplicati would give another, perhaps much cheaper option for people to use. According to the SIA website, 1 TB of storage costs $2. 5 TB of storage will cost $10. There’s a calculator at the bottom of the page I’ve linked too.
BTW: A good way of showing your appreciation for a post is to like it: just press the button under the post.
If you asked the original question, you can also mark an answer as the accepted answer which solved your problem using the tick-box button you see under each reply.
All of this also helps the forum software distinguish interesting from less interesting posts when compiling summary emails.
Could someone explain to me how this blockchain storage works? Not the technical details but the principles and possible caveats.
The main question is obviously security and if I think of this kind of distributed storage as somehow similar to the bit torrent system, my first thought is: well, torrents do disappear if everyone deletes them from their computer (or goes offline).
And then: the torrent system builds on holding multiple copies of files but backup archives are usually much larger than most torrents. Is it feasible to multiply TB-sized backups across clients?
And finally: I understand that files are encrypted, but it also seems like everything I upload will be in the blockchain forever, which means that the encryption has to be very future proof. Very extremely future proof. Infeasibly future proof?
The answers to these questions is surely available on the web, but since the answer may be relevant for many here, I think it’s worth replicating here
Hi @tophee, I’ll admit I don’t have all the answers to your questions…but I will give you my opinions on SIA since I was the one who started this thread.
SIA is very new, but in my opinion an exciting option to decentralized storage. At first when I heard of SIA I thought it was a stupid idea…who’s going to put their important data (or any data) on various hard drives around the world. Some kid in Timbuktu could rent out his space and my files could get put there and what if his drives dies or he turns his computer off…then what. But as I looked into SIA I learned that they break my data into small pieces and save each small piece encrypted into many hard drives around the world. How many, I don’t exactly know. But the redundancy means I have less of a chance of losing my data. But you are totally right…what if everyone dumps on SIA blockchain storage, then yes all our data is lost forever. That is why I see Sia as not my primary storage…maybe not even my secondary storage. Since I’m just learning and testing SIA I’ll be putting non-critical data into SIA. For now SIA does offer me a very cheap storage solution that I would use along with my other storage solutions. Until I see Sia grow and develop into a real world competitor to the other large stable storage solutions I will not use SIA as my primary storage solution.
I’m interested enough in SIA (and really any other blockchain solution) to want to try it out, learn more about it, see how it develops and if it will develop into a real world solution. As SIA grows (if it grows), will it become faster as they claim? Will it be as secure as they say it is (I won’t be putting critical data in SIA). I will need to get comfortable with SIA and ensure that my data isn’t lost over time. What will happen when I delete a file in SIA…will it delete across all SIA nodes…I would expect it too but I’ll need to learn more.
You ask some very pertinent questions…questions that I have myself. I’m sorry if I don’t have the answers to all of them now. I’m just a very early beta tester (maybe alpha tester) of blockchain storage. I discovered Dupliati last year and I love the idea behind it. I’m also very new to Dupliati and would love to see it thrive as a backup solution. Giving Duplicati more storage options is good in my opinion. Choice is always good I think.
While initially viewing this thread the other day I somehow made my way to this blog post, which explains almost all of the questions in your post IMHO.
To me it seems like this method of storage could be pretty revolutionary - fulfilling the initial promise of decentralized distribution systems like Bittorrent but for personal backup instead.
AFAIK duplicati would (or at least should?) interact with Sia just the same as it interacts with, say, B2 - as far as Duplicat is concerned, it’s just creating its volumes and indexes as normal, and deleting them when necessary. Then Sia would take care of the storage, redundancy, etc. And if Sia’s redundancy manager is set up correctly, then it should hopefully balance things out when a particular piece loses too much redundancy - to the point that no piece should ever become unavailable altogether (since it would require every redundant datapoint to go down all at once).
My main gripe after reading some about it is the cost of entry is fairly high in terms of confusing startup steps and dealing with 2(!) different cryptocurrencies right off the bat. Compared to B2, where I just needed to create an account and go.
@drakar2007 you are right, the startup steps are a bit complicated. But will get much easier over time. We are very early on.
One of the main thing that separates us from other projects is file contracts - host and renters enter into smart-contracts that are stored on the blockchain. Renters pre-pay for storage space, and hosts pay collateral. If a host loses the data, or goes offline too often, the host loses the collateral. There’s a huge disincentive to go offline, as you’d lose a fair amount of money.
Bad hosts are automatically replaced with good hosts, and every host is scored. Our wiki goes into a ton more details. https://siawiki.tech
@kenkendk we have been trying to test the build, but it is not working for anyone. Something must have gone wrong!
I now have Sia up and running on my system, funded with a good quantity of SC (more than I really needed probably), with a few test files backed up. I just installed the latest canary build where it is supposedly working, but I’m a bit in the dark as far as to how I should be configuring it.
What should I be entering for the “Server” details? Nowhere in the SIA GUI does it tell me anything that would seem to help me on this - am I supposed to be connecting it to a single target host or something? Is there something separate (instead of the GUI) that I need to be using for this / will they be compatible? TIA
Edit: figured it out, sorry. For others who may be wondering, if you’re running the SIA gui, you’re also running the necessary daemon, and you point duplicati to localhost at the suggested port. My first test backup is going now - seems to be working so far
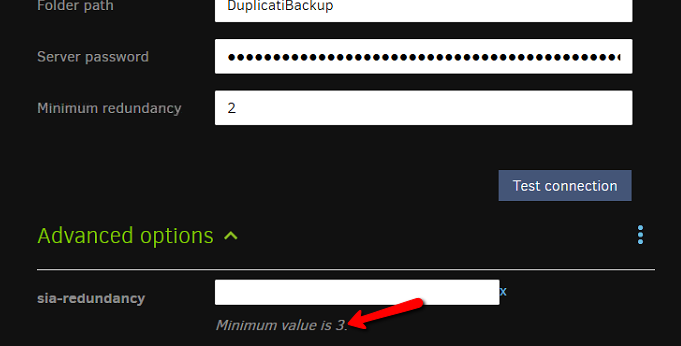
I’m about 5 GB into my first SIA backup, and something seems to be wrong with the setting for Redundancy. Initially it was set to 3 and I realized it MAJORLY delays the completion of one chunk and the start of the next chunk as it waits for the sometimes long delay between ~2.5x and 3x.
I aborted the backup job and now I have “minimum redundancy” set to 2 instead of 3, but as far as I can tell, chunks getting uploaded are still waiting until they hit 3 before moving on.
I noticed that the minimum redundancy is 2 and i think this is a big mistake. I think it should be 1x (and support decimals past that, i’m unclear whether it does) – if I understand the way this system works at all, the pieces which reach 1x will get their redundancy boosted automatically by the daemon even after Duplicati moves onto the next chunk. Someone please correct me if I’m wrong on that. But in any case, it seems to be completely ignoring the “2” setting I have set now.
Edit: by way of further testing, I just observed a single backup volume take 30 minutes to complete uploading - it was sitting at 2.9x for at least the second half of that timespan (despite the fact that I have minimum redundancy set to 2 currently).
Edit again: I’ve been waiting 45 minutes for a 245kb dindex file to finish uploading (stuck at 2.9x for 99% of the time) and out of boredom I’ve checked the advanced options on the backup config, and i notice that here it claims the minimum redundancy is 3, even though the regular option field allows it to be set as low as 2: