I seem to have messed things up this time around and can’t seem to get one backup working properly.
I reinstalled the server that is running Duplicati. I made backups before reinstalling the OS, but I missed the sqlite files which were stored in /root/, which I hadn’t included in my backups.
I did have the job exports, they are exported encrypted and stored away safely. I imported them and ran a repair. This completed succesfully for all three backup jobs.
Next morning after the scheduled runs, I have shitloads of errors of missing remote files for all three backup jobs. I wasn’t sure what to think of it, I figured maybe the repair didn’t complete so I deleted the databases and ran the recreate database for all three jobs. This time, I made sure all 3 completed succesfully, I checked the logs and I ran a manual backup afterwards. All was good to go!
Next morning, one backup is still missing remote files. 4203 to be precise. This is rediculous if you ask me but oke. I think thats everything thats in the remote but I can’t browse that s3 storage easily so Im not sure. The logs however, show no errors or warnings. So I am completely baffled why I keep getting the missing remote files.
The repair, the manual backup and the nightly backup show succeeded:
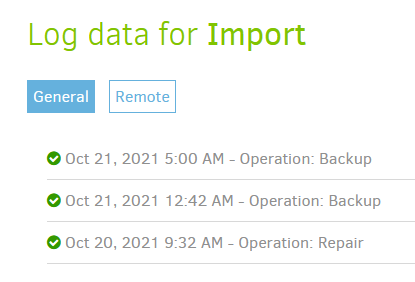
This morning, I see this (Tip: include a timestamp on that popup so we know when it occurred):
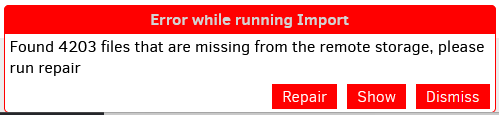
The remote log shows this:

I opened each line from last night, its HUGE, but no errors or warnings whatsoever. I can share it, but trust me all it says is a dozen or so lines of:
{"Name":"duplicati-20211004T140300Z.dlist.zip.aes","LastAccess":"2021-10-04T16:43:30+02:00","LastModification":"2021-10-04T16:43:30+02:00","Size":528637,"IsFolder":false},
{"Name":"duplicati-20211017T112545Z.dlist.zip.aes","LastAccess":"2021-10-17T13:55:53+02:00","LastModification":"2021-10-17T13:55:53+02:00","Size":545485,"IsFolder":false},
And then over 9000 lines like this (which I redacted just to be sure):
{"Name":"duplicati-blablabla1.dblock.zip.aes","LastAccess":"2021-06-14T08:20:21+02:00","LastModification":"2021-06-14T08:20:21+02:00","Size":52354637,"IsFolder":false},
{"Name":"duplicati-blablabla2.dblock.zip.aes","LastAccess":"2021-06-14T08:20:31+02:00","LastModification":"2021-06-14T08:20:31+02:00","Size":52328317,"IsFolder":false},
{"Name":"duplicati-blablabla3.dblock.zip.aes","LastAccess":"2021-09-04T15:50:57+02:00","LastModification":"2021-09-04T15:50:57+02:00","Size":52418413,"IsFolder":false},
Again, no warnings or errors anywhere. I’m not sure, but if there really were missing files, shouldn’t it mention it there?
Could it be that Duplicati is showing me an old error and that for some reason it thinks I haven’t seen that yet and keeps showing it?
So yeh, Im not sure how to proceed. Any ideas please?
Thanks!