Another possibility is that the partial temporary database for a single version doesn’t run into whatever the full database recreate ran into that makes it download dblocks. Possibly if you tried all the versions with a direct restore, you could find one that will download dblock files. You could rule out S3 by testing a similar “direct restore” of the same version over S3 instead of local file access.
I’ve got an incomplete theory on what causes dblock downloads, but to see if it fits your recreate will need you to look at your database with an SQLite viewer (or post a link to a database bug report). For example:
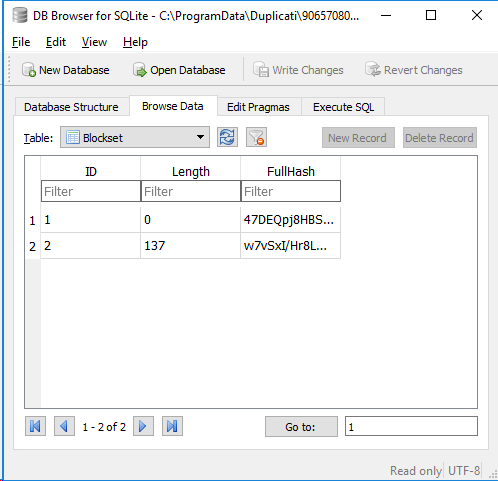
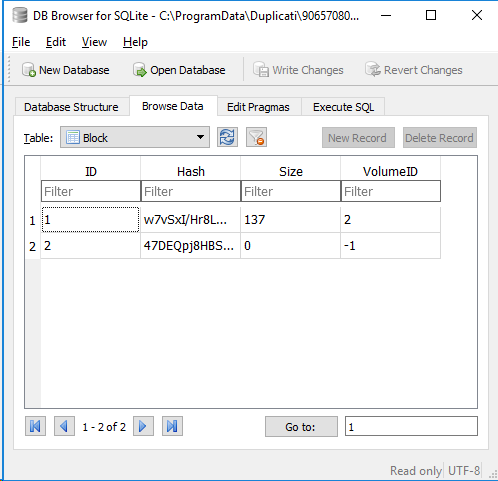
The theory is that a -1 VolumeID sometimes happens with empty files, and causes a wasted full search. Some other times, though, empty files are stored in a remote dblock volume, just as usual (just shorter).
Above sees the -1 VolumeID, decides information is missing, and just keeps on fetching all the dblocks: