I’m restoring small text files from B2. I’m moving from windows to linux. The “rebuilding database” has been running for about 12 hours. It’s moving, but it’s really really slow.
Is this normal?
I’m restoring small text files from B2. I’m moving from windows to linux. The “rebuilding database” has been running for about 12 hours. It’s moving, but it’s really really slow.
Is this normal?
I don’t know about normal, but unfortunately it’s not unheard of.
Same problem here.
My backup has about 400-500GB which should be restored from jottacloud.
CPU has a lot of IO wait:
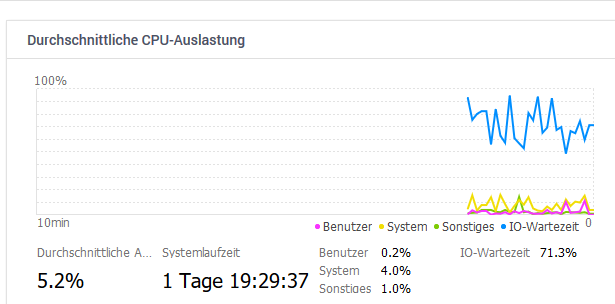
tmp folder grows slowly up
[/share/CE_CACHEDEV1_DATA/.qpkg/Duplicati/tmp] # du -hs . 881M .
Anything I can do about it?
Version is 2.0.3.5
I am now waiting since 4,5 hours
It finally took 7 hours to recreate the DB.
Now it was able to create the folders to restore
Now I get the message
[/share/CE_CACHEDEV1_DATA/Restore] # du -hs .
65M .
What the Hell is Duplicati doing here? Since 11 am my CPU is constantly in high use.
And now its running for 10 hours and it was only able to get 65MB recovered? Can anynone explain this behaviour to me?
I also have a lot of IO wait times. Why is Duplicati accessing my HDD BEFORE restoring any files?
The restore Folder was a newly created folder and I like to do a full restore.
edit:
Now it starts recovering with 1,5MB / Second and still with high cpu usage.
This means my 500GB Backup will take 5 days to recover.
next edit:
just could double my download speed by using a norwegion vpn server. Looks like the connection to my provider is not the best.
Have you tried direct restore from backup files? It should only do a partial database rebuild
It looks like they are trying to implement multithreading right now, not sure if this will help with the database rebuilding.
Larger block sizes make the database a little easier to manage, with some tradeoffs.
Unfortunately this setting can’t be changed after the first backup. It’d be great to see variable chunk sizes (e.g. using the popular buzhash algorithm)
Yes, more multi-threading came in with 2.0.3.6 canary, but it also brought in some bugs so I’d suggest not using it unless you want to help debug stuff. I doubt this multi-threading will help much with database performance, however there are some other improvements coming that should help with that.
Duplicati is doing a lot of stuff behind the scenes, so it’s possible the IO is related to tasks like:
Plus it’s possible that Duplicati is checking for usable local data before download anything. I think it essentially looks at the block hashes for your local files and if they match the database hash it will just use the block from the local file instead of downloading a whole dblock file.
You can turn this off with --no-local-blocks=true and see if that lowers the pre-restore IO.
--no-local-blocks
Duplicati will attempt to use data from source files to minimize the amount of downloaded data. Use this option to skip this optimization and only use remote data.
Default value: “false”
Thanks vor the hint but the restore folder is empty how can duplicati scan for files in this case?
I used the option and restarted the restore and still got high I/O wait times:
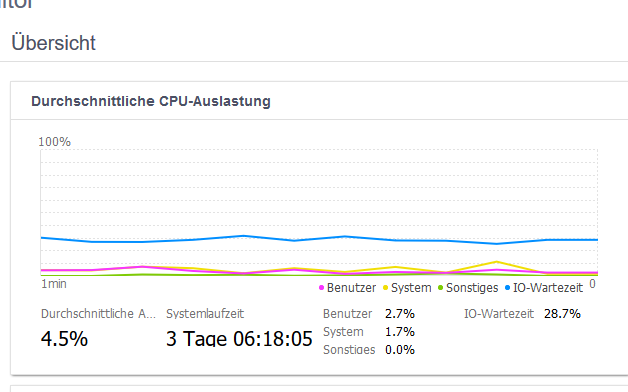
edit:
your hint did the trick! Its already downloading files now. Nevertheless I do not get the idea behind the default option. I do not know what its scanning and it also does not improve performance of a restore even if it would find something.
Next point is now that I only get 700KB/s download speed from my sftp server.
This is nothing related to duplicati because a single stream of my sftp server exactly gives that speed.
Is there any way to run several parallel downloads with duplicati and sftp?
Glad to hear it!
Not that I know of. Part of the 2.0.3.6 update was testing new multi-threading code, some of which I think supported concurrent uploads - though I don’t know if it applied to SFTP or downloads.
I downloaded the files via filezilla to the local storage with 100Mbit/s and tried to restore it, but again, it failed,. Duplicati crashed (not accesible via webgui) and not a single file was restored.
Hello, just for record, I finished rebuilding db for my big backup. It took two days
Duplciati 2.0.3.3_beta_2018-04-02
Source:741.75 GB
Backup:620.08 GB / 399 Versions
Backup data was on local \SMB share
DB file have 8GB (on SSD)
EndTime: 02.06.2018 13:57:41 (1527940661)
BeginTime: 31.05.2018 13:37:42 (1527766662)
Duration: 2.00:19:59.2417824
Rebuild database started, downloading 398 filelists,
_ Filelists restored, downloading 12464 index files,_
_ Processing required 17 blocklist volumes,_
_ Recreate completed, verifying the database consistency,_
_ Recreate completed, and consistency checks completed, marking database as complete ]_
Think that was relative fast
Only thing - I have to disable logging to text file log file was HUGE.
Heh, yeah - without any log filters it can get very big. ![]()
Two days is a pretty good time (you must have a powerful system) but hopefully we’ll be improving on that in the future. ![]()
Well, SSD (sata) maybe helps, but CPU was PassMark - Intel Xeon E5-2603 v4 @ 1.70GHz - Price performance comparison so nothing extra - performance level of modern notebooks.
And I have to set antivirus exclusion for Duplicati temp and DB folders.
But yea, two days is super time. Duplicati is great 

