I’m getting terrible performance on both a Windows 10 machine, and Windows Server 2016 NAS. Backing up anything is painfully slow. The bottleneck seems to be CPU, with one core being constantly hit hard, but with read/writes to disk and over the network being minimal. It’s taking on average a minute to do a gigabyte on either machine, regardless of whether it’s lots of little files, or a just a few larger files. I’ve turned off encryption and disabled compression, but the CPU is still being smashed and the performance is horrid.
What exactly is Duplicati doing? What’s it bottlenecking on? Even if I jack up block and volume sizes, it’s pretty much the same story. I do see that that SQLite is getting hammered, so wonder if that’s the bottleneck, but I’m not sure what;s actually being written to SQLite?
There currently isn’t a “here are the slow parts” profiling function, but the Live Log does have a profiling mode that shows pretty much everything being done and how long it takes, but it’s not pretty. Some discussion has happened around adding metrics, but so far development time has been focused on functionality.
Are you getting these 1GB/min times on initial backups, subsequent runs, or both?
As far as what Duplicati is doing, the summary is (sort of in this order):
compare list of current files to what’s already been backed up & store in a sqlite database
chop up changed / new files into blocks & record the block references in the sqlite database (while flagging records associated with deleted files as being deletable)
zip up a chunk of blocks into a dblock (archive) file
upload dblock file
repeat 2-4 as necessary
when enough deleteable entries are found, download associated dblocks and recompress without the deleted file contents, and upload them (then update the sqlite database)
when enough sparse dblock files are found (such as can result from step 7) download them and recompress into fewer non-sparse files, and upload them
This is the initial backup that’s really slow unfortunately. I’ve left it overnight and it’s managed 500GB in 8 hours. These are video files it’s backing up, so there’s no reason for it to be so slow. Copying the files manually would take about 80 minutes at the most, so duplicati is at least 7x slower than a raw copy.
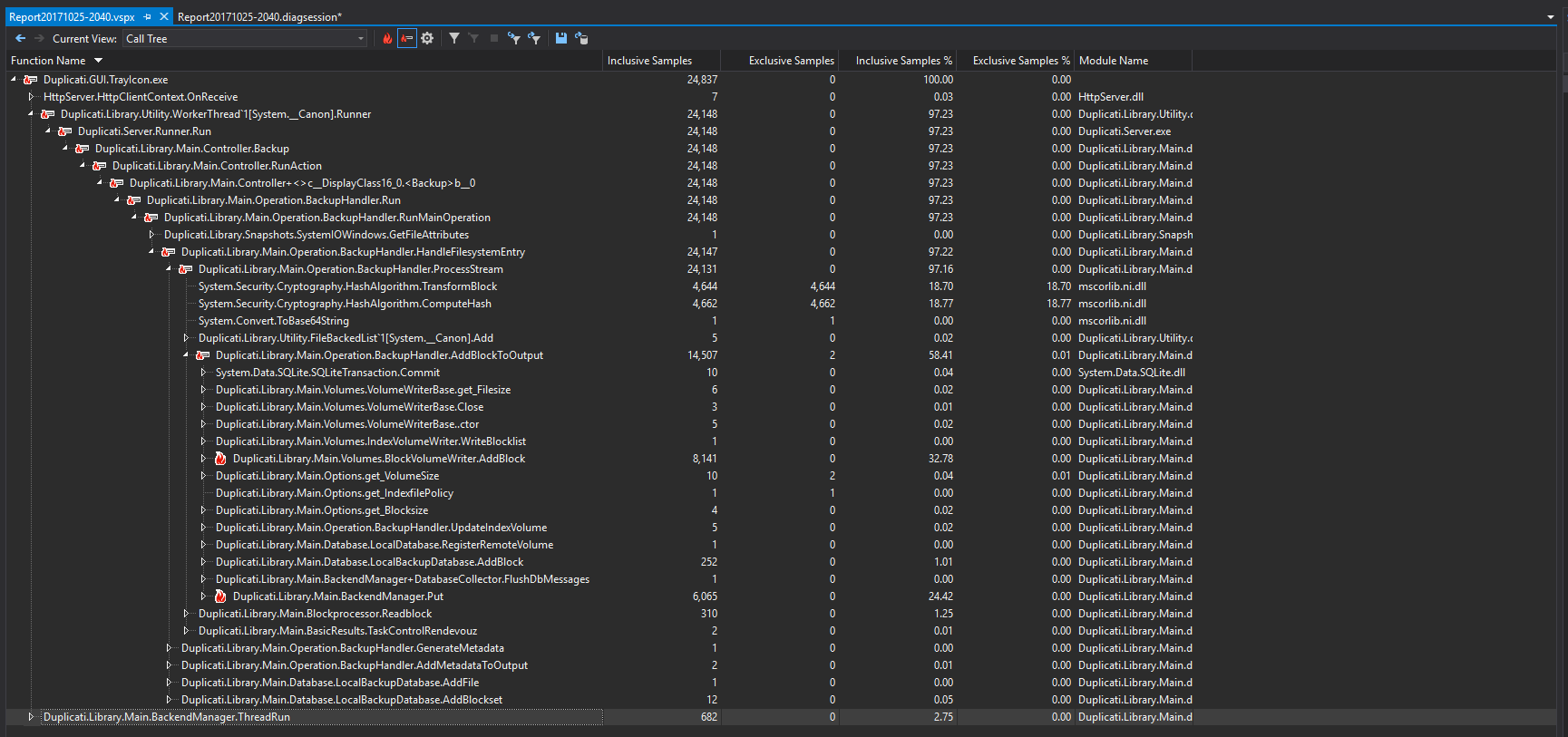
Looking at Process Explorer from Sysinternals and bringing up the stack trace on the thread generating the most CPU load, it seems the call to mscorlib.dll!System.Security.Cryptography.SHA256Managed.SHATransform is likely responsible. I plan to fire up visual studio and see if I can’t get some profiling happening.
Duplicati has lots of potential so it’s worth my time I think to delve into this one.
It sounds like the hashing of the blocks is the bottleneck you’re running into. I should have asked earlier, but what version are you running? I believe the later canary versions (2.0.2.11+, I think) have better optimized SHA code in them.
I’m running 2.0.2.1_beta_2017-08-01, which seems like it’s a few months old now. I downloaded it off the website only in the last week.
Going by profiling sample below, it’s not necessarily the hashing function, which itself is only consuming 30% of the CPU cycles, but it seems it’s rather what happens up the chain in Duplicati.Library.Main.Operation.BackupHandler.ProcessStream.
On my computer with an i7-3770k, I get about 40MB/s which is about ~2.7x less than an xcopy over my gigabit LAN. My HP Microserver with a weaker CPU fairs worse obviously, and is about twice 5x to 7x slower than it ought to be.
I’m not an expert but it looks like it’s the block processing (which is one area where Duplicati varies widely from a simple file copy) causing the issue for you.
It’s POSSIBLE the still-in-testing feature that will (where appropriate) allow moving block handing from disk into memory will address the bottlenecks your profiling highlighted.
As far as the beta seeming “stale”, that’s by design to allow people who are satisfied with it’s performance / functionally to not keep getting alerted about the relatively frequent canary updates as features like the above are added / updated.
Once enough canary functionality is finalized and tested it will be sifted over to the beta.
When I really drill into it, it works out to be 33% of CPU time spent on zip compression, and 62% spent on calculating hashes. Only ~1% of the CPU time is spent doing anything else.
I think to improve the situation, firstly, compression needs to be made optional, as that 33% spent on compression was with the compression level set to 0. Second, I think all code paths that lead to hashing need to be checked to ensure there’s no double-hashing going on (calculating a hash twice for the same data), and of course anything involving hashing needs to be done in parallel/asynchronously…
My bad, I didn’t notice you can set the compression method to “none”. Doing that boosted throughput by pretty much exactly 33% as the profiling predicted. Changing the hash algorithm from SHA256 to MD5 gave a ~15%. improvement. Combining them nearly got us to 50% overall improvement. Still not quick enough to flood my gigabit connection, certainly not on my lower spec server.
Apart from the parallel hashing, there is another speedup in the canary that uses the (terribly named) NgHash. But you can also get it to use the OpenSSL hashing library, which is faster in my tests. You need to drop in the version of the OpenSSL library you are using from here: FasterHashing/Windows-DLLs at master · kenkendk/FasterHashing · GitHub
Then set the environment variable FH_LIBRARY=openssl and it should load OpenSSL and use that for hashing.
Could you please elaborate where I’d need to drop that file?
I want to see if I can improve my backup performance.
Local backup of my home dir, ~60k files, 3.8GB in size takes ~50 minutes with C:\ being SSD to another internal HDD.
It should be “anywhere” where Windows will load dll’s from. I guess the easiest place to drop it would be in the install folder, but that does not play nice with updates. You can see what paths Windows searches in here: