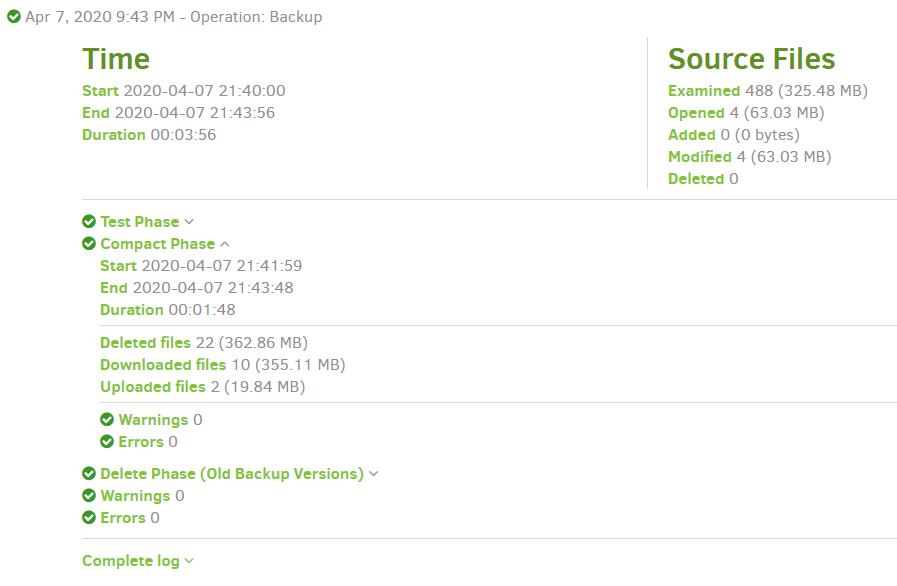
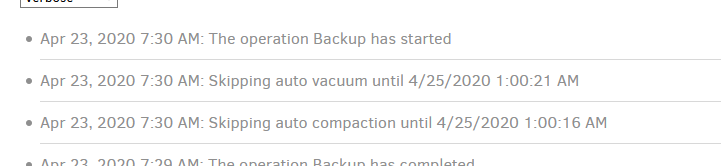
Since upgrading from 2.0.3.3 to 2.0.5.1, backup runs have extended from 7 hours each to 30+ hours (it’s on its fourth run now). The vast majority of this time is spent “Starting backup” — I haven’t yet caught the progress bar showing the backup in progress! Looking at the live profiling log, it is executing a series of queries like the below. Seeing that FileSetID and the average query runtime of 3.5 minutes, I’m guessing that the fileset number might refer to each individual historic backup run: there are 470 of them, and 470*3.5 minutes = 27 hours, which would account for the slowdown versus historic performance. Any idea what this is about? Is it avoidable?
Database has been integrity_checked, vacuumed and analyzed.
5 Mar 2020 14:40: ExecuteScalarInt64: SELECT COUNT(*) FROM (SELECT DISTINCT "Path" FROM ( SELECT "L"."Path", "L"."Lastmodified", "L"."Filelength", "L"."Filehash", "L"."Metahash", "L"."Metalength", "L"."BlocklistHash", "L"."FirstBlockHash", "L"."FirstBlockSize", "L"."FirstMetaBlockHash", "L"."FirstMetaBlockSize", "M"."Hash" AS "MetaBlocklistHash" FROM ( SELECT "J"."Path", "J"."Lastmodified", "J"."Filelength", "J"."Filehash", "J"."Metahash", "J"."Metalength", "K"."Hash" AS "BlocklistHash", "J"."FirstBlockHash", "J"."FirstBlockSize", "J"."FirstMetaBlockHash", "J"."FirstMetaBlockSize", "J"."MetablocksetID" FROM ( SELECT "A"."Path" AS "Path", "D"."Lastmodified" AS "Lastmodified", "B"."Length" AS "Filelength", "B"."FullHash" AS "Filehash", "E"."FullHash" AS "Metahash", "E"."Length" AS "Metalength", "A"."BlocksetID" AS "BlocksetID", "F"."Hash" AS "FirstBlockHash", "F"."Size" AS "FirstBlockSize", "H"."Hash" AS "FirstMetaBlockHash", "H"."Size" AS "FirstMetaBlockSize", "C"."BlocksetID" AS "MetablocksetID" FROM "File" A LEFT JOIN "Blockset" B ON "A"."BlocksetID" = "B"."ID" LEFT JOIN "Metadataset" C ON "A"."MetadataID" = "C"."ID" LEFT JOIN "FilesetEntry" D ON "A"."ID" = "D"."FileID" LEFT JOIN "Blockset" E ON "E"."ID" = "C"."BlocksetID" LEFT JOIN "BlocksetEntry" G ON "B"."ID" = "G"."BlocksetID" LEFT JOIN "Block" F ON "G"."BlockID" = "F"."ID" LEFT JOIN "BlocksetEntry" I ON "E"."ID" = "I"."BlocksetID" LEFT JOIN "Block" H ON "I"."BlockID" = "H"."ID" WHERE "A"."BlocksetId" >= 0 AND "D"."FilesetID" = 307 AND ("I"."Index" = 0 OR "I"."Index" IS NULL) AND ("G"."Index" = 0 OR "G"."Index" IS NULL) ) J LEFT OUTER JOIN "BlocklistHash" K ON "K"."BlocksetID" = "J"."BlocksetID" ORDER BY "J"."Path", "K"."Index" ) L LEFT OUTER JOIN "BlocklistHash" M ON "M"."BlocksetID" = "L"."MetablocksetID" ) UNION SELECT DISTINCT "Path" FROM ( SELECT "G"."BlocksetID", "G"."ID", "G"."Path", "G"."Length", "G"."FullHash", "G"."Lastmodified", "G"."FirstMetaBlockHash", "H"."Hash" AS "MetablocklistHash" FROM ( SELECT "B"."BlocksetID", "B"."ID", "B"."Path", "D"."Length", "D"."FullHash", "A"."Lastmodified", "F"."Hash" AS "FirstMetaBlockHash", "C"."BlocksetID" AS "MetaBlocksetID" FROM "FilesetEntry" A, "File" B, "Metadataset" C, "Blockset" D, "BlocksetEntry" E, "Block" F WHERE "A"."FileID" = "B"."ID" AND "B"."MetadataID" = "C"."ID" AND "C"."BlocksetID" = "D"."ID" AND "E"."BlocksetID" = "C"."BlocksetID" AND "E"."BlockID" = "F"."ID" AND "E"."Index" = 0 AND ("B"."BlocksetID" = -100 OR "B"."BlocksetID" = -200) AND "A"."FilesetID" = 307 ) G LEFT OUTER JOIN "BlocklistHash" H ON "H"."BlocksetID" = "G"."MetaBlocksetID" ORDER BY "G"."Path", "H"."Index" )) took 0:00:03:29.786
(Running on Synology DSM 6.2.2-24922 Update 4 and Mono 5.18.0.240-12)