That was answered earlier:
I am no developer, and I apologize if I have underestimated the complexity there. My point was that a connection timeout should be pretty straightforward to detect and report to the user, but to your point the underlying .NET may not necessarily make that easy.
Not sure if you mean our discussion above until we sighted in on the timeout, but if you do - I agree and I appreciate it very much.
Correct. I seem to be making progress, however - it is a huge back-up (280 GiB + whatever has changed since it broke) and was running quite well until some time today. I was monitoring it and I saw that with a remote volume size of 25 MiB and a 6 min. timeout it was barely making it (dblock files would finish uploading just before hitting the 6 min. mark). Eventually it failed.
I am retrying with a 20 MiB remote volume size and a 7 min. timeout, but I haven’t been able to gauge how well it’s going.
You’re getting perhaps 350 kilobits/second. Can you find an Internet speed test to see if it matches, and then see what your ISP is promising, and whether they can help? In my home, I sometimes have to reconnect my PC to Wi-Fi or restart my router or (less often) restart cable modem, and occasionally get ISP service visits.
Sometimes speeds vary with time of day (slow at busy times), packet loss slows things (try a ping test), etc. Gauging approximate network performance for the connection can be done on Windows with Task Manager.
I wish! I use a relatively cheep service and my upload speed is lower, both as promised by the ISP and in reality.
That is not the problem though - Duplicati was perfectly happy with that before switching from AWS to OneDrive and even on OneDrive before upgrading and switching to OneDrive v2. But we already discussed some of that. Plus my set-up is far from simple, so there are other factors at play as well ![]()
Anyway! I am happy to report that with an 8 min. timeout and a remote volume size of 20 MiB, I finally have my first successful real back-up for more than a month!
Thank you to everyone who responded and especially to @ts678!
The second question (the one you quoted) was answered indeed, but not the first one.
To make this clear: In order to get my Azure backup working again, I need to switch to an unstable update channel or wait until 2.0.4.6 is available for beta?
What’s wrong with your backup? I see no information anywhere. Have you followed the steps here to see whether you’re getting timeouts? If so, then somebody (perhaps me) can then go off to see how one sets larger timeouts for Azure. One challenge with timeouts is that different destination type may set differently. For example, setting an http timeout on SFTP or FTP wouldn’t make any sense. At least Azure uses http, however (just as AWS does) it has its own application programming interface (which I’m not familiar with).
Release: 2.0.4.6 (canary) 2018-12-11 is already out, and it’s canary. Numbers are not meant to be reused. If you’re just asking if you need to wait for next beta, that’s generally only an option for a fix at all if a canary or experimental (less bleeding edge than canary) has the fix. Not knowing the issue, I can’t say anything…
Well the issue I suppose is exactly the one @rumenavramov was reporting initially: I’ve had a OneDrive backup working for over a year - albeit in rather irregular schedules, the last successful one dating from December. When I wanted to let it run again recently, I first ran into the issue that apparently the OneDrive API was deprecated and needed to be changed to v2. Afterwards I got that very “channel is retired” log entry.
When I read now that this issue has been fixed in a version released two months ago, my primary question (rather than digging deep into troubleshooting) is how do I get that version without “breaking anything” (i.e. having a stable version that includes this fix). The OneDrive backup is only my 2nd copy and as I’ve said I didn’t stick to a strict schedule, so I’m well able to wait rather than switching to the canary channel that gets me a couple of other issues that need to be fixed again…
I think that might have been a misreading, but feel free to point or quote. Meanwhile, this is my view of it.
The only two months ago fix I see is the above 2.0.4.6 (Dec 11 release) one where the duplicated options were fixed by Remove duplicate connection entries from advanced options list #3511, however you rightly seem more interested in a fix for a backup failure. v2.0.4.6-2.0.4.6_canary_2018-12-11 is another change log view which is part of the series if you want to look it over yourself to see what fixes are being released. This can give you an idea of how often beta happens, and you can also see how fixes go into canary first.
Additionally, as well-covered here, “Channel is retired” means little by itself, and needs one to look for the original error. We don’t even know for sure you got timeouts. You can check as shown here. Alternatively just try the posted solution. If increasing the timeout fixes the problem, you had timeouts. You also might just know if you have unusually slow Internet, or custom settings on things like large remote volume size.
Anything other than timeouts probably deserves a new topic, where it can (hopefully) get its own solution. There is no way (to my knowledge) for a single forum post to have multiple solutions presented at the top.
It’s too bad original OneDrive is shut down at Microsoft. There’s no way to do head-to-head comparisons.
Apologies for my late reply and thank you for your patience!
My bad, you’re absolutely right - it was a misreading and the GUI issue that was fixed in 2.0.46 has got nothing to do with the problem I’m experiencing.
My line shouldn’t be a problem I think (which is the reason I’m even doing full cloud backups):
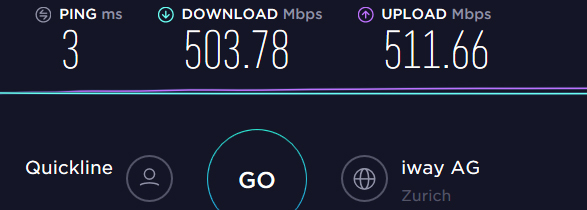
And in fact this is even a temporary restriction and I’ll be upgraded back to the full synchronous Gigabit next week :->
What could be a thing however is the volume (chunk?) size: As I’ve said I’m doing a full cloud backup which before dedupe and compression amounts to over a Terabyte, so I’ve set that size to what I think was the maximum (9 GB). May you ask the colleagues that maintain the OneDrive connection if anything changed in that matter, with the result that the timeout needs to be increased when a large volume size is used?
Thanks!
In my view this is how it ought to work. Timeouts should never be too big, or they’re not effective timeouts.
I did look on my own earlier, and didn’t spot a specific timeout setting in the old code (and we can’t test it).
Asking for historical research is awkward because the code is by different authors, and many years apart.
The v1 author is backlogged in major needs, and the v2 author (a volunteer as well) seems to be inactive. There’s also Microsoft. This is a completely different API, we have no inside info, and their old API is gone.
So what to do? As before, I suggest setting the timeout for your needs based on your actual transfer time.
which is another reason I’m reluctant to drag people into research. Can’t you just raise a timeout for now?
Although you have a fast connection, 9 GB is a huge step up from the 50 MB default. Note that a single file might have later updates spread across a series of remote volumes, so you might see a tiny file requiring hundreds of gigabytes of download to restore it. This may be a far larger remote volume size than is wise, however your fast connection does make up for it some. What’s the gain besides fewer remote volumes?
Choosing sizes in Duplicati talks about sizes. How the backup process works adds more context for that.
EDIT: Having a larger –blocksize (such as 1 MB) could be good for large backups to reduce block tracking overhead in the database (default is 100 KB) but I’m unsure what a huge –dblock-size offers that’s helpful.
I know this topic is a tad old now, however I had the same issue and Duplicati’s error messages were not useful, after finding this topic I realized my backups only broke after I moved house and my upload became 1/10 of what it was.
So anyone that is here from Google.
Try reducing your block size. Especially with backups to OneDrive.
Also for anyone else troubleshooting this, while attempting to fix this I also saw the following error messages which all lead back to Duplicati being unable to write to the destination.
- “System.NullReferenceException: Object reference not set to an instance of an object.”
- “Expected there to be a temporary fileset for synthetic filelist”
- “Unexpected difference in fileset”
I gave up on OneDrive completely!
Dulicati’s current implementation simply does not work well enough with it.